# FMU 导出
# 功能概述
在 Sysplorer 中,用户可以将 Modelica模型(即物理模型)、框图模型,以及二者的混合模型导出为符合 FMI 规范的 FMU,以支持跨平台系统集成与协同仿真。
| 模型类型 | 支持导出的 FMU 类型 | 支持的 FMI 版本 | 支持的平台 | 支持的位数 |
|---|---|---|---|---|
| 物理模型 | Model Exchange | v1 | Windows / Linux | 32 位 / 64 位 |
| v2 | ||||
| v3 | ||||
| Co-Simulation | v1 | |||
| v2 | ||||
| v3 | ||||
| 框图模型 | Co-Simulation | v2 | Windows / Linux | 32 位 / 64 位 |
| 物理-框图混合模型 | Co-Simulation | v2 | Windows / Linux | 32 位 / 64 位 |
Sysplorer 的 FMU 导出功能支持以下特性:
支持多种 FMI 版本:可根据目标平台与集成需求灵活选择 FMI 1.0 (V1)、2.0 (V2) 或 3.0 (V3) 版本;
支持多实例运行:Co-Simulation 类型 FMU 的
modelDescription.xml中,canBeInstantiatedOnlyOncePerProcess默认为false,即允许在同一进程内创建同一 FMU 的多个不同实例,每个实例具有独立状态与数据,彼此隔离、互不干扰;支持独立仿真:生成的
modelDescription.xml中,needsExecutionTool默认为false,导出的 FMU 具有良好的平台无关性,可在C、Python等自定义程序中加载并控制仿真流程(如调用DoStep接口),无需依赖特定仿真工具,实现灵活的独立仿真。
注意
- 暂不支持含同步时钟的物理模型导出 Model Exchange 类型的 FMU;
- 框图模型以及物理-框图混合模型只支持导出 V2 Co-Simulation 的 FMU,不支持导出 Model Exchange 类型的 FMU。
# 功能面板
Sysplorer 中 FMU 导出功能面板总体设计如下图所示:
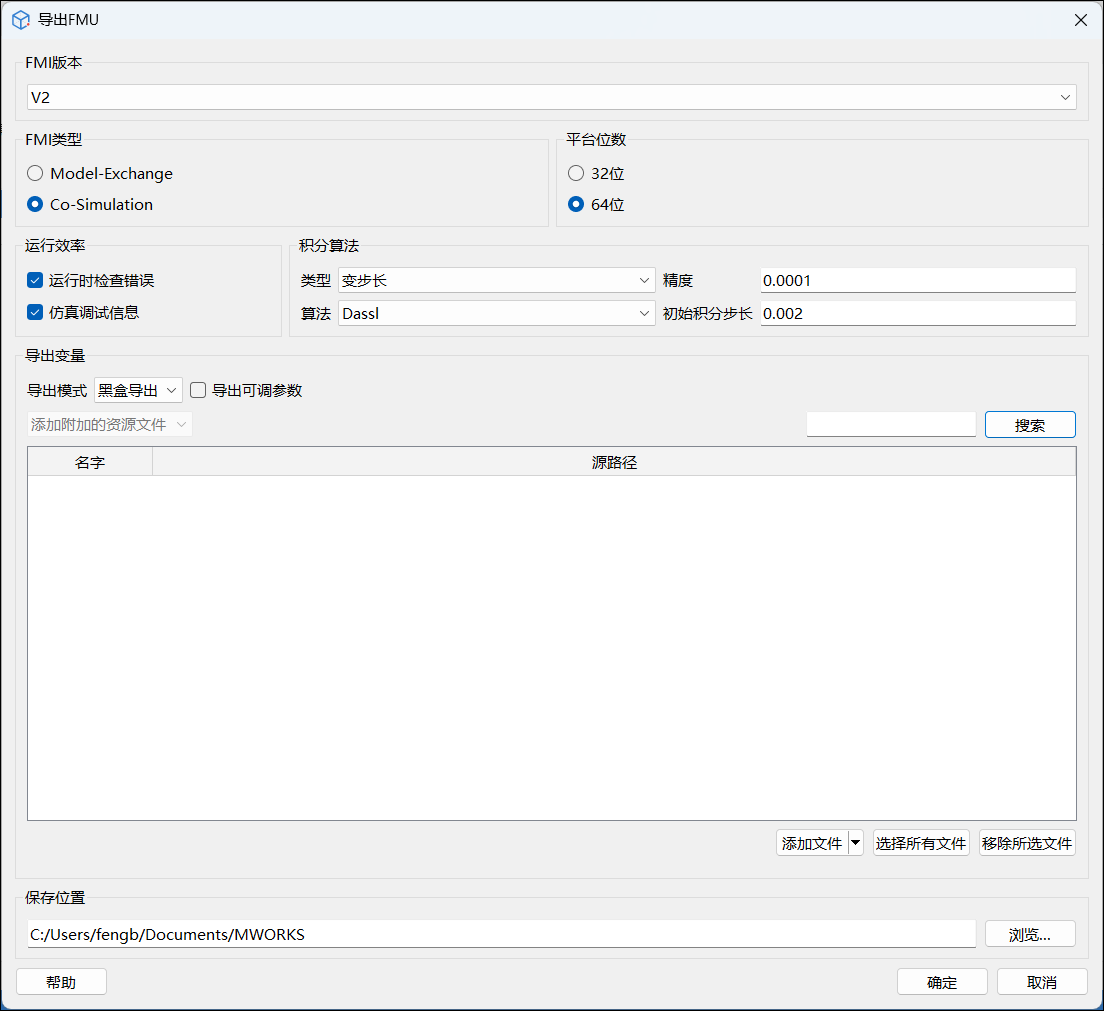
# FMI 版本及类型
Sysplorer 支持在导出 FMU 时选择版本与类型:

- FMI 版本:下拉列表可选 V1、V2 或 V3,分别对应 FMI 1.0、2.0 及 3.0 规范;
- FMI 类型:可选择模型交换(Model Exchange)和协同仿真(Co-Simulation)两种类型;
- 平台位数:可选择 32 位平台或 64 位平台。
提示
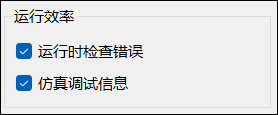
# 运行效率
Sysplorer 支持在导出 FMU 时配置【运行效率】相关选项:
注意
启用【运行效率】相关选项会降低仿真效率。
提示
若在【运行效率】设置区勾选了任意选项并导出 FMU,且希望在仿真过程中输出调试日志,则需在 FMU 导入后的模型文本中手动将模型常量fmu_LoggingOn设置为true。
# 使用建议
- 若导出的 FMU 需在实时仿真平台等高性能场景中运行,建议关闭【运行效率】设置区中的所有选项,以降低额外的调试和检查开销。
- 若在模型开发阶段需检测模型中是否存在非法数值运算,建议启用【运行时检查错误】;若已确认模型无此类问题,则在正式导出至生产环境时应关闭该选项,以避免不必要的性能损耗。
- 若需调试模型(例如查看事件触发信息),建议启用【仿真调试选项】。
# 运行时检查错误
勾选该选项后,导出的 FMU 会在运行过程中对数值运算进行合法性检查,可辅助定位如负数开方、除零等错误。
注意
勾选【运行时检查错误】会一定程度降低仿真效率。
例如,如下示例模型中存在负数开方和assert操作符:
model Model2
annotation(__MWORKS(version = "2025b"));
Real x;
Real y;
equation
x = sin(time);
assert(x >= 0, "x should not be less than 0", AssertionLevel.error);
y = sqrt(x);
end Model2;
提示
有关assert操作符的详细信息,请参见Modelica语言规范:8.3.7 assert (opens new window)。
如果导出 FMU 时勾选【运行时检查错误】,则模型编译生成的C语言代码中会包含assert语句和带调试信息的sqrt语句moAssert:
MWS_DYNAMIC_SECTION_I_BEGIN(1)
MWS_DYPT_PARTITION_BEGIN(1)
R_[1]/*x*/ = sin(TIME_);
R_[2]/*y*/ = moSqrt(R_[1]/*x*/, "x");
moAssert(R_[1]/*x*/ >= 0, "x>=0", "x should not be less than 0", 1);
MWS_DYPT_PARTITION_END
MWS_DYNAMIC_SECTION_I_END
且该 FMU 仿真时会报错:
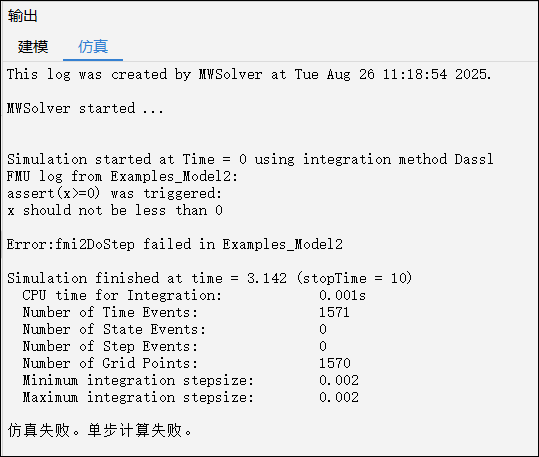
如果导出 FMU 时不勾选【运行时检查错误】,则模型编译生成的 C 语言代码中不会包含assert语句且sqrt语句也不带调试信息:
MWS_DYNAMIC_SECTION_I_BEGIN(1)
MWS_DYPT_PARTITION_BEGIN(1)
R_[1]/*x*/ = sin(TIME_);
R_[2]/*y*/ = sqrt(R_[1]/*x*/);
MWS_DYPT_PARTITION_END
MWS_DYNAMIC_SECTION_I_END
FMU 仿真时,如果对负数执行开方运算,结果会被计算为接近无穷大的数值(约
# 仿真调试信息
勾选【仿真调试信息】后,导出 FMU 时会将调试信息嵌入模型中。在 FMU 仿真过程中,这些信息将被输出,例如:在发生离散事件时,会记录其触发时刻及事件更新的相关信息。
需要注意的是,【仿真调试信息】还需配合fmi2SetDebugLogging接口使用。用户需调用该接口并启用相应的日志类别,才能输出对应的调试信息。
提示
有关
SetDebugLogging接口的详细介绍,请参见:- FMI 3.0 规范第 2.3.1节 (opens new window);
- FMI 2.0 规范第 2.1.5 节:可前往 FMI 官网 (opens new window)下载
PDF查阅。
有关日志类别的详细介绍,请参见:
- FMI 3.0 规范第 2.4.5节 (opens new window);
- FMI 2.0 规范第 2.2.4 节:可前往 FMI 官网 (opens new window)下载
PDF查阅。
# 积分算法
Sysplorer 支持在导出 FMU 时配置积分算法:


默认情况下会继承仿真设置页面中积分算法的配置。
【类型】:积分算法主要分为如下几种类型:
定步长:采用固定积分步长推进仿真,步长不受模型状态变化影响。
提示
定步长算法的典型代表为 Euler 算法,技术细节请参见:
- E Hairer, S.P. Nørsett, G. Wanner. Solving ordinary differential equations I: Nonstiff problems[M]. New York: Springer Berlin Heidelberg, 1993.
变步长:采用动态调整积分步长推进仿真,基于局部截断误差自适应控制步长。
提示
变步长算法的典型代表为 Dopri5 算法,技术细节请参见:
- Dormand J R, Prince P J. A family of embedded Runge-Kutta formulae[J]. Journal of computational and applied mathematics, 1980, 6(1): 19-26 (opens new window)
- E Hairer, S.P. Nørsett, G. Wanner. Solving ordinary differential equations I: Nonstiff problems[M]. New York: Springer Berlin Heidelberg, 1993.
离散求解:将微分方程离散化为差分方程,通过代数求解器直接解算,无需进行数值积分。
自定义:用户自行实现算法并集成至 Sysplorer。
提示
有关在 Sysplorer 中集成自定义算法的详细信息,请参见:求解算法扩展接口。
【精度】:精度设置主要有以下两方面作用:
- 用于指定变步长积分算法的相对与绝对容差。
- 与软件内置的缩放系数结合,共同决定非线性方程求解的收敛容差。
【算法】:列出所选类型下可用的算法,供用户自由选择。
【初始积分步长】:
- 若算法类型为变步长,则该项为初始积分步长,默认继承仿真设置中的初始积分步长。
- 若算法类型为定步长,则该项为固定积分步长,默认继承仿真设置中的固定积分步长/积分步数。
注意
- 仅在导出纯物理模型的 Co-Simulation 类型 FMU 时,才可选择离散求解算法;
- 仅在导出纯物理模型的 FMU 时,才可选择自定义算法。
# 使用建议
Sysplorer 支持的定步长和变步长积分算法列表如下:

上表中单步法用黑色字体标注,多步法用橙色字体标注,各类型的推荐算法使用下划线标注。
提示
有关单步法的详细信息,请参见:
- Butcher J C. Numerical methods for ordinary differential equations[M]. John Wiley & Sons, 2016.
有关多步法的详细信息,请参见:
- Butcher J C. Numerical methods for ordinary differential equations[M]. John Wiley & Sons, 2016.
有关显式和隐式算法的详细信息,请参见:
- E Hairer, S.P. Nørsett, G. Wanner. Solving ordinary differential equations I: Nonstiff problems[M]. New York: Springer Berlin Heidelberg, 1993.
对于【积分算法的选择】,用户可参考以下建议:
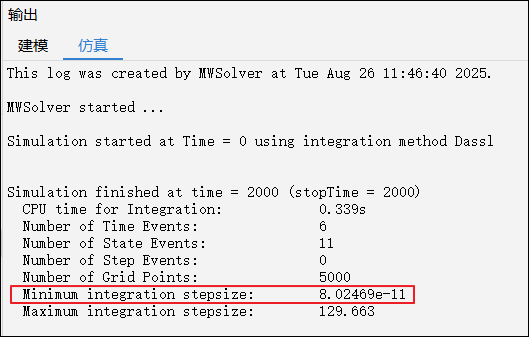
可通过查看变步长算法生成的仿真报表中的最小步长,评估模型是否适合采用定步长算法。若最小步长过小,说明模型动态变化剧烈,不宜使用定步长算法,例如:
若模型求解失败或存在困难,可尝试更换不同的积分算法。
若仿真对精度有严格要求,建议使用变步长算法。
若模型具有刚性特征,则应选择隐式算法。
提示
有关刚性的详细介绍,请参见:Stiff equation - HandWiki (opens new window)。
若模型存在大量离散事件导致的不连续性,推荐采用变步长单步法。
若需进行实时仿真,应选择定步长算法;若实时仿真无通信需求,也可尝试变步长算法。
离散求解算法广泛应用于电力电子领域,适用于大规模线性系统的仿真以及小步长仿真。
对于【精度】的设置,用户可参考以下建议:
- 精度值越小,变步长算法的求解精度越高,单步计算量越大,仿真效率越低。
- 精度值越小,非线性方程(包括模型本身的以及隐式算法携带的非线性方程)求解迭代次数越多,求解效率越低。
- 除非采用默认设置求解失败,否则不建议增大精度值以降低求解质量。
- 若仿真中途步长变得太小导致仿真卡住,可尝试调整精度值。
对于【固定积分步长】的设置,用户可参考以下建议:
- 理论上,固定积分步长越小,仿真精度越高,但仿真步数也会随之增加,从而降低仿真效率。
对于【初始积分步长】的设置,用户可参考以下建议:
- 通常情况下,用户不需要显式设置初始积分步长,采用默认值即可。
- 对一些仿真启动阶段高刚性或快变的模型,采用默认初始积分步长可能求解失败,此时可尝试减小初始积分步长。
- 较小的初始积分步长在积分频繁重启时,显著影响求解效率。此时,在保证模型可成功求解的前提下,可尝试增大初始积分步长。
# 变量过滤
在 Sysplorer 中,模型仿真后若结果查看器中能够显示某变量的结果曲线,则该变量为可见变量;反之,则为不可见变量。导出 FMU 时,可见变量会被写入modelDescription.xml文件,而不可见变量则不会。
Sysplorer 的 FMU 导出功能支持模型变量过滤,用户可灵活控制哪些变量会写入modelDescription.xml文件。具体支持以下两种方式:
- 通过模型文本设置变量的可见性;
- 通过图形界面便捷地控制变量的可见性。
此外,Sysplorer 还提供了多种导出模式,对应不同的变量过滤级别,详见本文档导出模式。
# 通过模型文本控制可见性
在物理模型中,用户可通过为变量添加HideResult注解或使用protected修饰,控制该变量在仿真结果中的可见性。带有HideResult=true注解或被protected修饰的变量被视为模型不可见变量,其余变量则为模型可见变量。该设置在 FMU 导出时同样生效。
# 通过图形界面控制可见性
在 Sysplorer 中,还提供了以下便捷方式来控制变量的可见性。
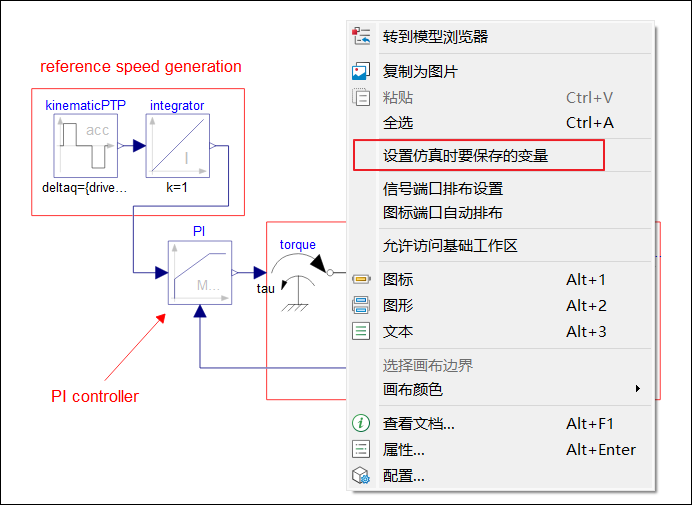
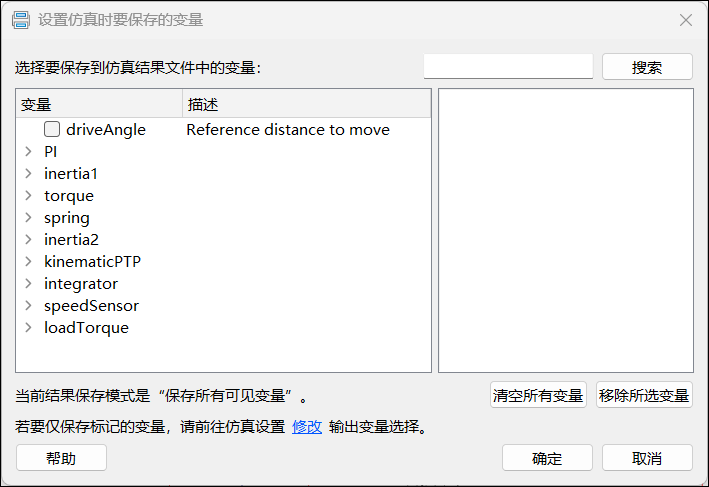
对于物理模型,用户可在模型画布区域右击,选择【设置仿真时要保存的变量】,并在弹出的对话框中勾选需要保存的变量。
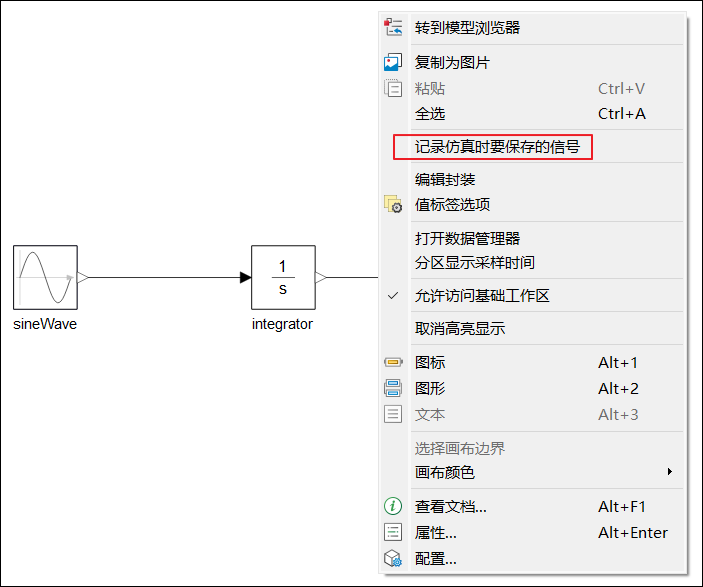
对于框图模型,用户可在模型画布区域右击,打开【记录仿真时要保存的信号】对话框,并在其中选择需要保存的信号。
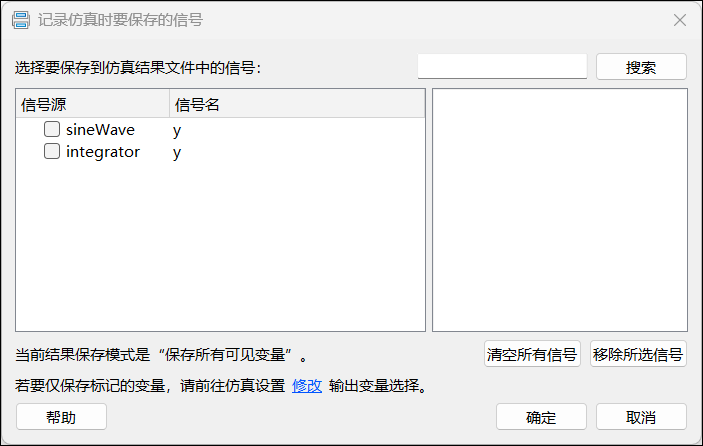
此外,在框图模型中,用户还可以通过右击信号线并选择【记录所选信号】功能,将该信号标记为需保存的信号。所选信号会与上述【记录仿真时要保存的信号】对话框中的内容实时联动。
# 导出模式
# 黑盒导出
在黑盒导出模式下,Sysplorer 会忽略变量的可见性设置,并对导出的变量进行严格过滤,仅在modelDescription.xml中保留模型运行所需的必要变量,具体包括:
- 模型最外层的 输入端口 和 输出端口;
- 按需自适应生成的 其他必要变量。
Sysplorer 默认采用黑盒导出模式,也推荐用户优先选择该模式,其功能面板如下所示:
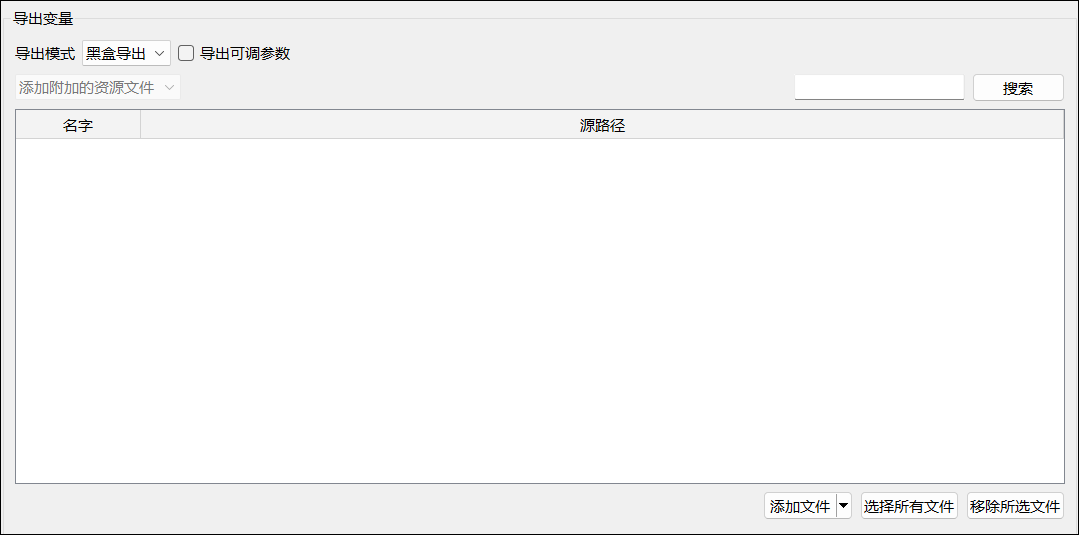
在黑盒导出模式下,还可启用【导出可调参数】选项,用于控制是否将模型中的可调参数生成到modelDescription.xml文件中。
提示
黑盒导出适用于以下场景:
- 需要保护模型的知识产权,最大限度避免内部信息泄露;
- 需要精简变量集以减小 FMU 文件体积,从而提升导出、加载和仿真效率。
一般情况下,强烈建议用户优先采用黑盒导出模式。
# 部分导出
在部分导出模式下,在导出模型必要变量的基础上,用户还可以额外选择并导出指定的模型变量。换言之,部分导出是在黑盒导出的基础上,允许用户自定义需要观测的变量。
当导出模式选择为【部分导出】,并将下方的下拉框切换至【选择要导出的变量】时,将显示如下所示的变量选择面板:
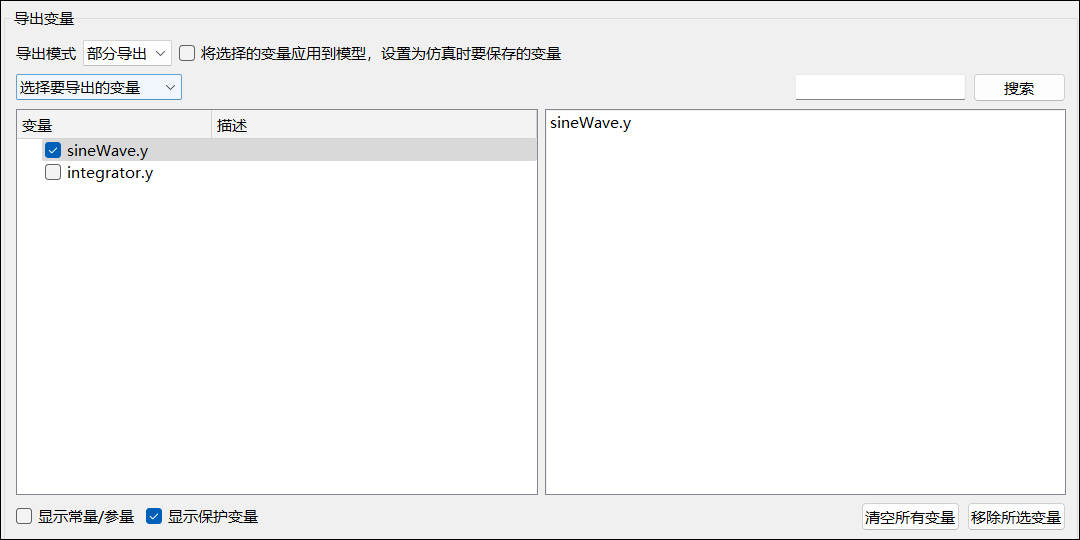
- 【将选择的变量应用到模型,设置为仿真时要保存的变量】:勾选该选项后,用户在部分导出中选定的变量将同步设置为原模型仿真时需保存的变量;
- 【显示常量/参量】:勾选后,变量选择面板中将显示模型中的常量和参量;
- 【显示保护变量】:勾选后,变量选择面板中将显示模型中的保护变量。
变量选择面板中会默认选中用户已手动标记的要保存的变量。
提示
部分导出适用于以下场景:
- 在黑盒保护的前提下,需额外观测模型内部的关键变量,用于模型调试、性能分析或仿真结果验证;
- 既要保护模型的核心参数和内部逻辑(通过黑盒模式隐藏大部分变量),又需满足对部分非敏感变量的访问需求。例如,在联合仿真或系统集成过程中,导入方需要访问特定中间变量,以支持外部分析或结果后处理。
# 完整导出
在完整导出模式下,模型的必要变量及所有可见变量都会被导出,不推荐使用。
提示
模型可见变量的介绍,参见本文档 变量过滤 章节。
完整导出模式下的功能面板如下所示:
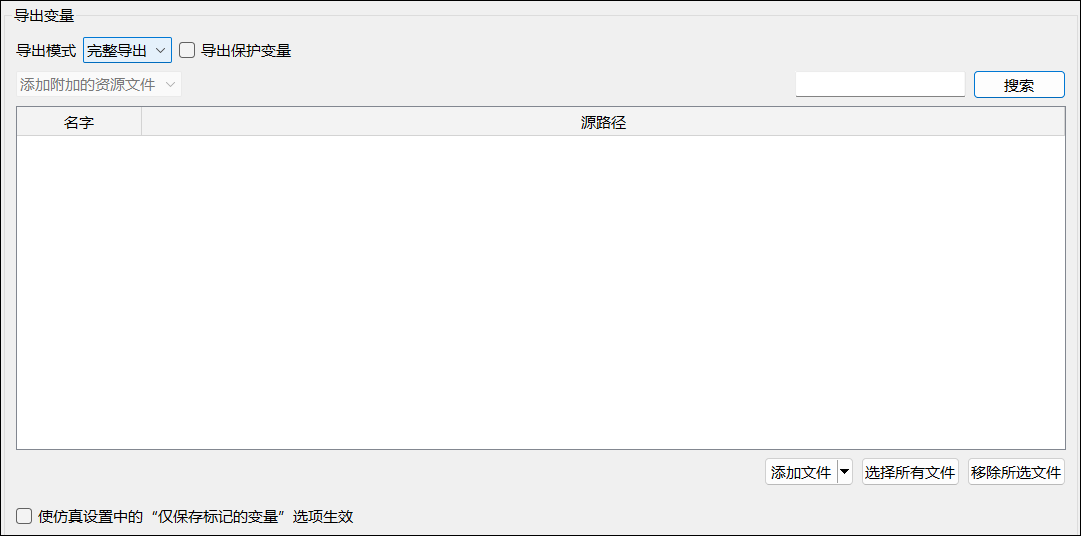
- 【导出保护变量】:用于控制是否将模型中的保护变量导出到
modelDescription.xml文件。该选项默认会继承仿真设置中的【存储protected变量值】配置; - 【使仿真设置中的“仅保存标记的变量”选项生效】:勾选后,若仿真设置中已启用【仅保存标记的变量】,则仅会将已标记的变量导出至
modelDescription.xml文件中。
提示
完整导出适用于以下场景:
- 需要访问模型的全部变量(包括中间变量和内部状态),以便进行问题定位、模型验证或性能调优;
- 在对使用方具备较高信任度、且无需保护模型知识产权的情况下,通过提供完整可见变量来提升模型的可解释性与透明度。
注意
完整导出会显著增加 FMU 文件体积,并可能降低导出、加载及仿真效率。因此,除非确有必要,一般不建议采用完整导出模式。
# 模式对比
以Modelica 4.0标准库中的模型Modelica.Fluid.Examples.HeatExchanger.HeatExchangerSimulation为例,在保持导出面板其他设置均为默认的情况下(FMI V2 Co-Simulation 64 位),仅切换导出模式,并且导入后的 FMU 采用相同的默认仿真设置,得到如下对比结果:
| 导出模式 | FMU 文件大小 | XML 文件行数 | FMU 仿真耗时 |
|---|---|---|---|
| 黑盒导出 | 861 KB | 71 | 6.995s |
| 完整导出 | 989 KB | 26975 | 17.191s |
提示
基于上述结果,强烈建议用户优先选择黑盒导出模式,尽量避免使用完整导出模式,从而获得更小的 FMU 文件体积和更高的仿真效率。
# 附加资源文件
Sysplorer 支持在导出 FMU 时添加附加资源文件。用户可选择需要添加的文件或文件夹,所选内容将被打包至 FMU 的resources文件夹中。
资源文件选择面板如图所示:
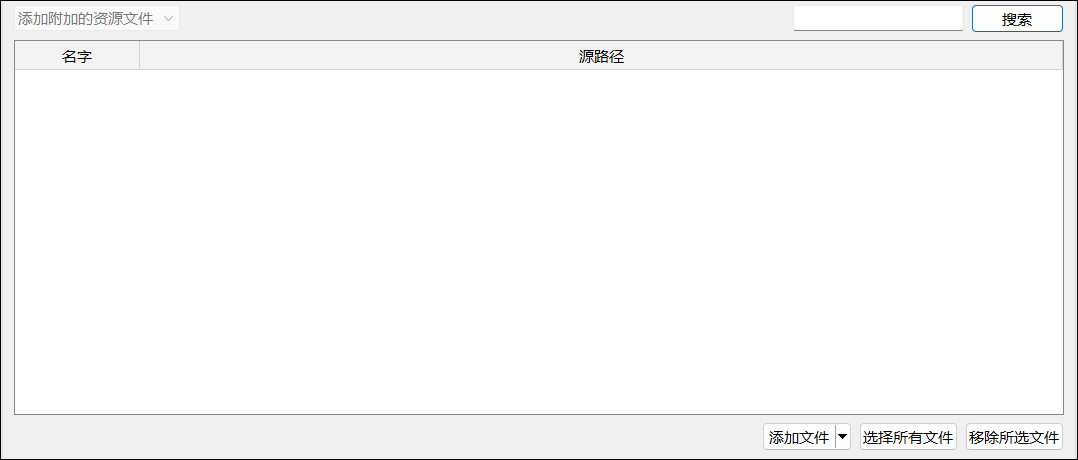
- 【添加文件】:打开文件资源管理器窗口,供用户选择需要添加的文件;
- 【选择所有文件】:一键选中列表中的所有文件;
- 【移除所选文件】:移除当前选中的文件。
# 保存位置
用户可自定义 FMU 文件的保存路径;若目标路径下已存在同名 FMU 文件,将被直接覆盖。

# 操作指南
# 模型准备
用户需首先在 Sysplorer 中完成模型的翻译与仿真,确保模型在当前仿真配置下能够成功翻译并运行,且仿真结果符合预期。
确保模型的输入与输出端口配置正确:
- 对于物理模型,应在模型顶层(即模型最外层)添加明确的输入与输出端口;
- 对于框图模型,若输入输出位于非顶层子系统中,需使用专用的端口组件(即
ExternalInport、ExternalOutport模块)将其显式暴露为模型的对外接口。
若对导出 FMU 的运行效率有较高要求,可在仿真设置的模型翻译选项卡中启用【参数估值】功能,以提升仿真效率。
# 配置导出选项
用户需确认所选的 FMU 版本、FMU 类型(Co-simulation 或 Model Exchange)以及平台位数(32 位 / 64 位)是否满足使用需求;
提示
有关 FMU 类型、位数配置错误导致的常见问题,请参见常见问题案例库。
对于运行效率要求较高的场景,建议在【运行效率】设置区中取消勾选相关选项,以避免不必要的性能开销;若需调试支持,可按需启用这些选项;
检查并确认积分算法的配置是否合理,满足仿真精度与稳定性要求;
根据实际需求,配置适当的导出模式;
如有必要,可添加附加资源文件;
指定导出的 FMU 文件保存位置。
# 导出失败问题
Sysplorer 导出 FMU 失败的常见原因及解决方法如下:
检查许可失败:当前 Sysplorer 软件尚未激活。报错弹窗示例如下:
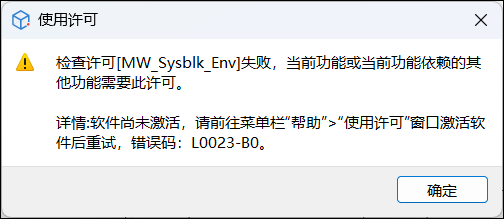
解决办法:请确保 Sysplorer 已完成激活。
模型翻译阶段报错:原始模型无法成功翻译,此类问题与 FMU 导出功能无关。报错信息示例如下:
正在解析模型... 正在实例化模型... Examples.Model4(6): 错误(3041): 组件引用 y 查找不到. 模型有 1 个错误和 0 个警告. ---- 检查发现错误终止 ---- 生成 FMU 失败!解决办法:请确保模型在当前仿真配置下可正确翻译并运行。
FMU 3.0 导出失败,在生成求解器阶段报错:FMU 3.0 基于 C99 标准,若使用的 C 编译器版本过低将导致模型翻译失败。报错信息示例如下:
生成求解器失败, 生成模型目标文件(.o文件或.obj文件未能生成, 错误码: 3.) 翻译模型失败!- 若使用
MSVC编译器,版本需为 Visual Studio 2015 或更高; - 若使用
GCC编译器,版本需为 4.5 或更高。
提示
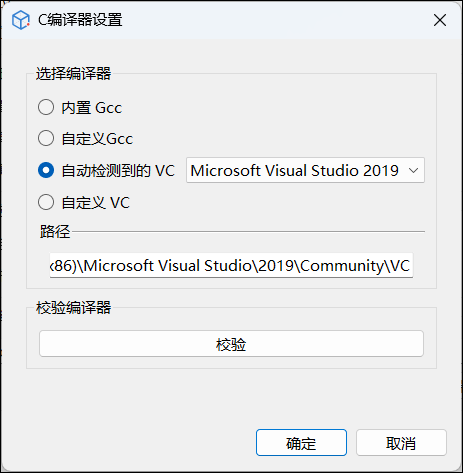
- 用户可在 Sysplorer 主页面顶部进入主页 > 选项 > C 编译器,设置编译器;
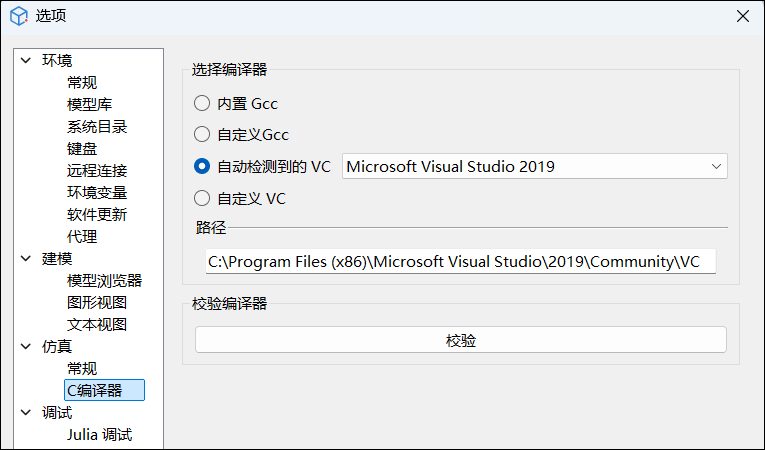
- 用户也进入主页 > 仿真设置 > 编译 > C 编译器设置中设置编译器:
- 若使用
生成求解器失败:若原模型名太长,导出 FMU 时会在生成求解器阶段失败:
生成求解器失败. 生成 MWSolver.dll 文件未能成功. 错误码: 4.解决办法:请缩短原模型名长度。
注意
Windows 和 Linux 对单个文件名和文件路径的最大长度均有限制(Windows:255 个字符;Linux:255 个字节);
当前 Sysplorer 导出 FMU 时会首先在系统的临时目录下生成 FMU 的动态库,例如
model1.dll。如果模型名太长,会导致动态库的名称或完整路径超过系统限制。
临时文件夹拒绝访问,生成 FMU 失败:导出工具在生成过程中需创建临时文件,若系统的临时目录(如
%TEMP%)为只读,将导致导出失败。报错信息示例如下:错误(9224): 创建临时文件夹 C:\Users\fengb\AppData\Local\Temp\Examples.Model4 时失败. 错误原因: 拒绝访问. 生成 FMU 失败!解决办法:请确保临时目录具有写入权限。
FMU 保存路径拒绝访问,生成 FMU 失败:若指定的 FMU 保存路径为只读或无写入权限,导出成功后无法拷贝文件至目标位置,也会导致模型导出失败。
---- 生成求解器完毕 ---- 错误(9223): 将目标文件 C:\Users\fengb\AppData\Local\Temp\Examples.Model4\Examples_Model4.fmu 拷贝到指定路径 C:\Users\fengb\Downloads\test\Examples_Model4.fmu 时失败. 错误原因: 拒绝访问. 生成 FMU 失败!解决办法:请确保 FMU 保存路径具有写入权限。
外部资源路径不存在:导出面板中指定的外部资源文件路径单击导出时已被删除,示例警告信息如下:
警告(9220): 外部资源路径C:/Users/fengb/Downloads/Snipaste_2025-07-15_19-08-44.png不存在. 生成 FMU 成功,文件位置:C:\Users\fengb\Downloads\test解决办法:请确保外部资源路径正确且存在。
# FMU 验证工具
# 功能介绍
当 Sysplorer 或其他仿真工具在集成 FMU 时出现问题,建议使用 FMPy 工具进行验证,以辅助定位和调试。
FMPy 是一款常用的 FMU 验证与调试工具,具备以下特性:
全面兼容 FMI 1.0/2.0/3.0 规范,支持 Model Exchange 与 Co-Simulation 两种模式;
跨平台支持(Windows/Linux/macOS),可直接解析 FMU 内部的模型描述文件(
modelDescription.xml),并提取变量、方程等元数据信息;提供 图形化界面 和 命令行界面 两种操作方式;
同时支持 FMU 验证 与 FMU 仿真。
注意
在 FMPy 中进行仿真时,FMU 以独立单体方式运行,其输入与输出信号不会与外部环境交互,主要用于验证 FMU 内部行为。
提示
有关 FMPy 的详细信息,请参见:
- FMPy Github 主页:FMPy: Simulate Functional Mock-up Units (FMUs) in Python (opens new window);
- FMPy 官方文档:Home - FMPy (opens new window);
- FMI 官网 FMU 验证工具集:Validate your FMUs (opens new window)。
# 操作指南
# FMU 导入
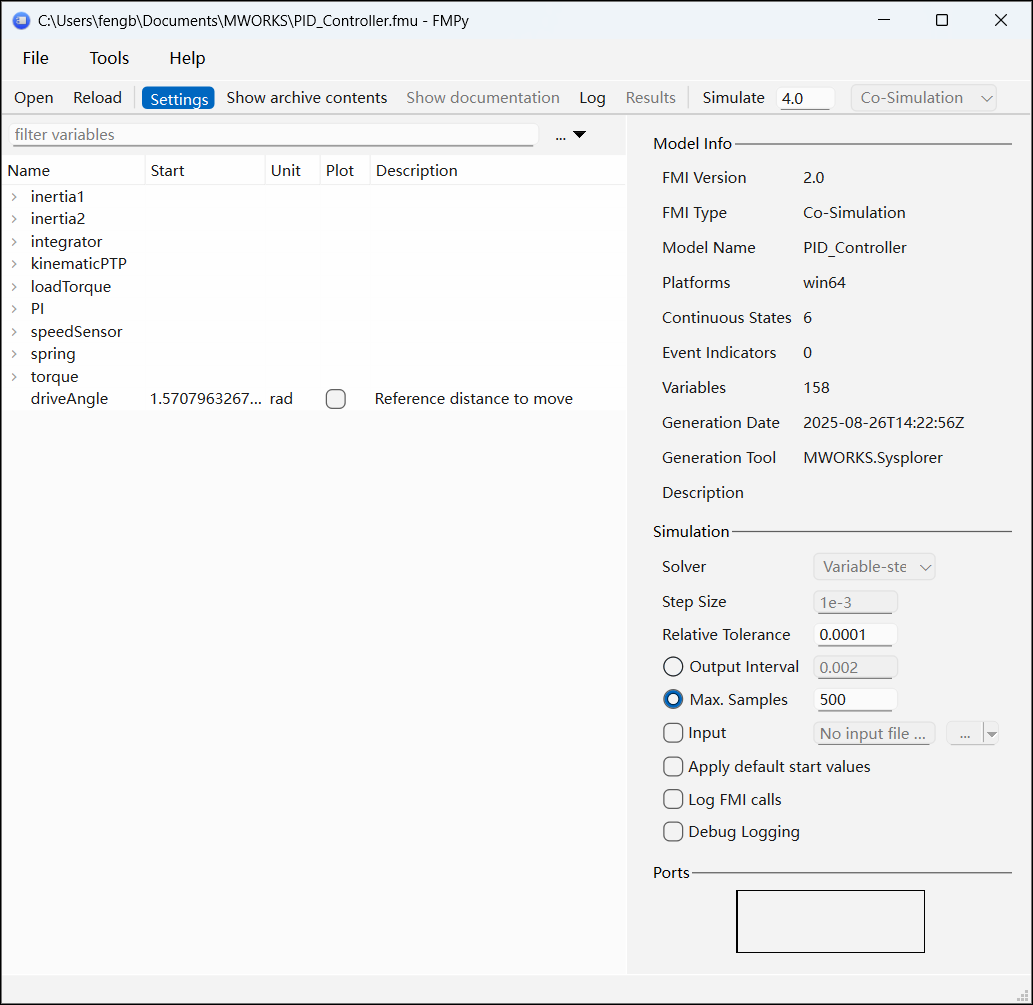
单击【Open】按钮,选择已准备好的 FMU,即可将其导入 FMPy。导入后,工具会自动解析并显示该 FMU 的基本信息。
# FMU 验证
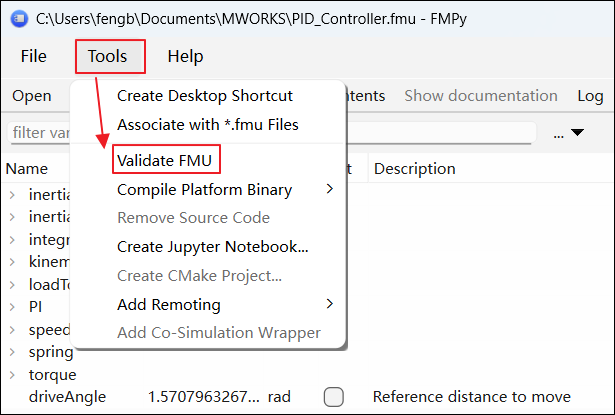
单击 Tools > Validate FMU 即可验证 FMU:
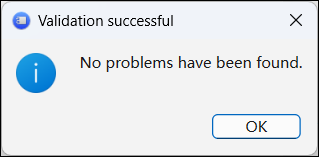
如果 FMU 验证成功,会弹窗提示:
如果 FMU 验证失败,会弹窗提示:
单击【Yes】即可将具体验证信息保存到文件中,便于进一步排查问题。
# FMU 仿真
FMU 验证通过后,还可以使用 FMPy 进行仿真。单击【Simulate】即可启动仿真;在左侧变量列表中勾选所需变量,右侧将显示对应的结果曲线。
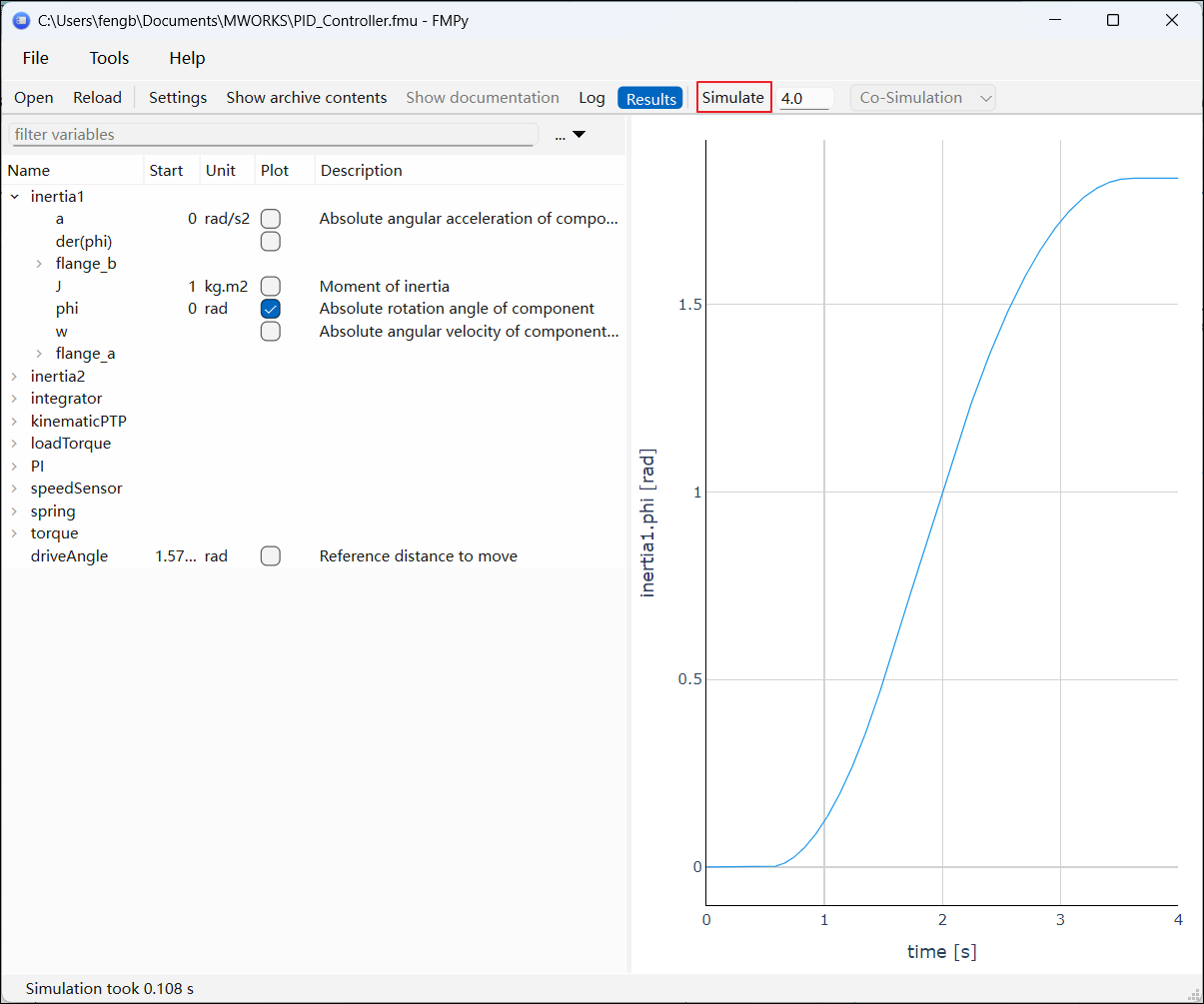
# 使用示例
以如下简单的框图模型为例:
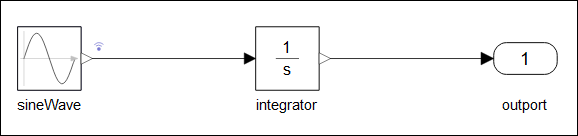
将其导出为 V2 Co-Simulation(64 位,完整导出)的 FMU 后,modelDescription.xml文件中将包含以下内容:
<ScalarVariable
name="sineWave.amplitude"
valueReference="144"
description="振幅"
variability="tunable"
causality="parameter"
initial="exact">
<Real start="1" />
</ScalarVariable>
其中,variability="tunable" causality="parameter"是可变性与因果性的合法组合。若手动将其修改为causality="input",则该组合变为非法。将此 FMU 导入 FMPy 时,将会直接报错:
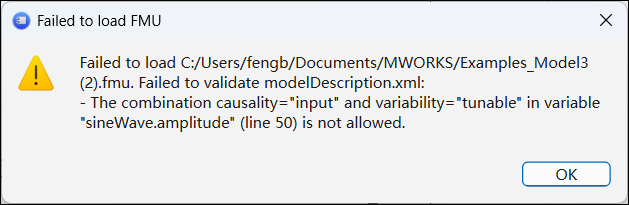
提示
可变性和因果性的合法组合,请参见 XML 文件结构。
# FMU 应用问题
# 模型问题
模型中使用绝对路径:如果原模型在引用外部资源时使用了绝对路径,导出 FMU 后在其他机器上仿真时,可能因找不到相应资源文件而报错。模型中引用外部资源时,应按照
Modelica URI规范给出相对路径。提示
有关
Modelica URI的详细信息,请参见:13.5 External Resources (opens new window)。模型拆分不合理:若强行将存在环路的模型拆分到不同的 Co-Simulation 类型 FMU,可能导致精度下降甚至数值不稳定,应谨慎处理模型分解。
模型事件过多:若模型中事件触发频率过高,导出的 FMU 在仿真时可能效率较低,应通过优化原模型以减少不必要的事件触发。
# 导出参数配置问题
CS 与 ME 仿真结果存在差异:由于 Co-Simulation (CS) 和 Model Exchange (ME) 使用的求解方式不同(CS 使用 FMU 内置求解器,ME 由外部仿真工具求解),在数值积分精度和步长处理方式上可能出现差异,导致仿真结果不一致。
对于对敏感性较高的模型,若导出 CS 类型的 FMU,结果很可能出现异常,建议优先选择导出 ME 类型的 FMU。
编译器优化差异:导出 FMU 时所用的 C 编译器优化策略可能与仿真时的运行环境存在差异,从而引发仿真问题。建议尝试调整编译器优化选项后重新导出 FMU。目前 Sysplorer 提供以下优化策略:
- 仿真效率优先:尽可能降低仿真运行耗时;
- 翻译效率优先:尽可能降低模型翻译耗时;
- 均衡模式:在仿真耗时与翻译耗时之间取得平衡。
平台兼容性问题:FMU 内部包含与平台相关的动态链接库(如
.dll、.so等),需针对目标操作系统进行编译。跨平台使用(例如在 Windows 与 Linux 之间)可能导致不可预期的问题。因此,FMU 不支持跨操作系统使用。此外,即使同为 Linux 系统,在一个发行版上导出的 FMU 也可能在其他发行版上存在兼容性差异。动态库位数与目标平台不匹配:FMU 内的动态链接库(如 Windows 平台的
.dll文件)必须与目标运行平台的位数一致(32 位或 64 位)。若位数不匹配,可能导致动态库无法加载。
提示
更多 FMU 应用问题请参见常见问题案例库。