# kstest
单样本 Kolmogorov-Smirnov 检验
函数库: TyStatistics
# 语法
h, p, ksstat, cv = kstest(x; CDF=[], alpha=0.05, tail="unequal")
# 说明
h, p, ksstat, cv = kstest(x; CDF=[], alpha=0.05, tail="unequal") 使用单样本 Kolmogorov-Smirnov 检验针对原假设返回检验决策,即向量 x 中的数据来自标准正态分布,而不是它不来自此类分布的备选方案。 如果检验在 5% 的显着性水平拒绝原假设,则结果 h 为 1,否则为 0。还返回假设检验的p值、检验统计量的值和检验ksstat的近似临界值cv,其中附加选项由一个或多个关键字参数指定。例如,您可以检验标准正态分布以外的分布、更改显着性水平或进行单侧检验。示例
# 示例
标准正态分布检验
加载数据。
using TyPlot
using TyStatistics
pkg_dir = pkgdir(TyStatistics)
source_path = pkg_dir * "/examples/HypothesisTests/DistributionTests/kstest_tests/kstest_data_1.jl"
include(source_path)
创建一个包含考试成绩数据第一列的向量。
test1 = grades[:,1]
检验数据来自均值为 75 且标准差为 10 的正态分布的原假设。使用这些参数来居中和缩放数据向量的每个元素,因为 kstest 默认测试标准正态分布。
x =@. (test1-75)/10
h, = kstest(x)
h = 0.0
h = 0.0 的返回值表示 kstest 在默认的 5% 显着性水平下未能拒绝原假设。
绘制经验 cdf 和标准正态 cdf 以进行视觉比较。
cdfplot(x)
hold("on")
x_values = LinRange(minimum(x),maximum(x),100)
plot(x_values,normcdf.(x_values,0,1),"r-")
legend(["Empirical CDF","Standard Normal CDF"],loc="best")
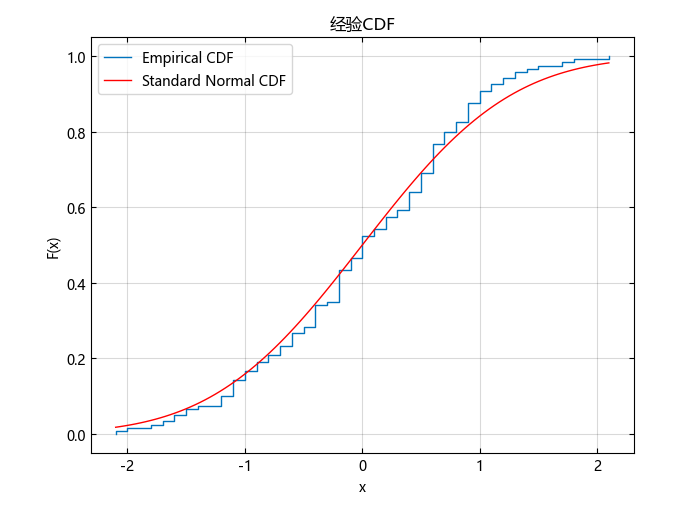
该图显示了中心和缩放数据向量的经验 cdf 与标准正态分布的 cdf 之间的相似性。
使用两列矩阵指定假设分布
using TyStatistics
pkg_dir = pkgdir(TyStatistics)
source_path = pkg_dir * "/examples/HypothesisTests/DistributionTests/kstest_tests/kstest_data_1.jl"
include(source_path)
创建一个包含学生考试成绩数据第一列的向量。
x = grades[:,1]
将假设分布指定为两列矩阵。 第 1 列包含数据向量 x。 第 2 列包含针对位置参数为 75、尺度参数为 10 和一个自由度的假设学生 t 分布在 x 中的每个值处评估的 cdf 值。
加载数据 test_cdf
import TyStatistics
pkg_dir = pkgdir(TyStatistics)
source_path = pkg_dir * "/examples/HypothesisTests/DistributionTests/kstest_tests/kstest_data_2.jl"
include(source_path)
测试数据是否来自假设分布。
h, = kstest(x,CDF=test_cdf)
h = 1.0
h = 1.0 的返回值表示 kstest 在默认的 5% 显着性水平下拒绝原假设。
进行单边假设检验
using TyPlot
using TyStatistics
pkg_dir = pkgdir(TyStatistics)
source_path = pkg_dir * "/examples/HypothesisTests/DistributionTests/kstest_tests/kstest_data_3.jl"
include(source_path)
创建一个包含股票收益数据矩阵第三列的向量。
x = stocks[:,3]
针对数据的总体 cdf 大于标准正态 cdf 的备择假设,检验数据来自标准正态分布的原假设。
h,p,k,c = kstest(x;tail="larger")
h = 1
p = 5.085438806199482e-5
k = 0.2197016793451303
c = 0.120673952773291
h = 1 的返回值表示 kstest 在默认的 5% 显着性水平下拒绝原假设而支持备择假设。
绘制经验 cdf 和标准正态 cdf 以进行视觉比较。
f,x_values = ecdf(x)
J = plot(x_values,f,linewidth=2)
hold("on")
K = plot(x_values,normcdf.(x_values),"r--",linewidth=2)
legend(["Empirical CDF","Standard Normal CDF"],loc="southeast")
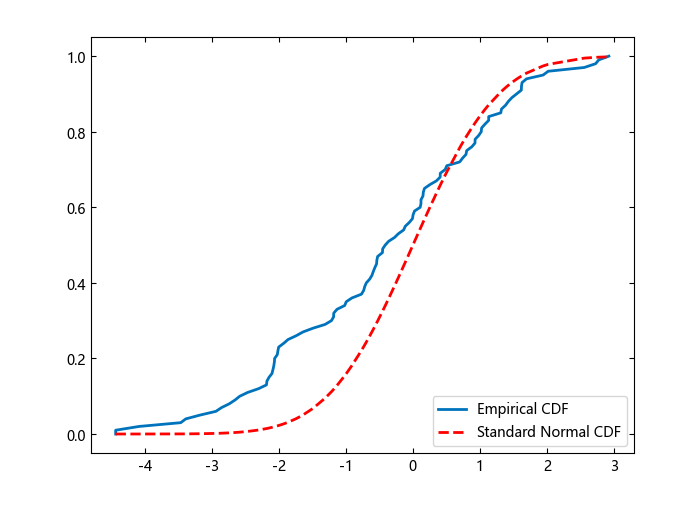
该图显示了数据向量 x 的经验 cdf 与标准正态分布的 cdf 之间的差异。
# 输入参数
x —— 样本数据
向量
数据类型: Float32 | Float64 | Int8 | Int16 | Int32 | Int64 | Int128 | UInt8 | UInt16 | UInt32 | UInt64 | UInt128
CDF — 假设连续分布的 cdf
矩阵 | 概率分布对象
单样本 Kolmogorov-Smirnov 检验仅对连续累积分布函数有效,需要预先确定 CDF。如果根据数据估计 CDF,则结果不准确。要在不指定分布参数的情况下根据正态分布、对数正态分布、极值分布、Weibull 分布或指数分布检验 x,请改用 lillietest。
数据类型: Float32 | Float64 | Int8 | Int16 | Int32 | Int64 | Int128 | UInt8 | UInt16 | UInt32 | UInt64 | UInt128
alpha - 显着性水平
0.05(默认) | 范围 (0,1) 中的标量值
示例: alpha=0.01
数据类型: Float32 | Float64 | Int8 | Int16 | Int32 | Int64 | Int128 | UInt8 | UInt16 | UInt32 | UInt64 | UInt128
tail - 替代假设的类型
"unequal" (默认) | "larger" | "smaller"
| "unequal" | 检验替代假设,即从中提取 x 的总体的 cdf 不等于假设分布的 cdf。 |
| "larger" | 检验替代假设,即从中抽取 x 的总体的 cdf 大于假设分布的 cdf。 |
| "smaller" | 检验替代假设,即从中提取 x 的总体的 cdf 小于假设分布的 cdf。 |
如果数据向量 x 中的值往往大于假设分布的预期值,则 x 的经验分布函数往往较小,反之亦然。
示例: tail="larger"
# 输出参数
h - 假设检验结果
1 | 0
如果 h = 1,这表示在 alpha 显着性水平拒绝零假设。
如果 h = 0,则表示未能在 alpha 显着性水平拒绝原假设。
p — p 值
[0,1] 范围内的标量值
ksstat - 测试统计
非负标量值
cv - 临界值
非负标量值
# 详细信息
单样本 Kolmogorov-Smirnov 检验
"unequal"累积分布函数的双侧检验针对备选方案(即数据的总体 cdf 不等于假设的 cdf)检验原假设。 检验统计量是根据 x 计算的经验 cdf 与假设 cdf 之间的最大绝对差值:
其中
"larger" 累积分布函数的单侧检验针对数据的总体 cdf 大于假设 cdf 的备选方案检验原假设。 检验统计量是根据 x 计算的经验 cdf 超过假设 cdf 的最大量:
"smaller" 累积分布函数的单侧检验针对数据的总体 cdf 小于假设 cdf 的备选方案检验原假设。 检验统计量是假设的 cdf 超过从 x 计算的经验 cdf 的最大量:
kstest 使用近似公式或通过在表中插值来计算临界值 cv。 公式和表格涵盖范围 0.01 ≤ alpha ≤ 0.2(双侧测试)和 0.005 ≤ alpha ≤ 0.1(单侧测试)。 如果 alpha 超出此范围,则 cv 返回为 NaN。
# 算法
kstest 决定通过将 p 值 p 与显着性水平 alpha 进行比较来拒绝零假设,而不是通过将检验统计量 ksstat 与临界值 cv 进行比较。 由于 cv 是近似值,将 ksstat 与 cv 进行比较有时会得出与将 p 与 alpha 进行比较不同的结论。