# 数据导入
本文档介绍如何在 ROM Builder 工具箱中导入不同类型的数据文件,包括系统数据文件和场数据文件。数据导入是模型训练的基础,正确的数据导入和预处理直接影响模型的训练效果和预测精度。
数据导入支持系统数据文件和场数据文件,在创建项目时选择不同的数据格式,数据导入则支持对应类型文件。
系统数据文件:
- 支持
.csv、.txt等格式文件 - 适用于结构化变量数据
- 适合代数/微分方程建模
场数据文件:
- 支持
.case格式文件以及.csv形式的数据文件 - 适用于空间分布型变量数据
- 适合偏微分方程建模
提示
选择正确的数据格式是成功导入数据的前提,建议在导入前仔细检查数据文件的格式是否符合工具箱要求。
# 静态模型系统数据导入
# 导入操作步骤
- 单击数据管理,接着单击导入按钮,进入数据导入窗口。
- 单击导入数据,找到文件路径,并选择需要导入的数据文件,单击打开。
- 最后单击导入完成数据导入。
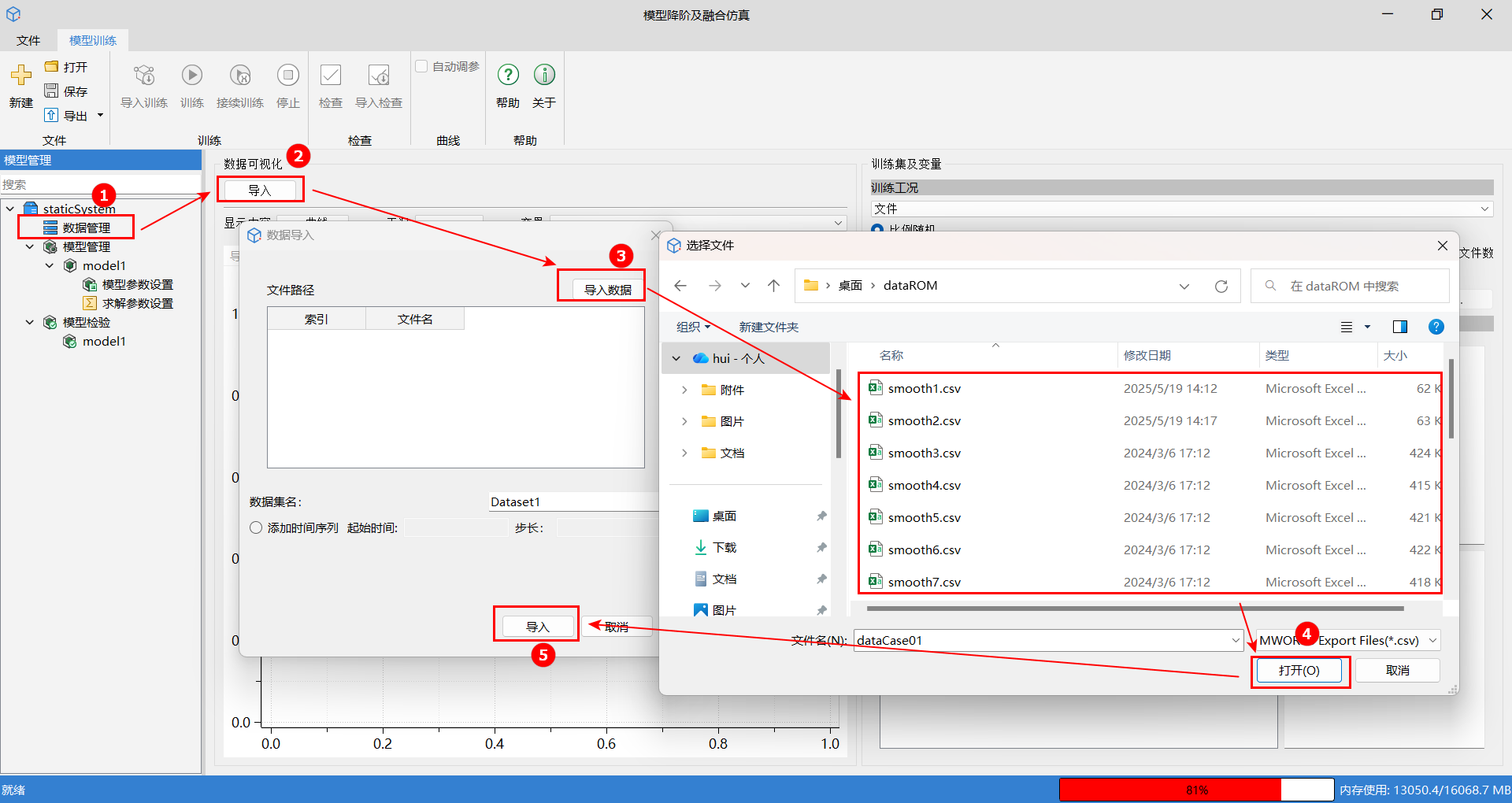
# 数据文件格式选择
在选择数据文件的时候,可以选择数据文件格式。
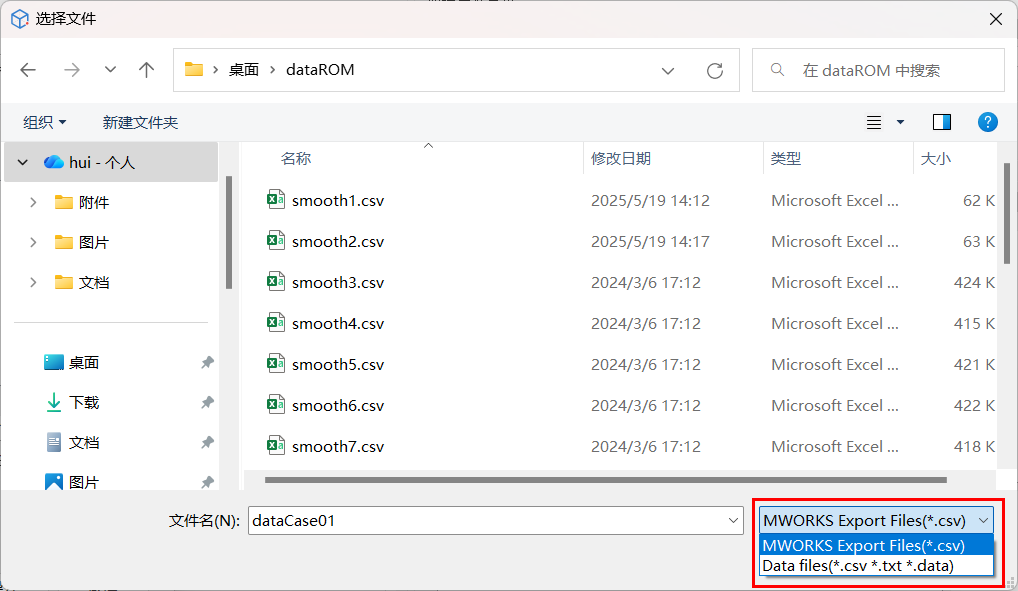
# Data files 格式
导入数据文件格式支持 .csv、.data、.txt 格式,单个系统变量文件数据格式如下:
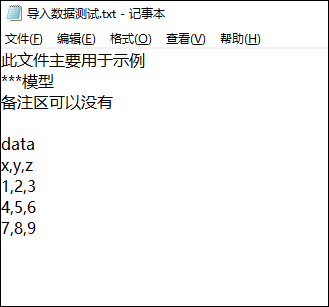
文件结构说明:
- 备注区:范围为 0~data 行,可用于记录此文件的相关备注信息,用户也可以自定义是否有备注区。
- 变量区:data 行至文件末尾为变量区,其中变量区第二行为变量名,例如下图中的 x、y、z。
- 数据类型:变量数据类型均按 double 型处理。
- 分隔符:支持变量之间用","、" "、"Tab"分隔,多个连续空格按单个空格处理,但不支持混用。
- 空行限制:变量区不能含有空行。
提示
Data files 格式适用于从其他软件导出的数据,建议在导入前检查数据格式是否符合要求,特别是分隔符的使用要统一。
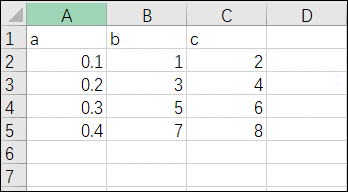
# MWORKS Export Files 格式
从 Sysplorer 仿真结果直接导出的数据文件可以直接导入 ROM Builder 工具箱。
格式特点:
- 导出文件的第一行为数据的变量名
- 自动匹配 Sysplorer 的仿真结果格式
- 支持批量导入多个工况数据
提示
MWORKS Export Files 格式是最便捷的数据导入方式,建议优先使用此格式,避免格式转换带来的错误。
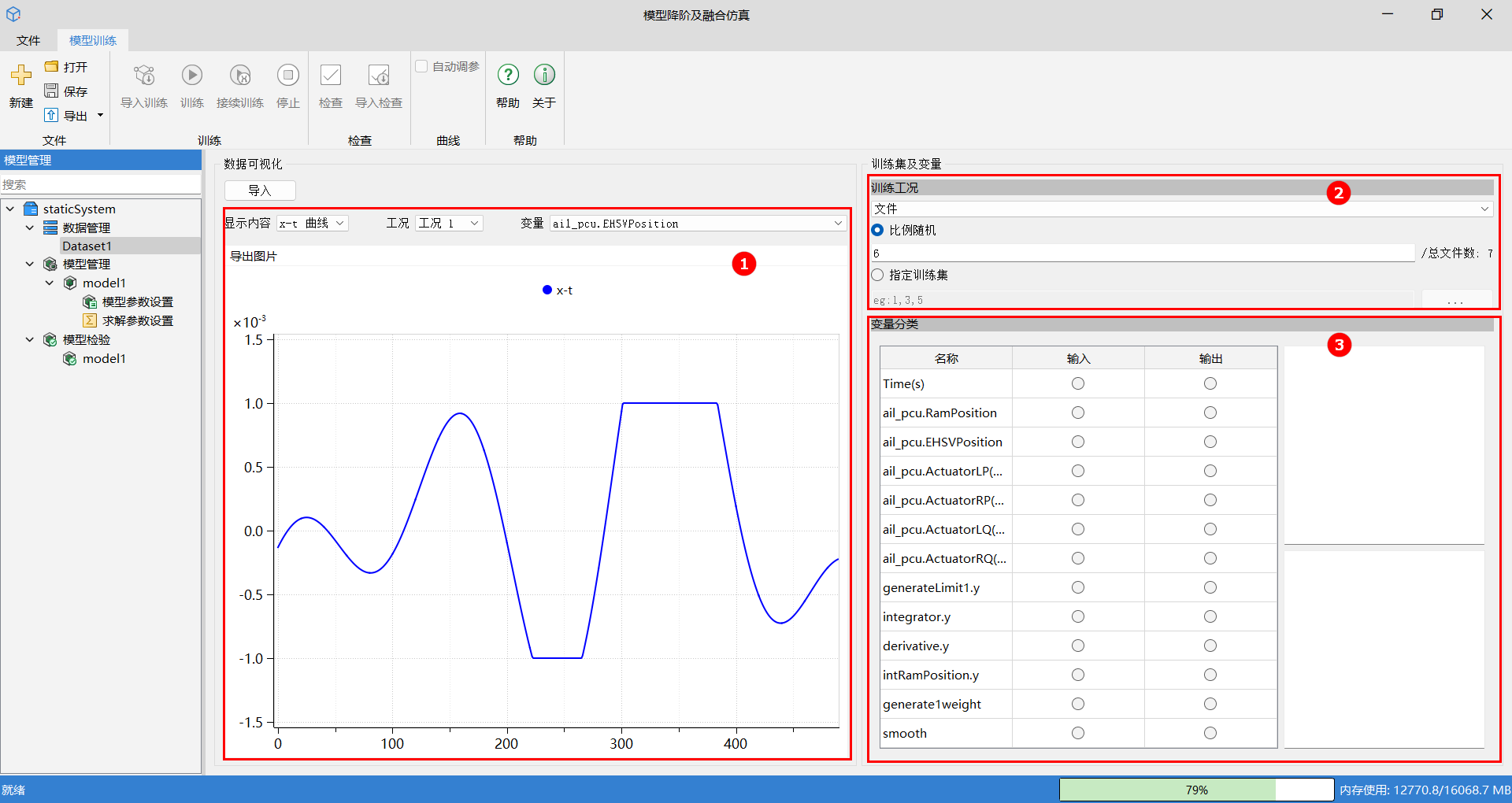
# 导入后界面说明
导入数据文件后的界面如下所示。
# 数据曲线显示
在显示内容下拉栏中选择 x - t 曲线或者 x - y 曲线,在工况下拉栏中选择工况序号,在变量下拉栏中选择要显示的变量名称,即可在导出图片窗口显示变量图片。
显示功能:
- x - t 曲线:显示变量随时间的变化趋势,适用于动态数据分析。
- x - y 曲线:显示两个变量之间的关系,适用于相关性分析。
- 工况选择:支持切换工况查看。
- 变量选择:支持切换变量显示。
提示
数据可视化是数据质量检查的重要手段,建议在导入后通过曲线显示检查数据的完整性和合理性。
# 训练工况设置
训练对象选择: 包含数据和文件两种数据集划分对象,在下拉栏中可以选择数据集划分对象种类。
- 数据划分:所有工况中的数据被提取出来,以数据为单位,进行训练集和验证集的划分。
- 文件划分:以工况为单位,进行训练集和验证集的划分。

参数说明:
- 划分对象(数据/文件):
- 原理:决定数据集划分的粒度,影响训练集和验证集的分布特性。
- 效果:按数据划分适合样本量大且分布均匀,按文件划分适合工况间差异明显的情况。
- 建议:对于工况差异明显的系统,选择文件划分;对于样本量充足且分布均匀的系统,选择数据划分。
数据集划分: 抽取固定比例的输出文件与对应的输入条件作为训练集,剩余为验证集。包含比例随机划分和指定训练集划分。
- 比例随机划分:随机抽取 80%(默认值,可修改)的划分对象作为训练集,其余划分对象作为验证集。
- 指定训练集划分:单击右侧按钮,在文件信息窗口中选择训练集工况,单击确认。
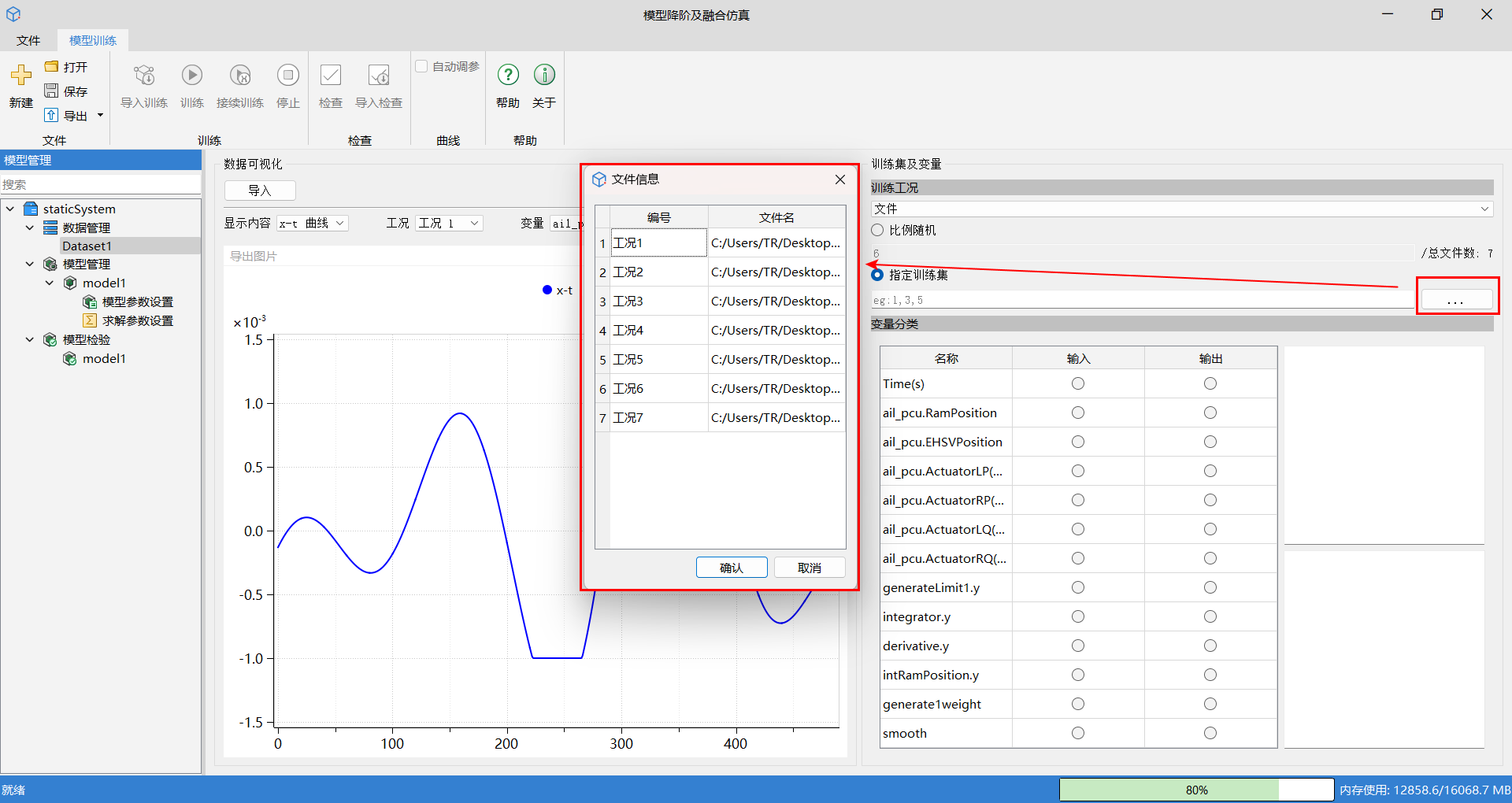
参数说明:
划分比例(默认为 80%):
- 原理:决定训练集与验证集的样本数量,影响模型拟合能力和泛化能力评估。
- 效果:比例越高,训练集样本越多,模型拟合能力越强,但验证集样本减少,泛化能力评估可能不足。
- 建议:通常设置为 70%-80%,根据数据规模和模型复杂度调整。
指定训练集:
- 原理:手动选择特定工况作为训练集,确保关键工况包含在训练集中。
- 效果:适用于有代表性或特殊工况需重点训练的场景,避免重要工况被随机划分到验证集。
- 建议:当某些工况特别重要或具有代表性时,使用指定训练集功能。
# 变量分类
勾选输入输出变量,如果该数据没有用到,则选择未使用。
参数说明:
输入变量:
- 原理:作为模型的自变量,决定模型的输入空间,是模型预测的基础。
- 效果:输入变量的选择直接影响模型的预测能力和泛化性能。
- 建议:选择对系统输出有显著影响的变量,避免选择冗余或相关性过高的变量。
输出变量:
- 原理:作为模型的因变量,决定模型的预测目标,是模型训练的优化对象。
- 效果:输出变量的选择决定了模型的预测范围和应用场景。
- 建议:选择需要预测的关键物理量,支持同时选择多个输出变量。
提示
变量选择是数据导入的关键步骤,建议结合领域知识和统计分析,选择最具代表性和预测能力的变量组合。
# 数据预处理
在变量列选中变量名称,右击后可以对变量进行复制、删除、重命名和增加特征项。如果对数据进行增加特征项操作,新增的变量将会展示在变量窗口最下面。
除通过增加特征项为数据添加预处理算法外,还支持对预测特征进行权重设置,用于调整不同预测特征在建模中的作用程度。
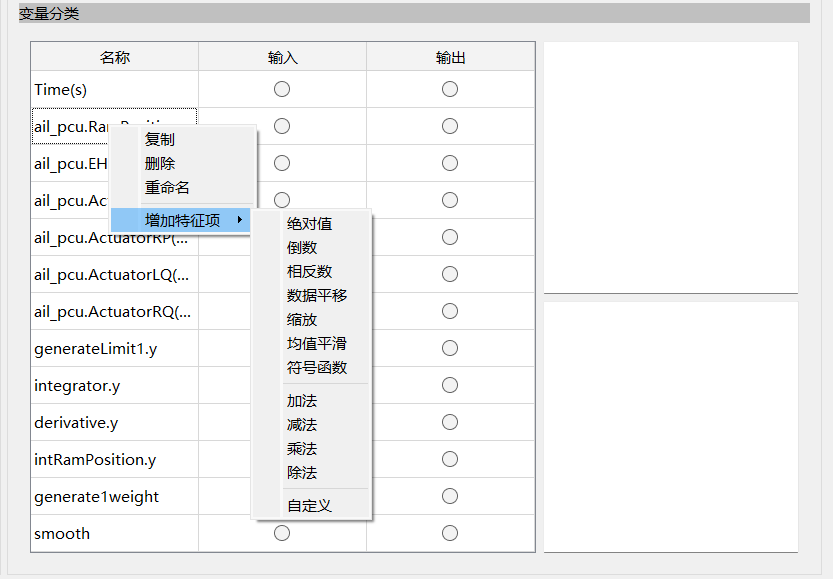
数据预处理功能:
- 积分:计算变量的积分曲线(仅支持动态模型)
- 微分:计算变量的微分曲线(仅支持动态模型)
- 绝对值:获取变量的绝对值
- 倒数:获取变量的倒数
- 相反数:获取变量的相反数
- 数据平移:为变量加上固定偏移量
- 缩放:为变量乘以固定系数
- 均值平滑:对变量进行均值滤波
- 符号函数:将变量映射为符号值
- 加法:选择两个变量进行加法计算
- 减法:选择两个变量进行减法计算
- 乘法:选择两个变量进行乘法计算
- 除法:选择两个变量进行除法计算
- 自定义:对变量进行自定义公式计算
详细说明: 数据预处理的详细原理、效果和适用场景,请参考相关原理介绍中的数据预处理章节。
提示
数据预处理是提升模型性能的关键步骤,建议根据数据特性和建模目标选择合适的预处理方法。预处理过程中要注意保持数据的物理意义和合理性。
# 动态模型系统数据导入
# 导入操作步骤
- 单击数据管理,接着单击导入按钮,进入数据导入窗口。
- 单击导入数据,找到文件路径,并选择需要导入的数据文件,单击打开。
- 最后单击导入完成数据导入。
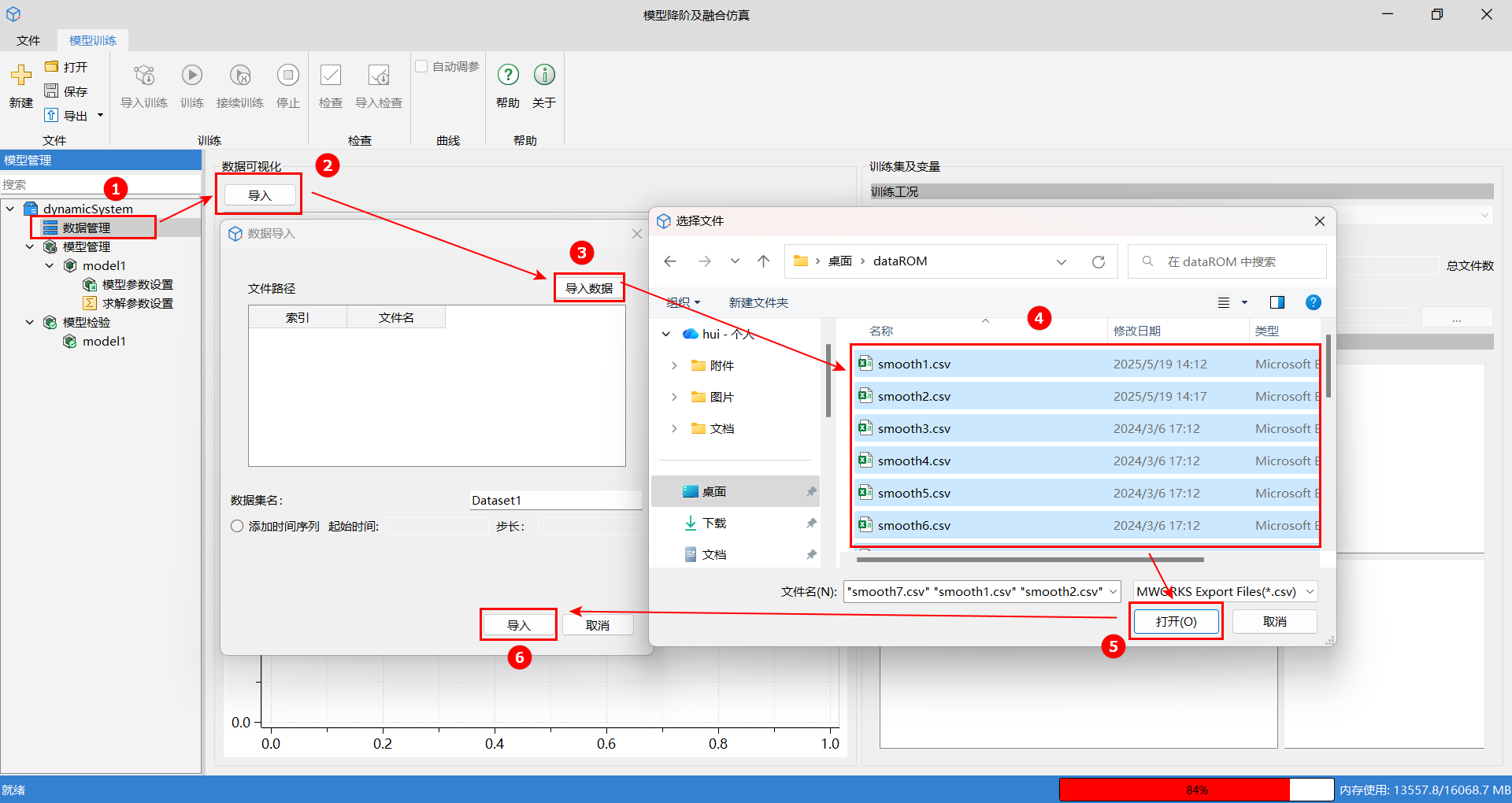
# 时间信息设置
导入完成后,可以选择设置数据时间信息:起始时间、步长,可在数据集中自动添加时间序列。
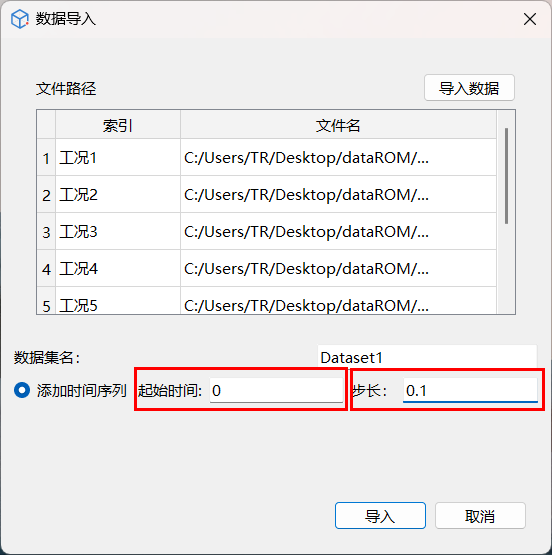
参数说明:
起始时间:
- 原理:时间序列数据的起始时刻,决定时间轴的零点。
- 效果:影响时间轴的显示和后续仿真时间的对应关系。
- 建议:通常设置为 0 或实际物理时间的起始值。
步长:
- 原理:时间序列数据的时间间隔,决定数据的时间分辨率。
- 效果:影响动态模型的时序建模精度和计算效率。
- 建议:与原始数据采样间隔保持一致,避免信息损失或过度插值。
# 其他设置
用户完成导入数据后,可以设置数据集划分对象,选择数据集划分方式,设置输入变量和输出变量,并对变量进行数据预处理,该过程参照静态模型系统数据导入章节。
# 静态模型场数据导入
对于场数据文件的导入,目前支持 .case 以及 .csv 两种数据格式,本章节介绍静态模型场变量数据集成情况,其中在导入数据需要对应的输入文件,以下做详细说明。
# 文件格式说明
# 输入文件格式说明
输入文件为一个 csv 文件(或 txt 文件),csv 文件中每一行表示所对应稳态工况的输入。
文件结构:
- 第一行:关键字"data"
- 第二行:变量名称
- 第三行开始:每个工况的输入值
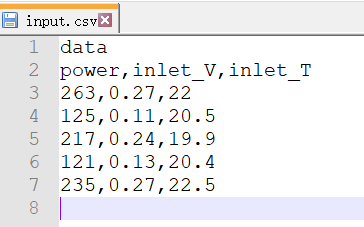
提示
输入文件的每一行对应一个稳态工况,确保输入文件与输出文件的工况数量和顺序一致。
# 输出文件格式说明
case 场数据格式说明:
对于通用类型的 .case 场数据文件,包括信息索引 .case、几何文件 .geo 和变量文件 .variable 这样一组文件构成一个完整的输出工况,并且与输入条件文件中相应的输入保持对应,将该信息索引 .case、几何文件 .geo 和变量文件 .variable 放入一个文件夹中,一个文件夹就代表一个工况。
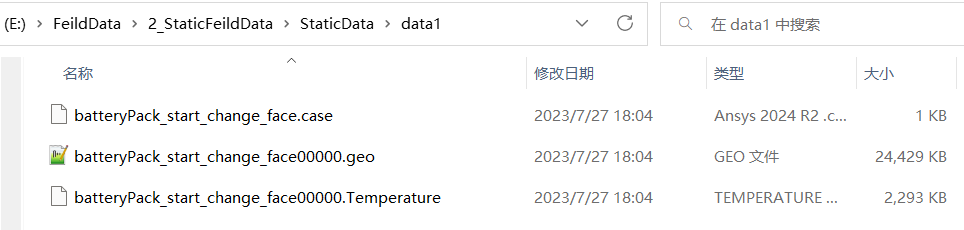
文件组成说明:
- .case 文件:信息索引文件,包含工况的基本信息和文件引用关系。
- .geo 文件:几何文件,包含网格的几何信息和拓扑结构。
- .variable 文件:变量文件,包含场变量在网格节点上的数值。
无网格拓扑场数据格式说明:
对于无网格拓扑场数据(即 csv 形式),是将场数据的网格点坐标以及变量值直接按列存储在 csv 文件中,每个稳态的所有变量值存储在一个 csv 文件中,每个工况的所有时间步数据存储在一个文件夹内,为一个工况,对静态场而言,每个工况仅有一个稳态时间步。
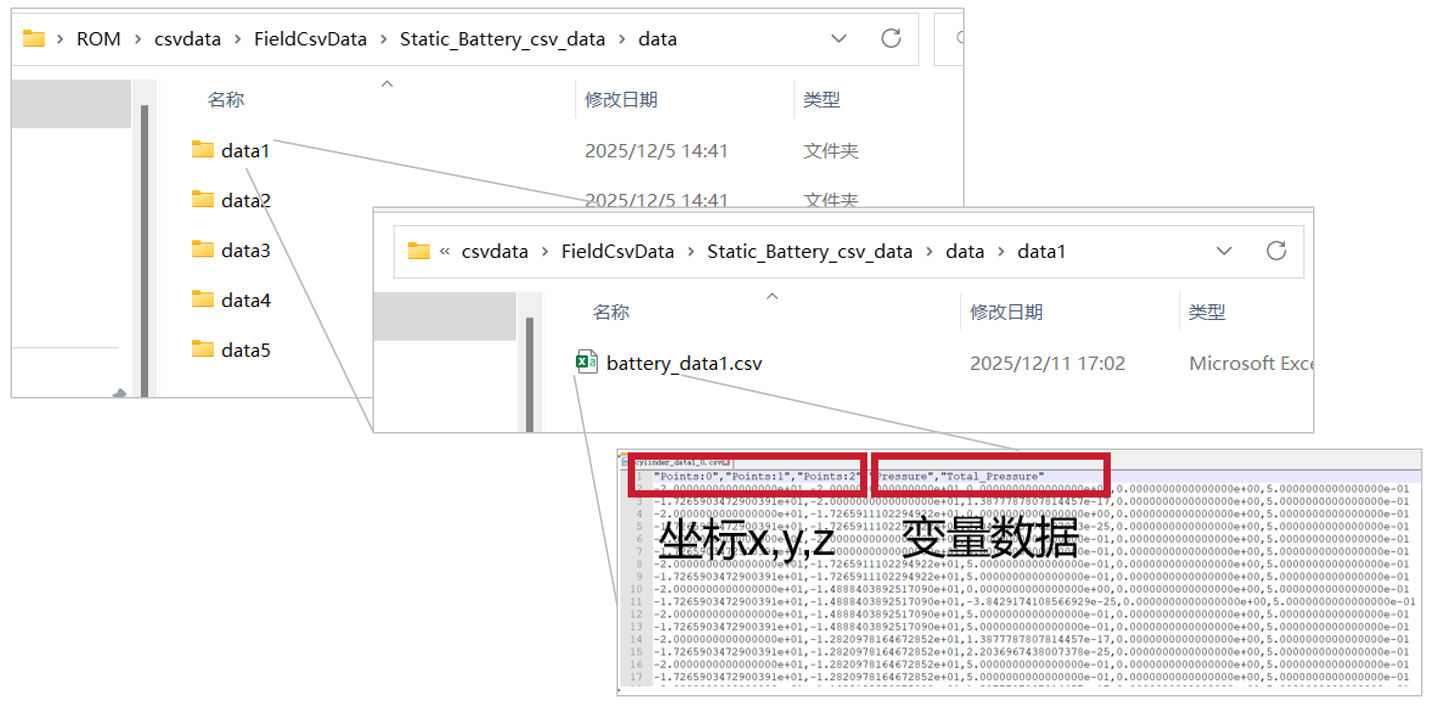
文件格式要求: 每个稳态时间步的 csv 文件中包含表头与数据两部分,所存储数据中必须包含网格点的 x, y, z 坐标数据,否则将无法导入。
- 表头:第一行记录变量名,其中坐标变量名,需要设置为以下四种形式之一,否则无法判断,工具箱无法导入。
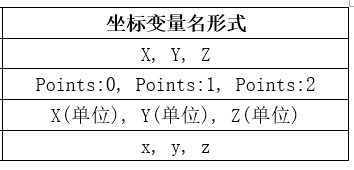
- 数据:数据按列存储即可,每列需要保持长度一致。
提示
无网格拓扑数据格式适用于简单几何或自定义网格的情况,但要确保坐标变量名格式正确,否则无法导入。
# 操作流程
导入静态场数据的操作如下:
单击数据管理,接着单击导入按钮,在数据导入窗口,找到输入文件路径,单击数据导入,在场数据的相关路径下找到输入文件路径,单击打开。
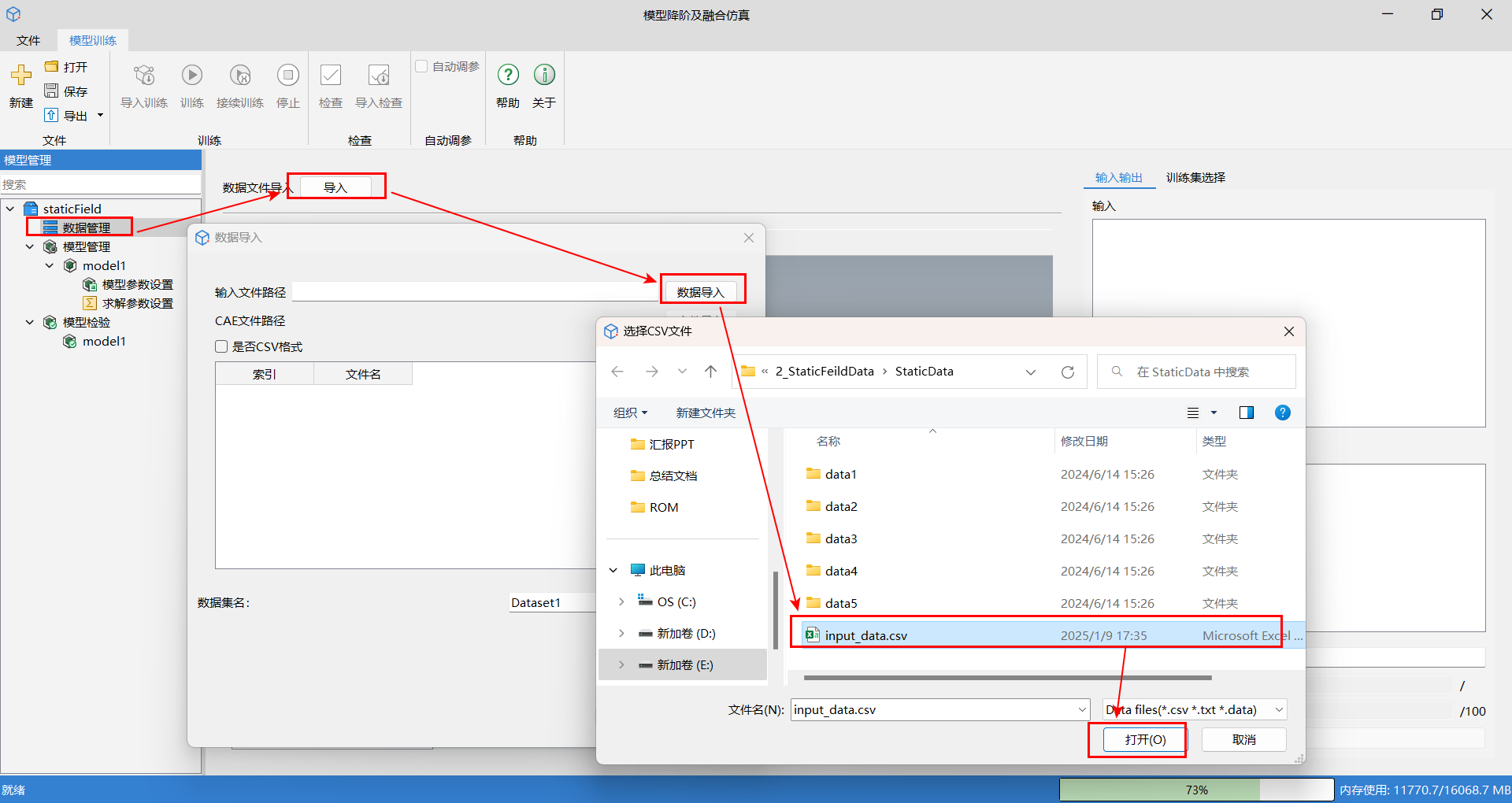
场变量文件路径为包含所有单个工况文件夹的上一级目录位置。在数据导入窗口中的 CAE 文件路径中,单击文件导入,选择 CAE 文件,单击选择,最后单击数据导入窗口中的导入。
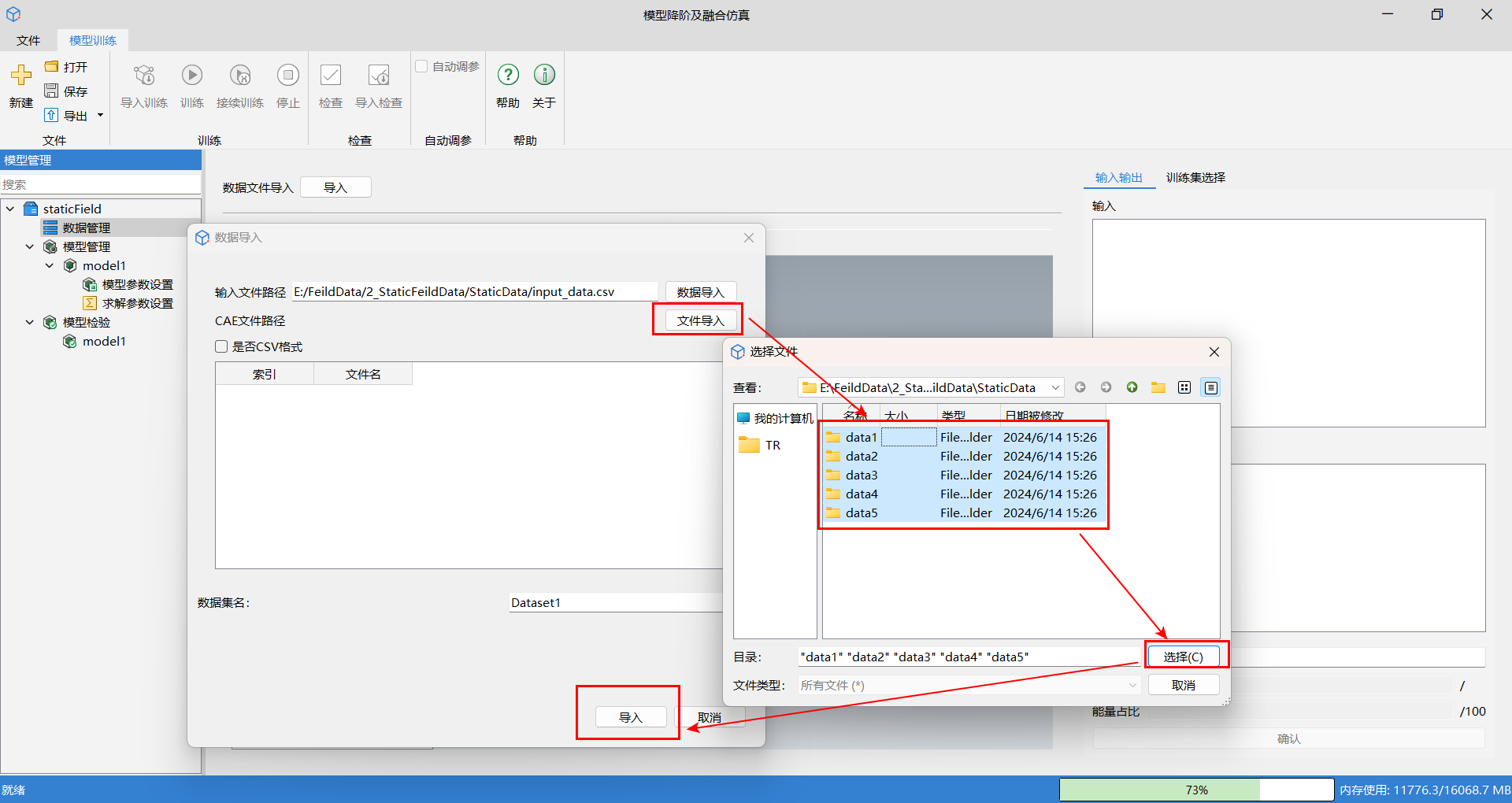
如果需要导入无网格拓扑场数据,在数据导入页面,首先勾选是否 CSV 格式,然后分别导入输入数据文件与输出数据文件,最后单击导入。
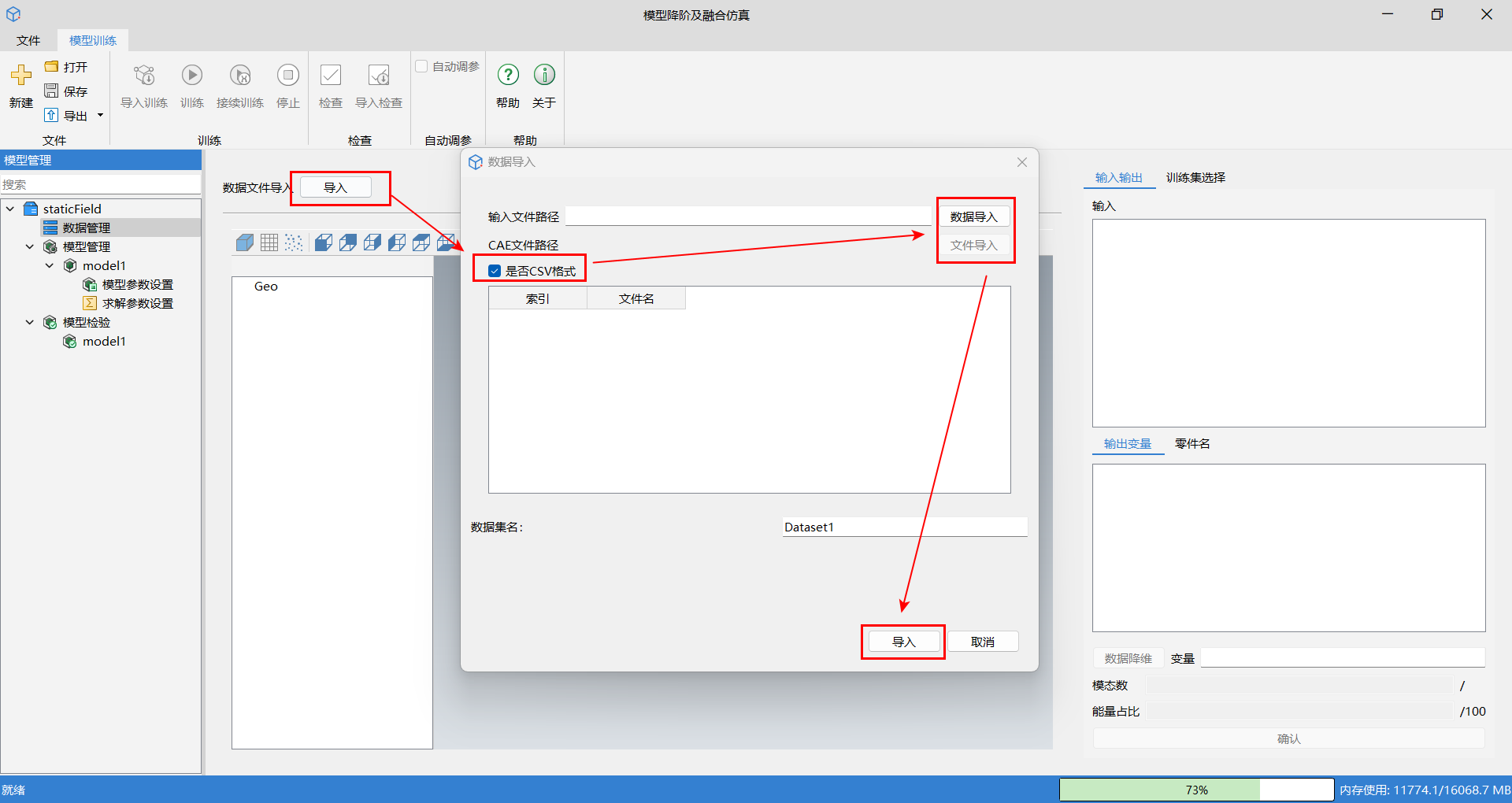
导入数据后可视化界面显示规则如下:
case 格式数据: 当导入数据形式为 case 时,静态场数据图像显示,通过选择视图和几何树来显示静态场数据的形状。
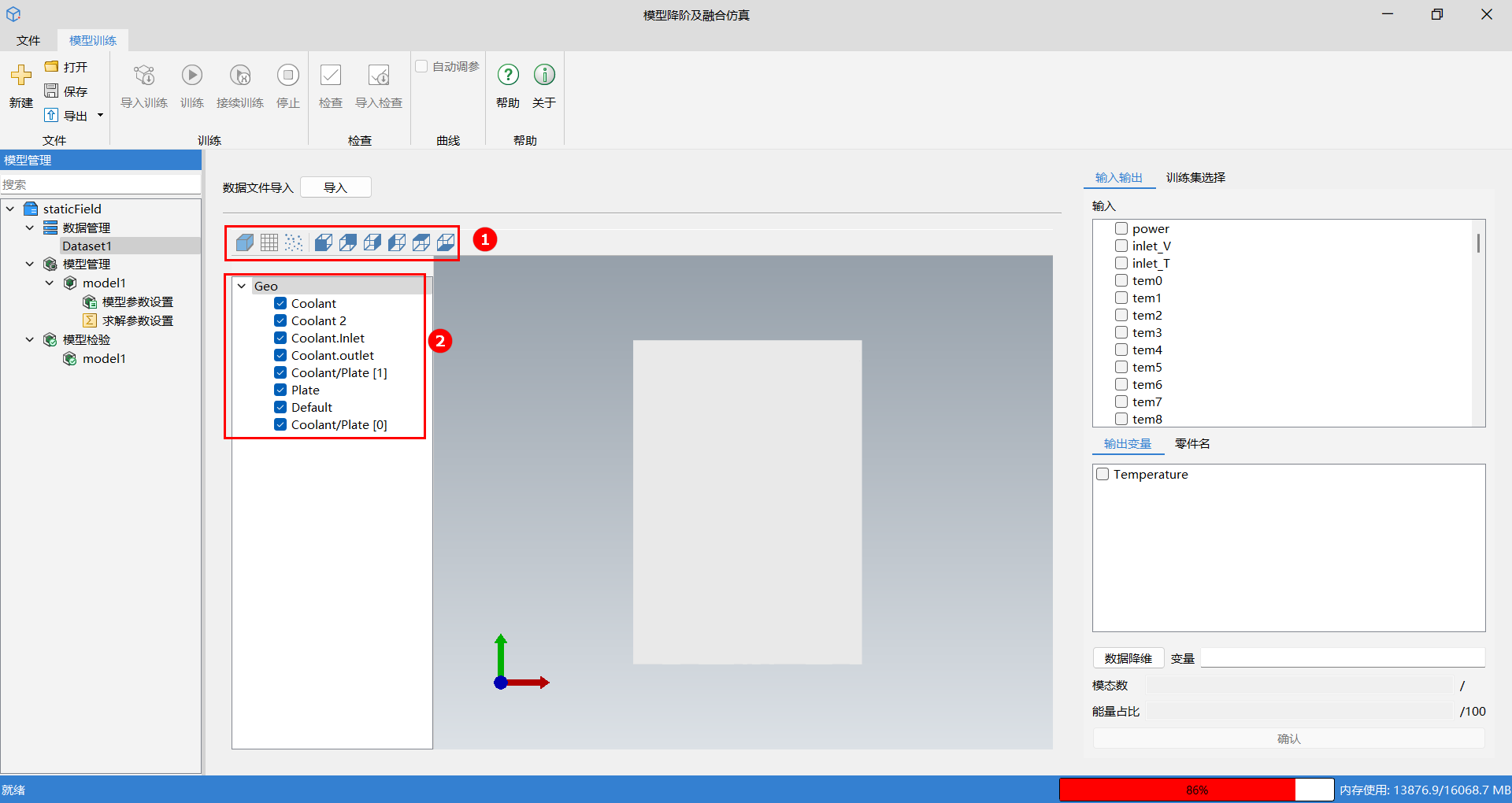
- 视图:可以显示场数据的整体视图、网格视图、点视图和前视图、后视图等。
- 几何树:展示场数据的局部结构,便于查看和分析几何组成。
无网格拓扑数据: 当导入数据形式为无网格拓扑场数据时,图形区域显示为散点图,视图选项,可查看散点图的各个方向视图,几何树区域默认仅有 Part1,散点图数据不进行几何结构划分。
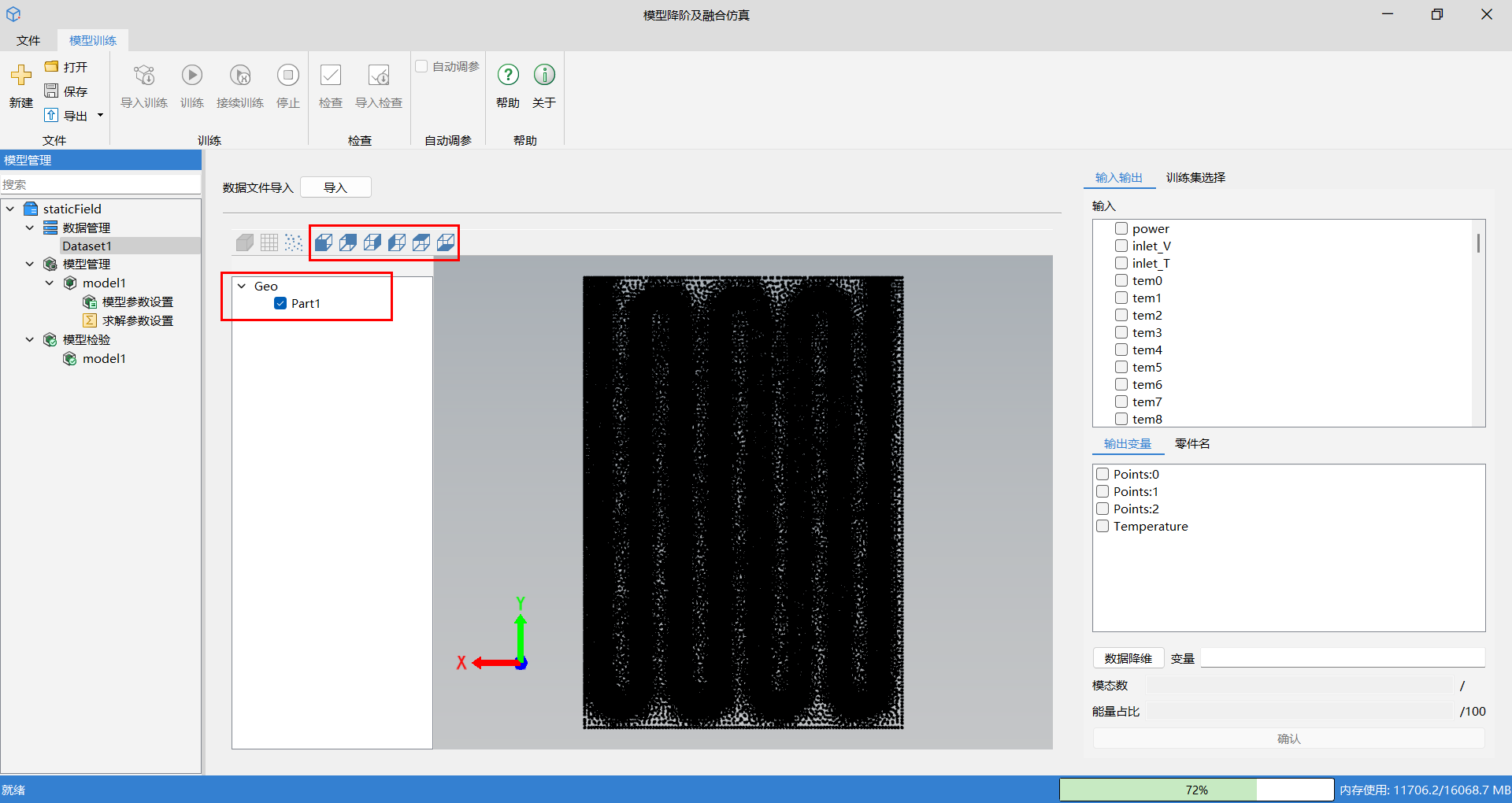
用户可以在输入/输出窗口中自定义勾选输入/输出变量。
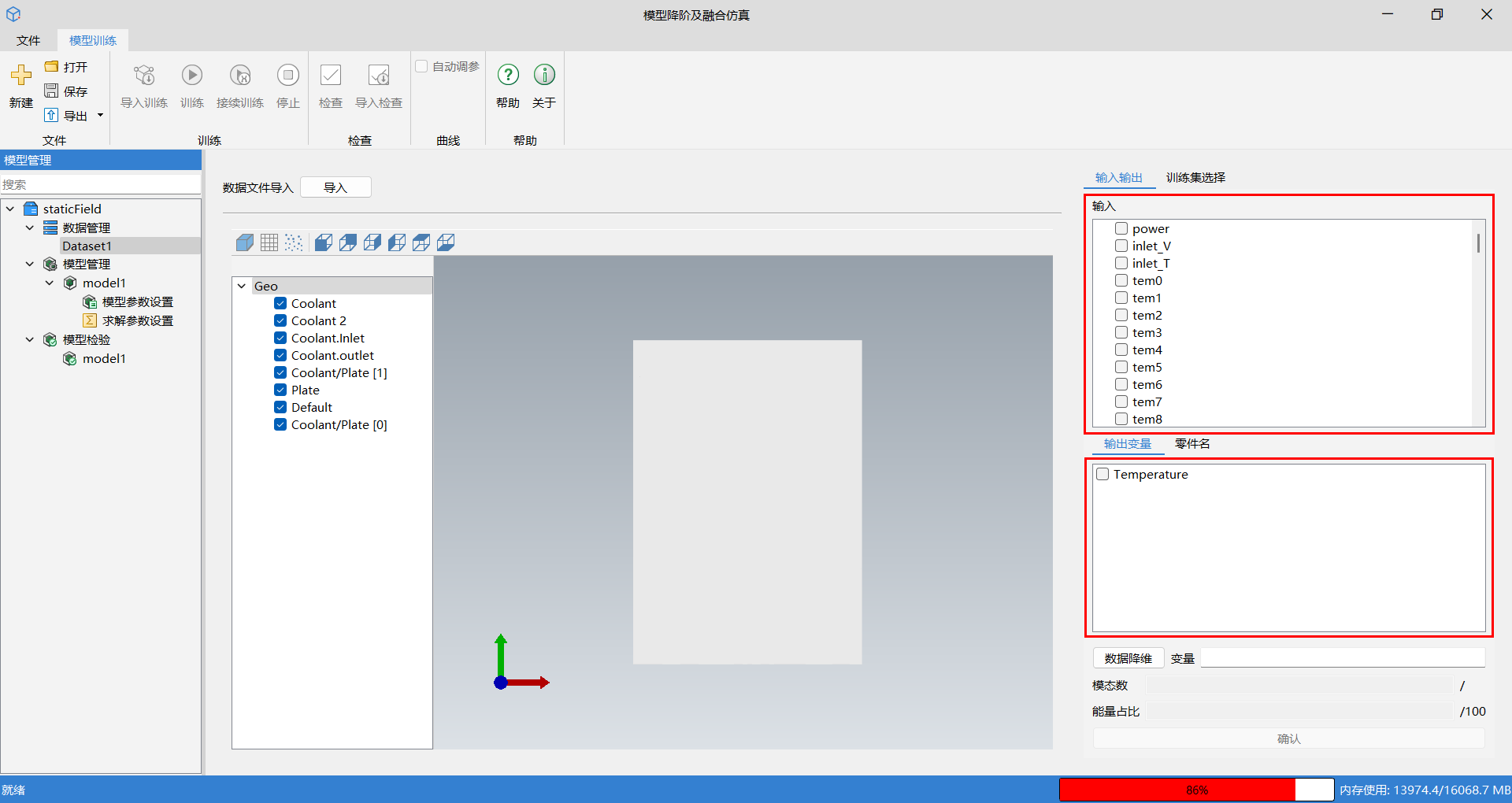
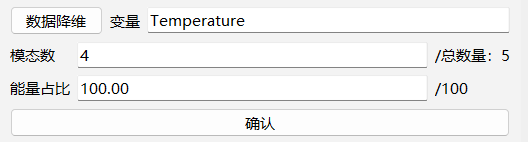
在选择好输入输出变量后,仍需进行数据降维操作,静态场数据仅需要进行一次降维操作。
参数说明:
数据降维:
- 原理:对所选择的变量进行数据降维来保证获取合适的低维特征作为输出。将高维数据投影到低维空间,保留主要信息,减少冗余,提高模型训练效率。
- 效果:降低数据维度,减少计算量,提高模型训练速度,同时保留主要信息。
- 建议:对于场数据,降维是必要的步骤,建议根据能量占比选择合适的模态数。
模态数:
- 原理:待降维完成后设置所要作为输出的数据模态,模态数决定降维后保留的特征数量。
- 效果:模态数越多,保留信息越丰富,但模型复杂度增加;模态数越少,模型越简单,但可能丢失重要信息。
能量占比:
- 原理:填写完模态数后,能量占比自动填写。能量占比表示降维后保留的主成分所占总方差的比例,反映降维信息保留程度。
- 效果:能量占比越高,保留信息越多,但需要的模态数也越多;能量占比越低,保留信息越少,但模型更简单。
训练集划分操作,该过程参照静态模型系统数据导入章节。
# 动态模型场数据导入
# 文件格式说明
# 输入文件格式说明
动态场的输入文件为多个,与工况数相同,即每个工况对应一个输入文件,文件格式为 .csv(或 .txt),每个输入文件中的格式内容与静态场的输入文件相同,即第一行为关键字"data",第二行为变量名称,第三行开始为当前对应瞬态工况的每个时间步的输入值。
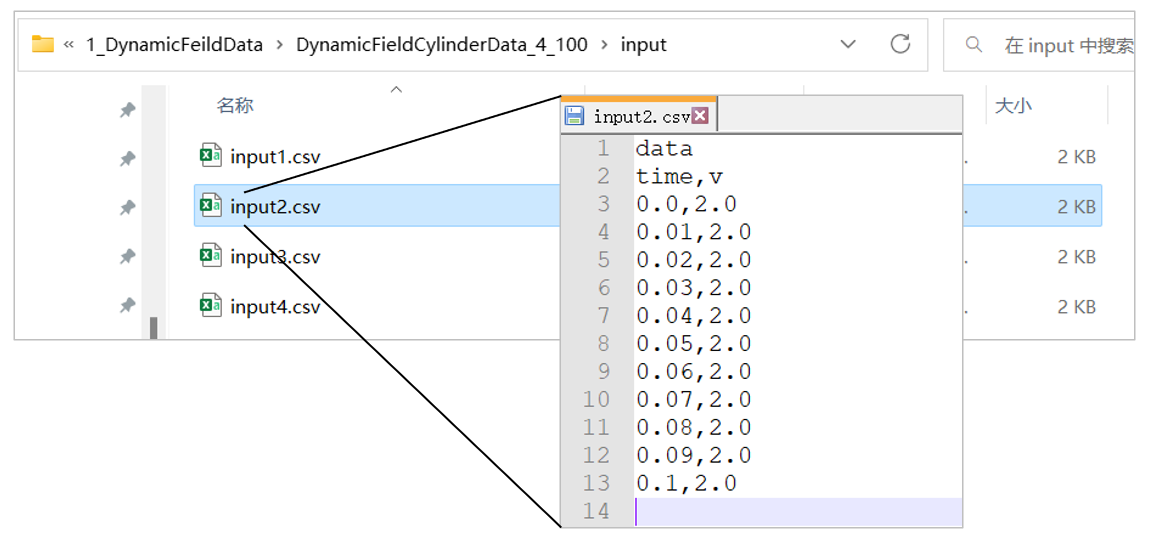
提示
动态场的输入文件数量与工况数相同,确保每个工况都有对应的输入文件,且文件顺序与工况顺序一致。
# 输出文件格式说明
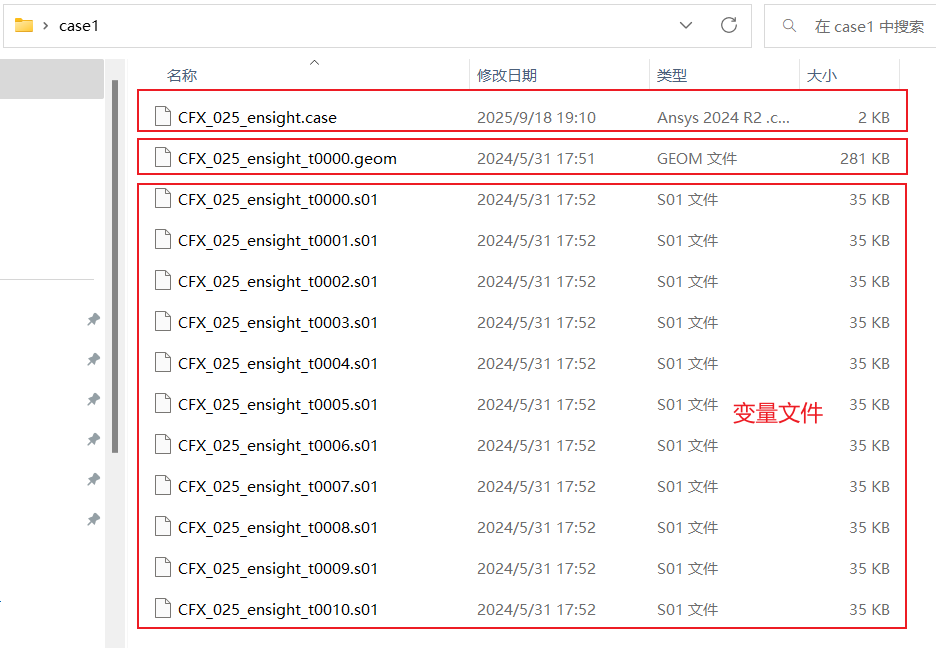
case 场数据格式说明:
动态场 case 文件格式与静态场相似,区别在于,静态场每个工况中仅存储一个稳态时间步结果,而动态场每个工况存储瞬态过程结果,即多个时间步结果。动态场数据每个工况存储在一个文件夹中,每个文件夹中包含三种类型文件,包括信息索引 .case、几何文件 .geo 和多个时间步的变量文件,这样一组文件构成一个完整的输出工况,并且与一组多时间步的输入保持对应。
无网格拓扑场数据格式说明:
对于动态场的无网格拓扑数据(即 csv 形式),输入文件与 case 格式相同,输出文件与静态场的无网格拓扑数据形式相似,区别在于动态场每个工况(即每个文件夹)存储多个时间节点数据,每个时间节点存储为一个 csv 文件,该 csv 文件内存储变量、数据格式与静态场无网格拓扑场数据格式要求相同。
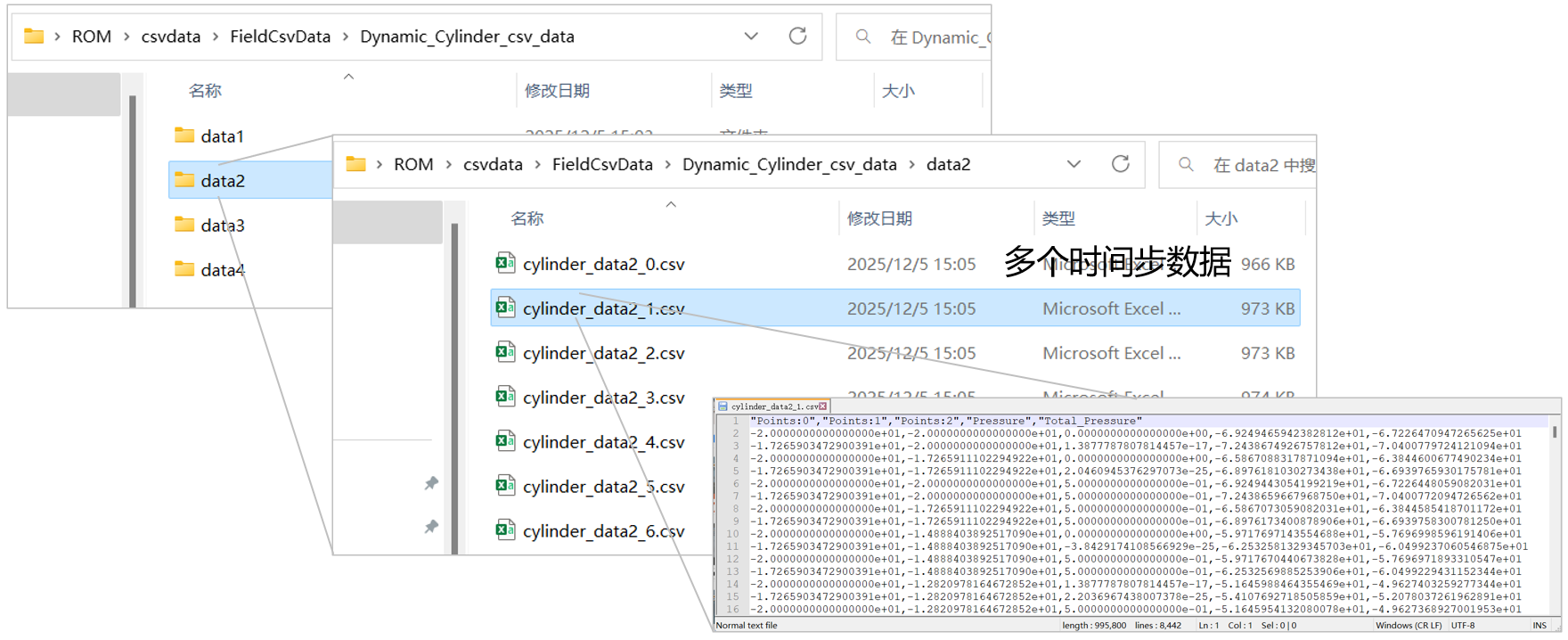
每个时间步的 csv 文件内格式要求与静态场格式要求一致。
# 操作流程
动态模型中,导入动态场数据的操作如下:
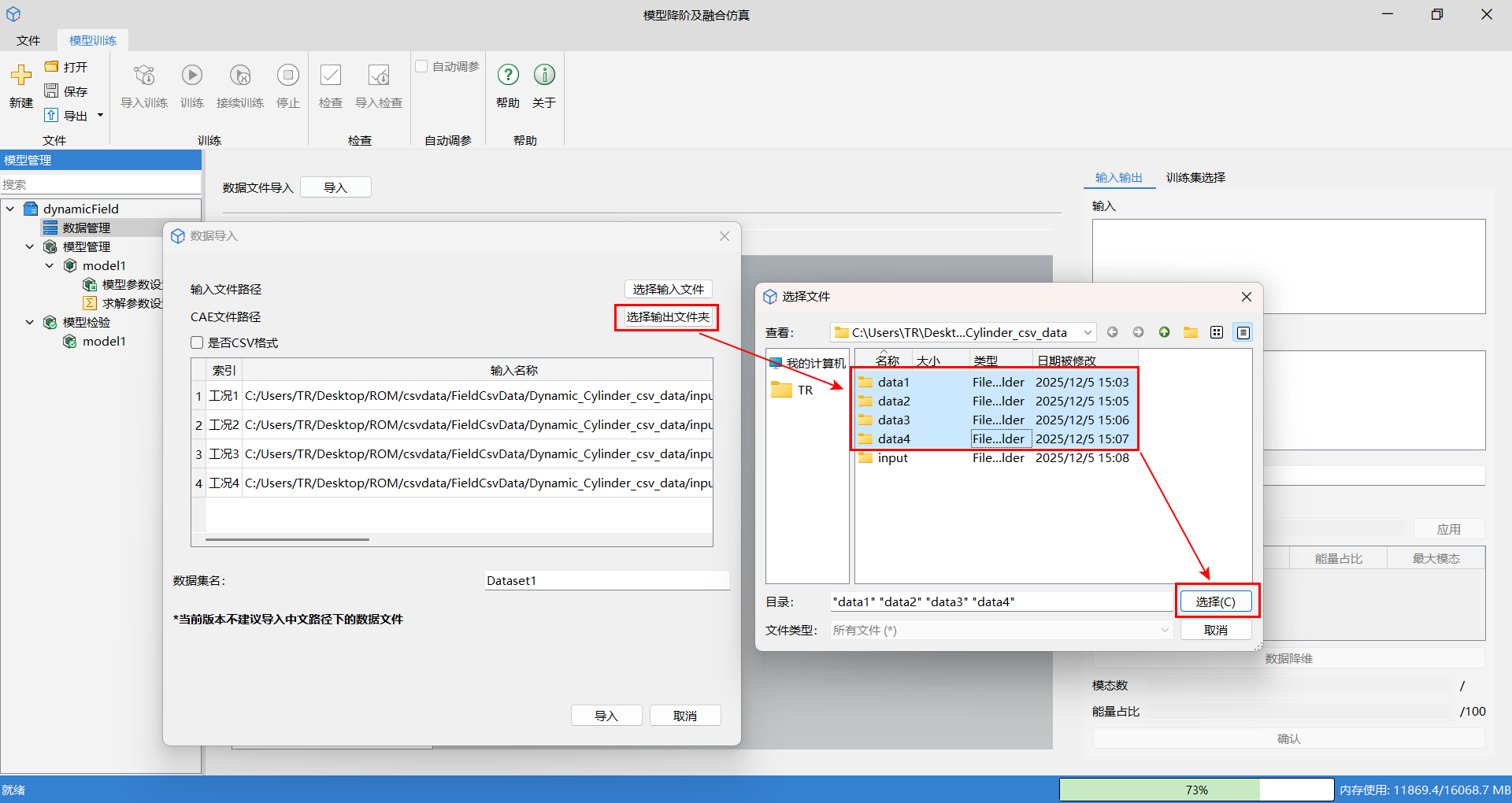
单击数据管理,接着单击导入按钮,在数据导入窗口,单击选择输入文件,批量选中输入文件,单击打开。
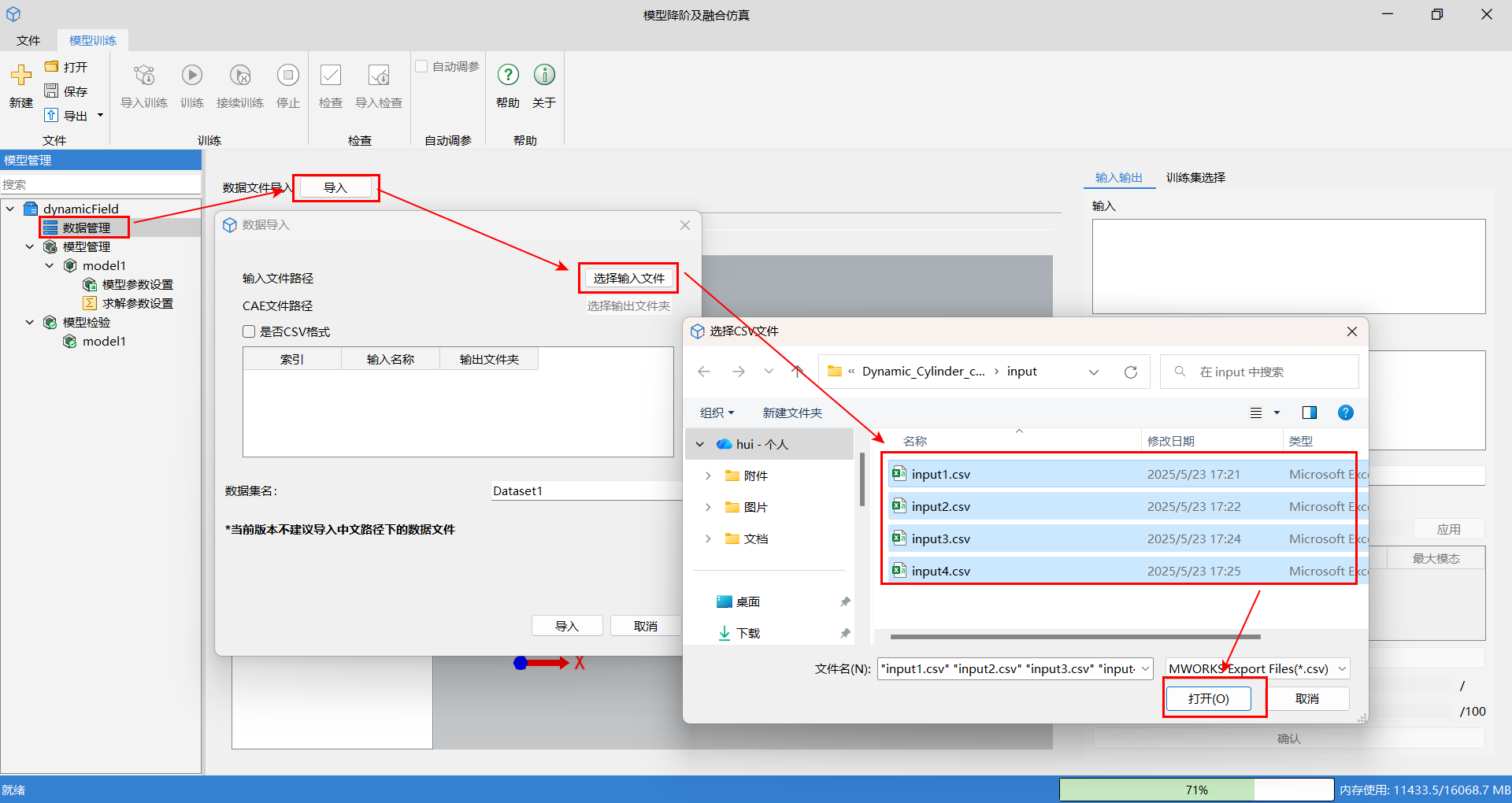
单击选择输出文件夹,批量选中场数据文件,单击选择。此处注意:输入文件与输出文件的顺序均为导入时的顺序,并按照导入顺序进行匹配对应,需要用户提前将文件按顺序排列。
提示
输入文件与输出文件的匹配关系基于导入顺序,建议在导入前按工况顺序整理文件,确保对应关系正确。
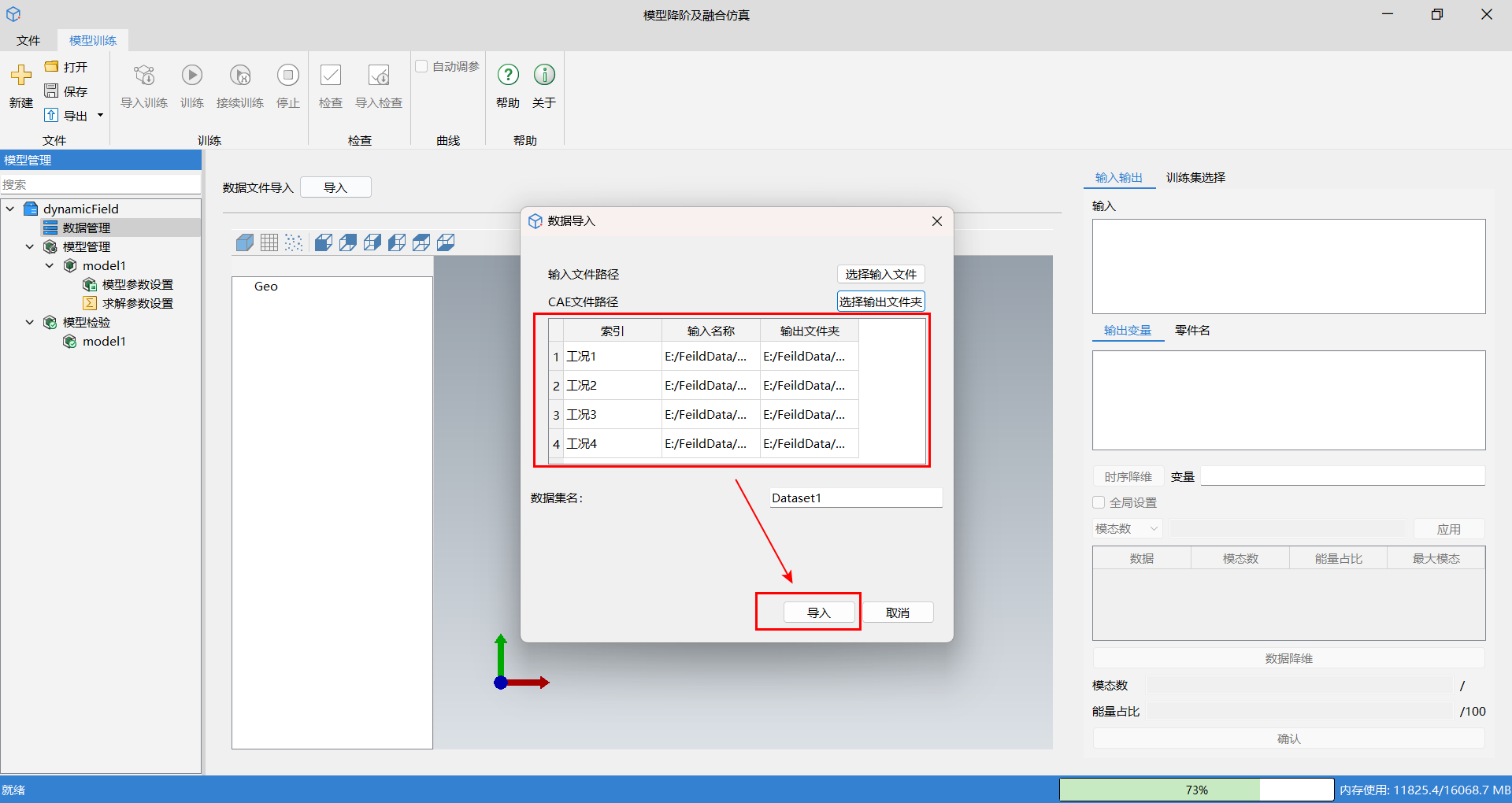
选择输入和输出文件后,数据会在导入窗口,按照导入顺序显示,并作为后续计算时的对应关系,最后单击导入。成功导入后,会显示相应的输入输出以及场几何结构。
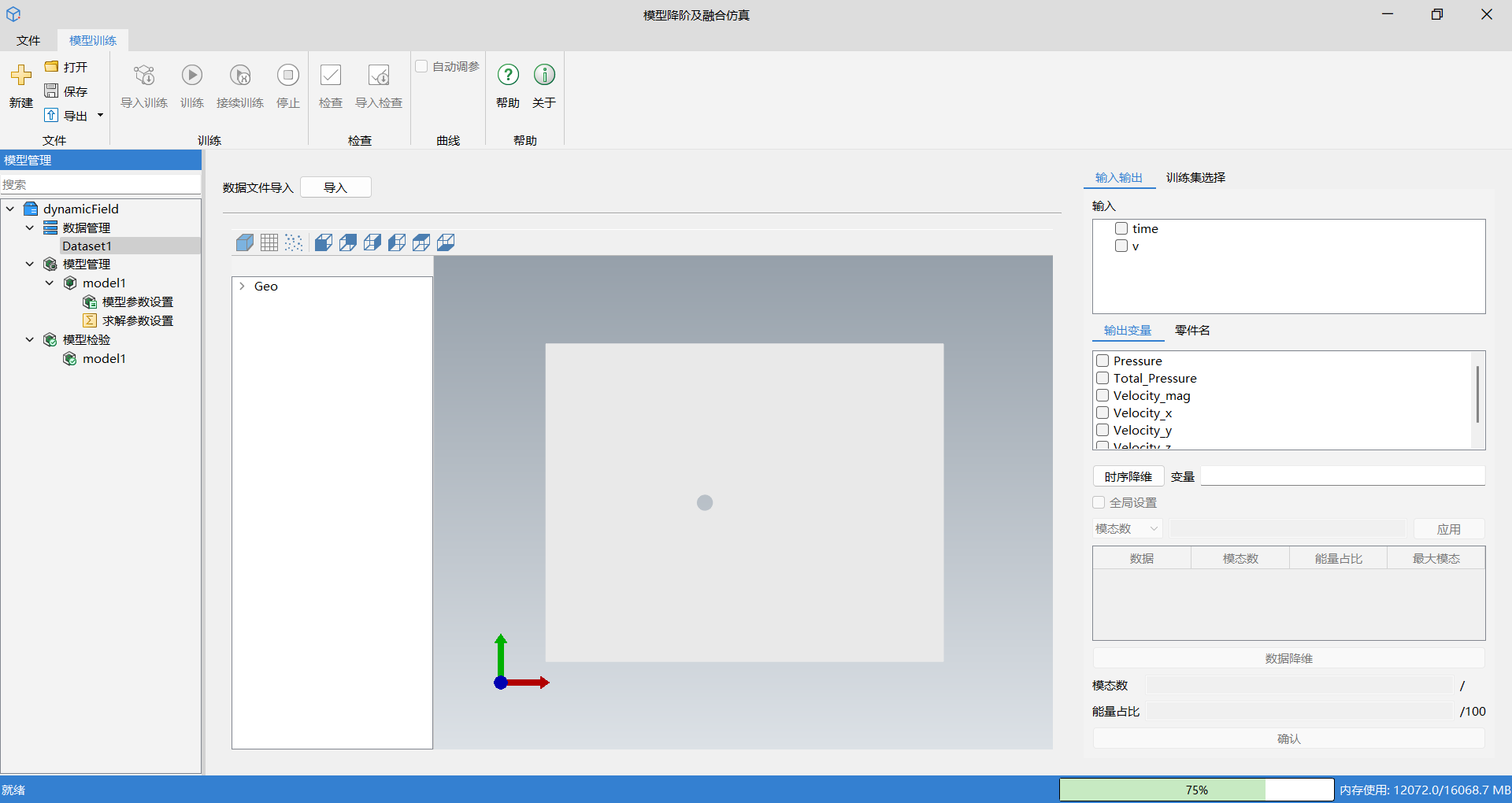
可以在输入输出窗口中选择输入变量及输出变量。输入变量可多选,输出变量仅支持单选,所选变量名会显示在下方变量栏;选择输出变量后,可以在零件名查看几何结构组成。
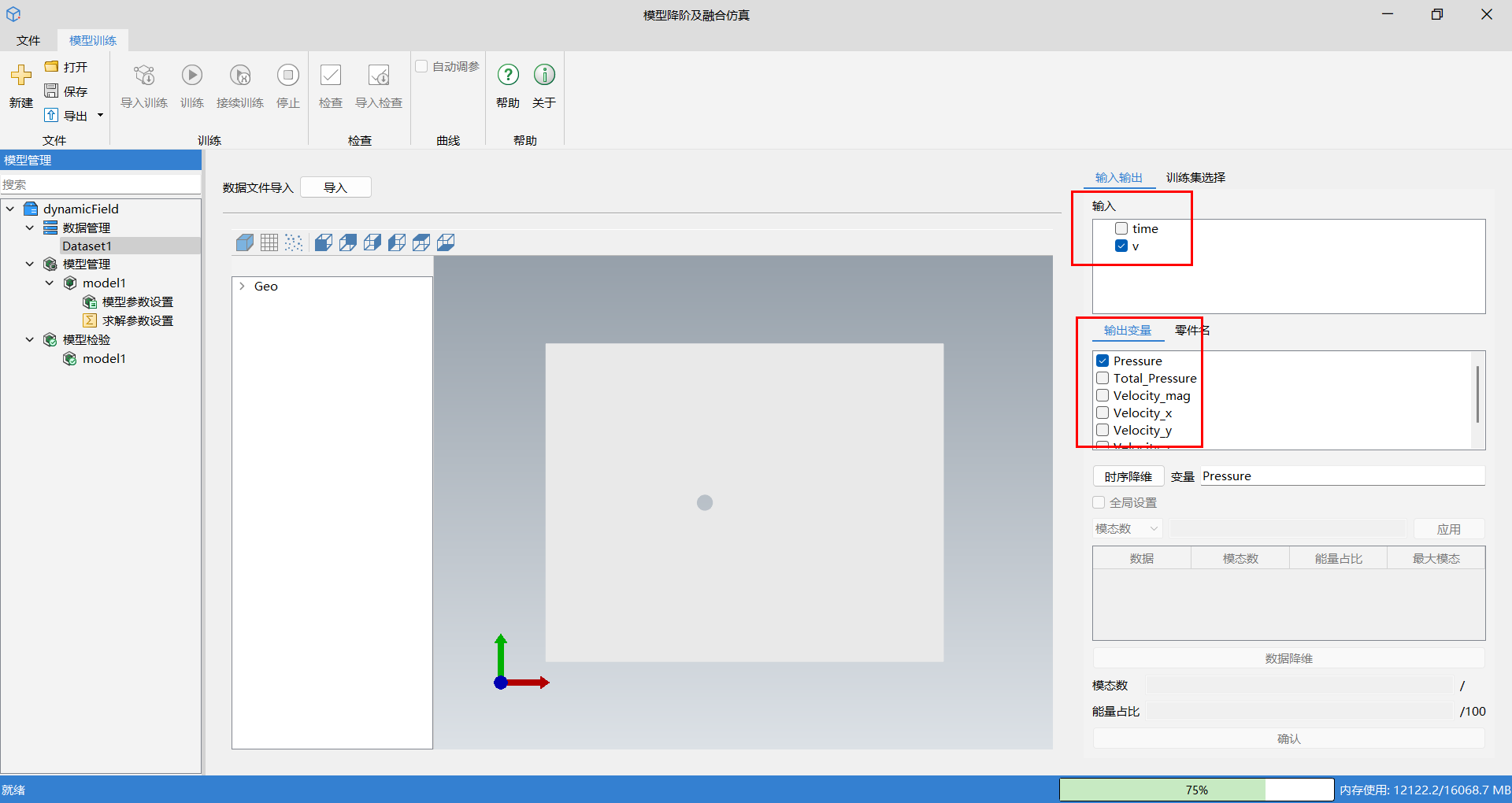
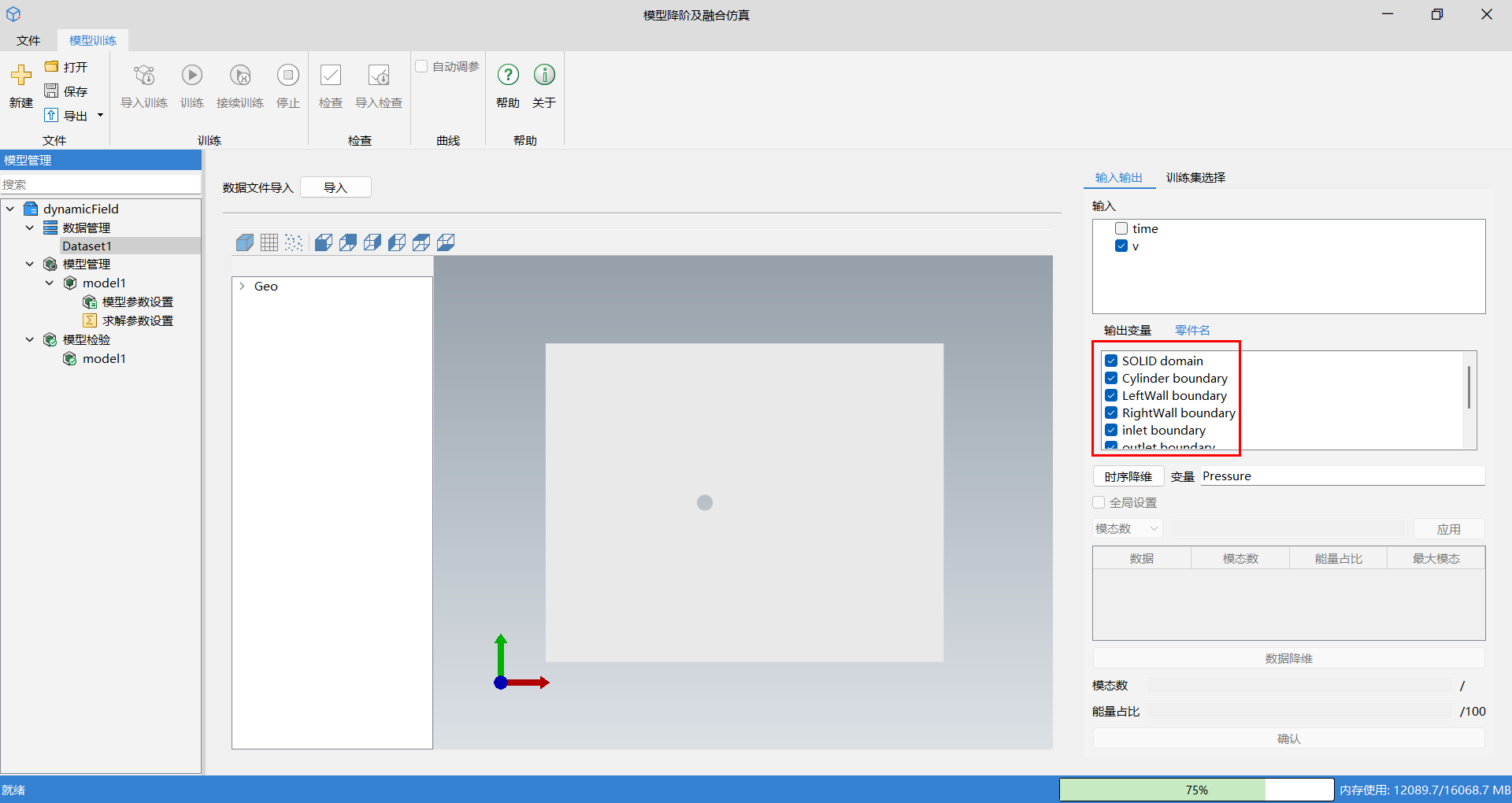
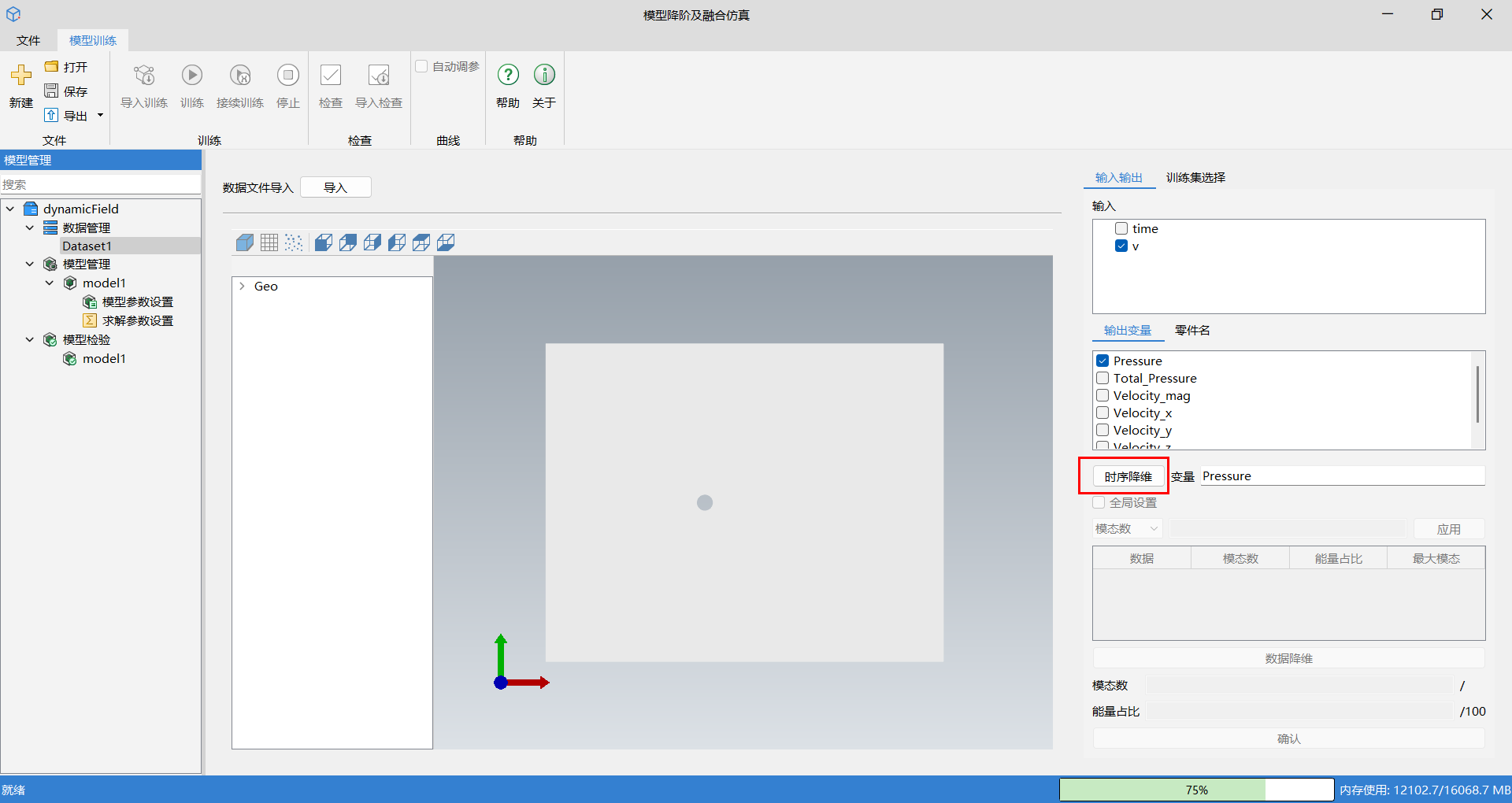
在选择好输入输出数据后,需进行数据降维操作,动态场数据需要进行两次降维,首先单击时序降维。时序降维针对时序工况,对每个工况(即每个时序过程)单独进行一次降维分解,用户需要对时序降维结果,即每个工况设置能量占比或想要保留的模态数。
参数说明: 能量占比值范围为 [0, 100],模态数最小值为 1,最大值为最大模态,设置方式有如下两种:
- 在时序降维结果表格中直接对单个工况的模态数或能量占比进行修改,修改其中之一,可计算另一个值。
参数说明:
时序降维:
- 原理:针对时序工况进行降维处理,对每个工况(即每个时序过程)单独进行一次降维分解,提取该工况在时间维度上的主要特征模态,将高维时序数据投影到低维空间。
- 效果:降低每个工况的数据维度,减少冗余信息,提高训练效率,同时保留各工况动态过程的主要特征。
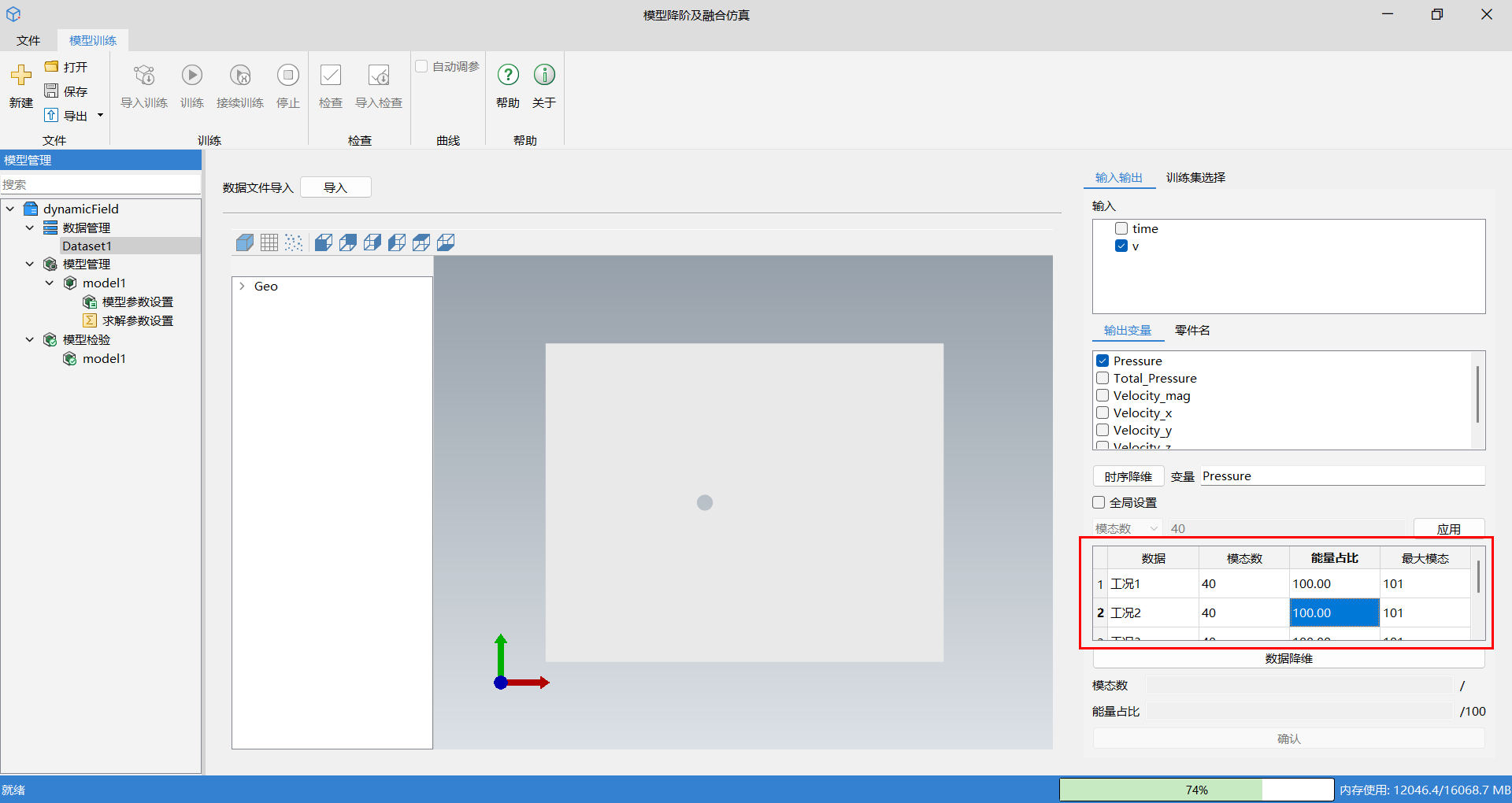
通过勾选全局设置,在下拉框中选择模态数或能量占比,并填写相应的值,单击回车或应用,可修改全部工况的模态数和能量占比。
基于时序降维结果,单击数据降维,后输入模态数或能量占比,单击确定,即完成数据降维操作,生成后续的训练数据。
提示
时序降维与数据降维是动态场数据建模的关键步骤,建议根据工况特性合理设置模态数,既要保留足够的动态信息,又要避免过高的维度。