# 流形学习算法对比
这是一个展示使用不同流形学习方法在 S 形曲面数据集上进行降维的示例。在本案例中,使用流形学习算法对数据降维,同时保留数据点之间的关系,达到展开数据集的效果,本案例使用的流形学习方法包括:
- Locally Linear Embeddings
- Standard
- LTSA
- Hessian
- Modified
- Isomap Embedding
- Multidimensional scaling
- Spectral embedding for non-linear dimensionality reduction
- T-distributed Stochastic Neighbor Embedding
# 实验准备
# 数据准备
首先,我们从机器学习工具箱中导入 S Curve 数据集。
using TyMachineLearning
S_points, S_color = get_curve() # 获取数据集
使用图形工具箱对数据集进行可视化:
using TyPlot
scatter3(S_points[:, 1], S_points[:, 2], S_points[:, 3], c=S_color, s=50, filled=true)
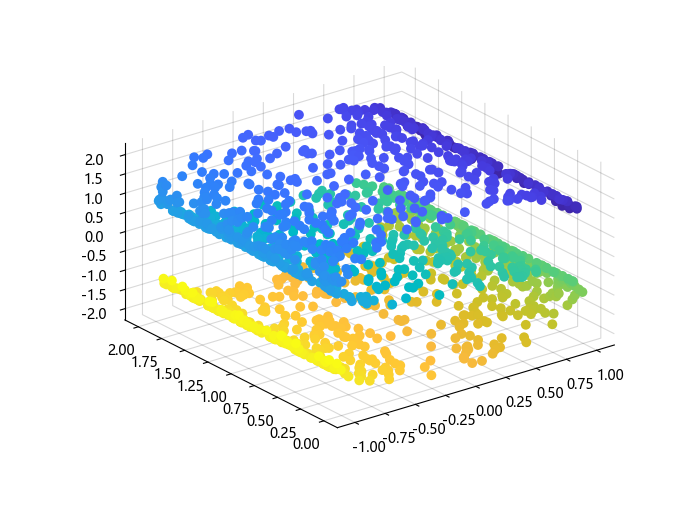
可以看到,我们的数据集呈现出一个 S 型曲面的形状,其中的数据点在不同的地方有着不一样的密度分布。
# 绘图工具准备
在本实验中,绘制的图形较多,为了更方便地进行绘图,我们定义一个函数来调用图形工具箱内的 scatter 二维散点图工具,来简化绘图的过程:
"""
plot_2d(data, fig, fig_title): 使用 TyPlot 绘制降维后的 2D 散点图
args:
data: 用于绘图的 2D 数据
fig: 用于绘图的画布
fig_title: 图标题
sub_pos(optional): 子图位置(横向数量,纵向数量,第 i 个子图)
"""
function plot_2d(data, fig, fig_title; sub_pos=(0, 0, 0))
if sub_pos != (0, 0, 0)
subplot(sub_pos[1], sub_pos[2], sub_pos[3])
end
figure(fig)
scatter(data[:, 1], data[:, 2]; c=S_color, s=50, filled=true)
title(fig_title)
return true
end
# 定义流形学习模型
流形学习是一种非线性降维的方法。用于此任务的算法基于这样一个思想:许多数据集的维度只是人为地被提高了,其实其数据之间存在更低维的数据关系。
# Locally Linear Embeddings
局部线性嵌入(LLE)可以被认为是一系列局部主成分分析,它们在全局进行比较,以找到最佳的非线性嵌入。本例中将要测试 4 种不同的 LLE 模型,因此,我们首先定义一个函数来创建这 4 种模型,该函数返回一个字典,该字典包括了 4 种模型计算的不同结果:
"""
build_lle_models(data): 使用 4 种 LLE 模型拟合输入数据,返回降维后的结果。
args:
data: 输入的数据,用于 mainfold 模型计算
return:
返回一个字典,包含了例子用到的四个模型返回的降维之后的数据
Dict(
"lle_standard" => lle_standard,
"lle_ltsa" => lle_ltsa,
"lle_hessian" => lle_hessian,
"lle_mod" => lle_mod,
)
"""
function build_lle_models(data)
# 定义一个函数来构建并训练 4 种 LLE 模型
print("-> Computing standard...\n")
sd_embedding, ev = fitLocallyLinearEmbedding(data; n_neighbors=12, eigen_solver="auto")
lle_standard = sd_embedding.embedding_
print("-> Computing ltsa...\n")
lle_ltsa = fitltsaEmbedding(data).fit_transform(data)
print("-> Computing hessian...\n")
lle_hessian = fitHessianEigenmapping(data).fit_transform(data)
print("-> Computing modified...\n")
lle_mod = fitMLLEmbedding().fit_transform(data)
return Dict(
"lle_standard" => lle_standard,
"lle_ltsa" => lle_ltsa,
"lle_hessian" => lle_hessian,
"lle_mod" => lle_mod,
)
end
接下来,我们调用这个函数,得到 4 个 LLE 模型的计算结果:
# 使用 LLE 模型对数据进行降维
lle_models = build_lle_models(S_points)
在得到计算结果后,使用前面我们定义的 plot_2d 函数绘制图像,对计算结果进行可视化。此处我们使用循环结构,对结果字典中的各个模型结果进行遍历,再在每次循环中调用 plot_2d 函数绘制各个模型的可视化结果:
fig = figure(; figsize=[7.4, 5.8])
global position = 0 # 用于确定子图位置
for key in keys(lle_models)
global position += 1
plot_2d(lle_models[key], fig, key; sub_pos=(2, 2, position))
end
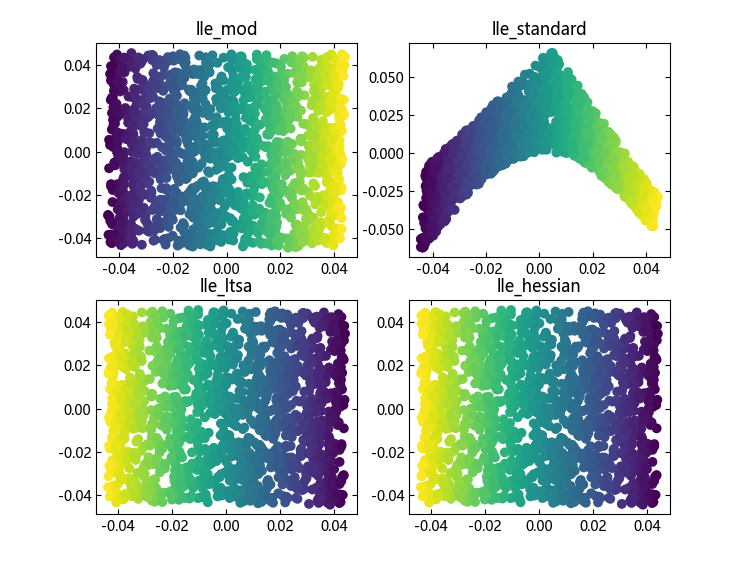
# Isomap Embedding
通过等距映射进行非线性降维。Isomap 寻求一个低维嵌入,保持所有点之间的测地距离。现在,我们使用机器学习工具箱中的 Isomap 模型对数据进行降维:
# 使用 Isomap 模型对数据进行降维
print("-> Computing isomap...\n")
isomap_embedding, isomap_ev = fitIsomap(S_points)
isomap_result = isomap_embedding.embedding_
plot_2d(isomap_result, figure(), "Isomap Embedding")
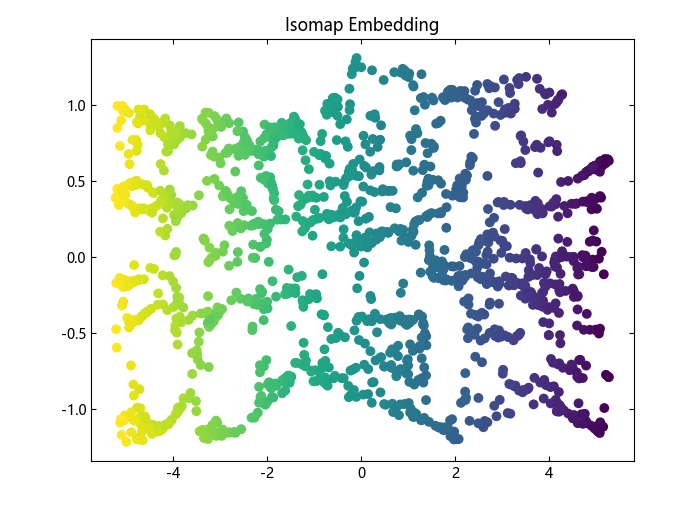
# Multidimensional scaling
多维缩放(MDS)寻求数据的低维表示,使得距离尽可能地保持原始高维空间中的距离。通常,MDS 是一种用于分析相似性或差异性数据的技术。
# 使用 MDS 模型对数据进行降维
print("-> Computing MDS...\n")
mds_embedding, ts = cmdscale(S_points)
mds_result = mds_embedding.fit_transform(S_points)
plot_2d(mds_result, figure(), "MDS Embedding")

# Spectral embedding for non-linear dimensionality reduction
这个实现使用拉普拉斯特征映射,它通过对图拉普拉斯算子进行谱分解,找到数据的低维表示。
# 使用 Spectral 模型对数据进行降维
print("-> Computing spectral...\n")
spectral_embedding = fitSpectralEmbedding("nearest_neighbors")
spectral_result = spectral_embedding.fit_transform(S_points)
plot_2d(spectral_result, figure(), "Specture Result")
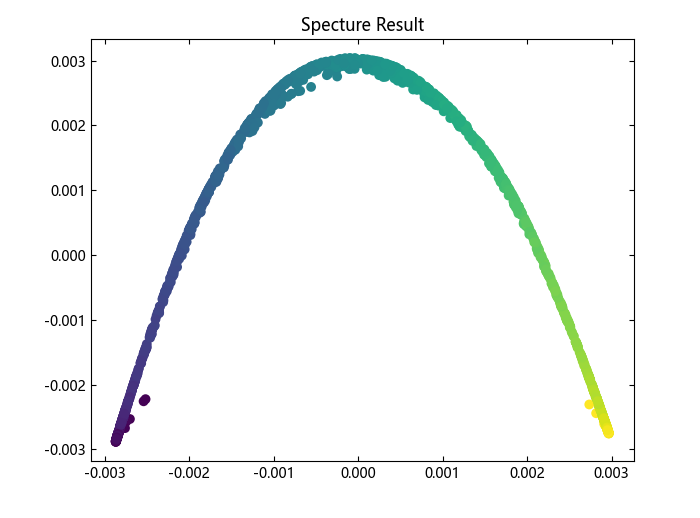
# T-distributed Stochastic Neighbor Embedding
它将数据点之间的相似性转换为联合概率,并试图最小化低维嵌入和高维数据的联合概率之间的 Kullback-Leibler 散度。t-SNE 有一个非凸的代价函数,即不同的初始化会得到不同的结果。
# 使用 tsne 模型对数据进行降维
print("-> Computing tsne...\n")
tsne_embedding = tsne(; init="random")
tsne_result = tsne_embedding.fit_transform(S_points)
plot_2d(tsne_result, figure(), "t-SNE Result")
由于函数运行过程中存在随机性,因此上述模型降维效果可能会略有差异。