# 2026a V26.1 发行说明
发行时间:2026-02-06
更新与修复:
- V26.1.1:此更新修复若干个缺陷,交互式编程环境优化若干项改进,科学计算函数库优化 21 个函数库及若干个函数,科学计算 APP 优化 3 个 APP。
- V26.1.2:此更新修复 1 个 License 激活缺陷。
V26.1 版本交互式编程环境优化了 IDE、调试、Julia 打包部署、Julia 内核、绘图、APP Designer、代码生成、Copilot 插件、M 导入工具、帮助文档、安装包等多个模块;科学计算函数库优化了 21 个函数库及若干个函数;科学计算 APP 新增了信号分析器工具,优化了曲线拟合、滤波器可视化、滤波器设计 3 个 APP。
# 新增功能
# 交互式编程环境
IDE 界面改进
- 新增内存监测工具,实时监控内存占用情况;
- 语句块 end 关键词导航功能、缺失检查和快速修复;
- Julia 脚本默认开启“粘滞滚动”功能,语句块的头部会停滞在编辑器顶部,方便识别和跳回语句块头部位置;
- 文档高亮:语句块的任意一个关键词(如 if、else、end)在光标悬停时会高亮所有其他的关键词,方便定位语句块的完整范围;
- 跳转定义:在 end 关键词上使用“Ctrl + 鼠标左键”或右键菜单单击“转到定义”可跳转至语句块的头部;
- 根据用户当前代码缩进情况,精确检查和补充语句块缺失的“end”关键词。
- 编码助手新增 720 个 TyBase(语言基础函数库)、588 个 TyMath(数学基础函数库)、338 个 TyStatistics(统计工具箱)、72 个 TyCurveFitting(曲线拟合工具箱)、291 个 TySignalProcessing(信号处理工具箱) 、176 个 TyDSPSystem(DSP 系统工具箱)、294 个 TyCommunication(通信工具箱)、176 个 TyControlSystems(控制系统工具箱)、85 个 TyRobustControl(鲁棒控制工具箱)、70 个 TySystemIdentification(系统辨识工具箱)、266 个 TyImageProcessing(图像处理工具箱)等签名帮助(Signature Help)功能,共计 3076 个函数的用法及参数帮助信息;
- 新增无类型空向量的检查项(如 a = []),提示用户需要给空向量指定类型(如 a = Float64[]),防止用户无意中引入类型不稳定的容器;
- 完善语句块折叠范围(folding range)功能,支持顶格编写 module 代码能够正确的折叠;
- 代码编辑器支持快速查找已打开的文件;
- 提供函数的文档注释(docstring)模板,能更便捷地编辑函数、位置参数、关键词参数、返回值、函数示例等描述,使用快捷键 Tab 键或 Shift + Tab 键跳转下一个或上一个模板位置;
- 工作区及调试工作区支持搜索结构体及字典变量的字段;
- 资源管理器的字体支持配置;
- 资源管理器增加横向滚动条以查看文件全名;
- 支持在 Windows 系统资源管理器中双击打开 syslabfig 文件;
- 首选项新增“格式化时支持删除多余空行”配置;
- 首选项新增“Julia 代码在编辑模式下启用数据提示”,支持编辑模式中,在 Julia 代码中鼠标悬停在变量上,显示该变量在工作区中的值;
- 首选项新增代理设置功能;
- 状态栏新增线程数提示,代码编辑时多线程相关代码如 @threads 新增线程数提示;
- 表格视图支持复制导入 excel 表格的数据;
- 变量视图表格支持跟随主题切换;
- 完善起始页,增加“新建”、“示例”、“学习”快速引导 tab 页;
- 差异编辑器增加支持忽略所有行内空格的配置项;
- 性能分析报告页面火焰图增加朝向配置,支持导出成 .syslabProf 格式。
调试功能改进
- ★支持使用 @debug_func 调试指定函数;
- ★新增调试节;
- 修复了调试运行时,因在调试控制台执行代码引发终端报错而导致调试功能不可用的问题;
- 修复加载函数库和调用宏连在一起时,调试报错的问题;
- 右键文件增加运行和调试选项;
- 调试控制台的历史记录支持显示包括评估在内的全部语句;
- 调试断点的条件表达式输入提示优化;
- 调试器设置中,增加一键勾选设置为编译模式、解释模式功能;
- Julia 调试时,对于包含 *、&、\、⊻、∉ 操作符的表达式,鼠标悬停显示由表达式的值修改为当前变量的值。如 var=var1*var2,鼠标悬停至 var2 时,修改前显示 var1*var2 运算结果,修改后显示 var2 值;
- 性能优化:对 Base 标准库函数直接调用(跳过 invokelatest)以提升性能,部分场景性能提升 30%;
- 性能优化:若函数内部没有断点,则自动启用编译模式;
- 调试控制台输入框支持自动换行。
★Julia 打包部署
新增 Syslab AppBundler,支持将 Julia 代码打包为独立应用程序或动态库。
Julia 内核改进
- 修复了两种场景下因堆栈溢出导致的 Julia 终端报错或崩溃问题;
- 修改了内存管理的启发式算法,缩小了 GC 的周期间隔,并减少了 Full GC 的频率,在大型工程可以降低 30% 的峰值内存;
- 合并上游的增强补丁,修改了 GC 管理的数组对象池,优化释放数组时的时空局部性;
- 修复多线程环境下中断后,多线程状态管理错误导致 @thread :static 无法再运行的错误。
APP Designer 功能改进
- ★新增网格布局,自适应已有组件;
- 坐标区组件新增降采样功能;
- 表格组件支持下拉框编辑;
- 表格新增行名;
- 新增 uiputfile 函数。
绘图功能改进
- ★支持双游标功能;
- 支持插入图形、文本框的复制粘贴;
- 支持游标功能与数据提示功能同时使用;
- 支持设置图例位于坐标轴之外;
- 优化坐标轴指数显示效果;
- 保存 EPS 格式图片的字体为 type1 格式;
- 修复多线程绘图崩溃问题,改为警告并忽略多线程绘图代码;
- surf 图形支持按照坐标区范围裁剪对象;
- 优化了对数坐标轴部分场景次网格显示规则;
- ★云化绘图弹窗列表新增筛选、缩略图功能。
Syslab 代码生成功能改进
- ★支持拆分生成的 C++ 代码,Makefile 可通过并行构建优化 C++ 代码的构建时间,在测试工程中,C++ 代码的编译时间由 26 分钟下降至 3 分钟;
- 支持 Makefile 兼容 powershell;
- 优化了 all(A::BitMatrix;dims=2) 和 any(A::BitMatrix;dims=2) 在大矩阵上的性能。以 10 万 × 10 万 的 BitMatrix 矩阵为例,Julia 耗时:18.29s(首次运行), 17.785s (第 2 次运行); 代码生成耗时:2.352s(首次运行), 2.097s(第 2 次运行);
- 优化了并行编译选项 (--njobs) 的文件拆分策略,确保生成的编译单元(C++ 文件)在编译复杂度上尽可能均衡。减少了各编译线程间的等待时间,尽可能使得整体编译耗时由原先受限于最慢的单个文件,转变为更均衡的并行执行
- 新增 --use-cache 编译选项,引入缓存机制加速大型 Julia 文件代码生成,在内部测试环境上,代码生成时间平均约减少 23.68%;
- 更新代码生成支持生成的 Syslab 科学计算函数列表用户帮助文档,初等数学新增 9 个(add,ellipticE,ellipticF,ellipticK,ellipticPi,fresnels,polyval,ratstr,sub),线性代数新增 2 个(orth,subspace),稀疏矩阵新增 5 个(colamd,full,spdiagm,symamd,unmesh),数值积分和微分方程新增 1 个(quadgk),信号处理新增 10 个(bitrevorder,cheby1,chirp,ellipap,finddelay,impinvar,poly2lsf,seqperiod,tf2zpk,vco)。
Copilot 插件改进
- 提供基于语言的补全状态提示,支持 julia、matlab、python、markdown 多种语言补全状态管理;
- 针对当前文件的语言进行补全状态提示,可选择启用/禁用当前语言的代码补全;
- 提供四种补全状态:当前文件补全禁用状态、全局补全关闭状态、当前文件语言不支持、补全开启状态。
- 编辑器右键菜单新增代码文档生成、代码单元测试生成两个快捷指令,可快速为选中代码进行文档生成/单元测试生成;
- 代码文档生成快捷指令:可对选中的代码快速进行文档生成;
- 单元测试生成快捷指令:可对选中的代码快速生成单元测试。
- 允许用户主动添加上下文进行问答,支持的上下文类型:文件、文件夹、诊断信息、图片、终端上下文以及选中代码片段作为上下文;
- 文件类型上下文:通过 @ 的方式,可以选择文件作为上下文;
- 文件夹类型上下文:通过 @ 按钮的方式可以选择 文件夹 作为上下文;
- 诊断信息上下文:通过 @ 按钮的方式可以添加文件的诊断信息作为上下文;
- 图片上下文:提供两种方式添加图片上下文;
- 终端上下文:终端选中内容,点击右上角的“添加至 AI 上下文”,即可将终端内容作为上下文进行添加;
- 编辑器选中代码上下文:编辑器选中代码块,右键选择“添加至 AI 上下文”,即可将选中的代码块作为上下文添加。
- 用户消息添加附件,可以了解每一轮对话使用的上下文;
- 内置知识库搜索与文件读取工具,使 Copilot 更加智能。
- 提供基于语言的补全状态提示,支持 julia、matlab、python、markdown 多种语言补全状态管理;
M 导入工具改进
- ★M 工作区变量支持绘图功能;
- ★M 兼容支持 profile 功能;
- ★新增稀疏矩阵相关函数或功能,包括
- 创建:sparse, spconvert, sprand, sprandn, speye, spdiags, spalloc, sprandsym
- 操作:issparse, nnz, nonzeros, nzmax, spy, full, spfun, spones
- 重排序算法:amd, colamd
- 迭代法和预条件子:pcg, lsqr, minres, symmlq, gmres, bicg, bicgstab, bicgstabl, cgs, qmr, tfqmr
- 结构分析:etreeplot, treelayout, treeplot, gplot, unmesh
- M 兼容搜索路径优先当前工作目录;
- 关键词解析支持 Name = Value 语法;
- 支持 Julia 和 M 工作区所有变量导入导出(不需要逐个输入变量名);
- 优化了 kron 的性能,时间从 0.3 s 降低至 0.1 s;
- 优化了 dlmread 读取大数据(800w*13)的性能,时间从 80~90 s 降低至 20~30 s;
- 完成 M 兼容全部已发布函数(2033 个)入参检查;
- 新增 52 个 M 函数,当前共提供 2033 个 M 函数及帮助文档。
帮助文档改进
- 新增 61 个综合示例,共提供 273 个综合示例;
- 新增源代码管理器操作帮助文档,详情参见源代码管理器;
- 新增 Julia 调用 C/C++ 动态库示例,详情参见调用自定义 C/C++ 动态库。
安装包改进
安装包启动时增加磁盘空间检测功能。
# 科学计算函数库
# 功能优化
基础工具箱
数学、统计和优化
信号处理和无线通信
控制系统
图像处理和计算机视觉
图像处理工具箱新增 1 个函数,改进 30 个函数。
AI 与数据科学
代码生成
定点工具箱增加中英文报错国际化处理。
# 性能优化
| 函数库 | 优化函数 | 优化前/s | 优化后/s | 优化后/优化前 | 备注 |
|---|---|---|---|---|---|
| 基础 | ty_unique | 9.31 | 5.12 | 0.55 | / |
| 基础 | ty_unique | 运行卡死 | 0.48 | / | nargout=2 |
| 基础 | ty_unique | 8.03 | 3.48 | 0.433 | 字符串数组 |
| 基础 | strfind | 5.292E-02 | 3.12E-03 | 0.059 | / |
| 基础 | strfind | 8.09 | 0.51 | 0.063 | / |
| 基础 | fscanf | 5.67 | 0.083 | 0.015 | 400W 数据量 |
| 基础 | delete | 2.91 | 1.68 | 0.577 | 1W 数据量 |
| 基础 | array2table | 8.01 | 5.59 | 0.698 | 4000W*4 数据量 |
| 图形 | semilogx | 4.675 | 1.817 | 0.389 | / |
| 数学 | nufft | 3.25 | 0.13 | 0.04 | / |
| 数学 | nufft | 3.33 | 0.14 | 0.042 | / |
| 数学 | nufft | 3.34 | 0.19 | 0.057 | / |
| 数学 | filter1 | 62.88 | 37.11 | 0.59 | / |
| 数学 | isbanded | 1.39 | 0.004 | 0.003 | / |
| 数学 | griddata | 13.14 | 0.97 | 0.074 | linear 算法 |
| 数学 | griddata | 37.74 | 8.37 | 0.222 | cubic 算法 |
| 数学 | griddata | 5.66 | 1.22 | 0.216 | boundary 算法 |
| 数学 | interp1 | 0.402069 | 0.204279 | 0.508 | pchip 算法,2000w 数据量 |
| 数学 | interp1 | 21.27 | 2.93 | 0.138 | spline 算法 |
| 数学 | interp2 | 5.00 | 1.18 | 0.236 | spline 算法 |
| 数学 | interp2 | 0.021797 | 0.0077543 | 0.356 | cubic 算法,100w 数据量 |
| 数学 | interp2 | 0.0752287 | 0.0093791 | 0.125 | linear 算法,400w 数据量 |
| 数学 | interp3 | 2.4666 | 0.110469 | 0.045 | cubic 算法,2000w 数据量 |
| 数学 | interp3 | 0.278608 | 0.235736 | 0.846 | nearest 算法,2000w 数据量 |
| 数学 | padecoef | 2.95182 | 1.55652 | 0.527 | / |
| 数学 | pchip | 1.62353 | 0.981722 | 0.605 | 1500w 数据量 |
| 数学 | delaunay | 3.3267 | 0.626315 | 0.188 | 30w 数据量 |
| 数学 | conv2 | 176.96 | 8.87 | 0.05 | / |
| 优化 | fmincon | 1.39 | 1.26 | 0.906 | / |
| 优化 | fminunc | 7.52 | 4.25 | 0.565 | / |
| 优化 | quadprog | 1.28 | 0.86 | 0.672 | active-set 算法 |
| 优化 | quadprog | 8.14 | 6.75 | 0.829 | trust-region-reflective 算法 |
| 优化 | lsqlin | 2.69 | 1.89 | 0.703 | active-set 算法 |
| 优化 | lsqlin | 25.01 | 6.97 | 0.279 | trust-region-reflective 算法 |
| 优化 | fminsearch | 1.28 | 0.54 | 0.422 | / |
| 全局优化 | paretosearch | 8.07 | 0.02 | 0.002 | / |
| 全局优化 | paretosearch | 208.34 | 0.62 | 0.003 | / |
| 曲线拟合 | excludedata | 0.397108 | 0.0936431 | 0.236 | box 方法 |
| 曲线拟合 | excludedata | 1.42 | 0.31 | 0.218 | domain 方法 |
| 曲线拟合 | excludedata | 1.81 | 0.31 | 0.171 | range 方法 |
| 曲线拟合 | prepareCurveData | 3.17 | 0.54 | 0.17 | / |
| 曲线拟合 | category | 1.24 | 0.004 | 0.003 | / |
| 曲线拟合 | prepareSurfaceData | 3.33 | 0.82 | 0.246 | / |
| 曲线拟合 | numargs | 3.18 | 0.02 | 0.006 | / |
| 曲线拟合 | islinear | 1.94 | 0.008 | 0.004 | / |
| 曲线拟合 | typecur | 2.66 | 0.04 | 0.015 | / |
| 曲线拟合 | fittype | 13.26 | 1.07 | 0.081 | / |
| 曲线拟合 | dependnames | 0.04 | 0.03 | 0.75 | / |
| 曲线拟合 | indepnames | 0.04 | 0.01 | 0.25 | / |
| 曲线拟合 | probnames | 1.57 | 0.50 | 0.318 | / |
| 曲线拟合 | coeffnames | 0.16 | 0.08 | 0.5 | / |
| 曲线拟合 | typecur | 0.006 | 0.003 | 0.5 | / |
| 曲线拟合 | formula | 5.20 | 2.51 | 0.483 | / |
| 曲线拟合 | fit | 48.67 | 0.47 | 0.01 | / |
| 曲线拟合 | numcoeffs | 9.69 | 2.79 | 0.288 | / |
| 曲线拟合 | integrate | 1.67 | 0.01 | 0.006 | / |
| 统计 | gamfit | 2.20 | 0.70 | 0.318 | / |
| 统计 | gamlike | 1.81 | 0.91 | 0.503 | / |
| 统计 | fitdist | 20.89 | 0.64 | 0.031 | Rician 分布拟合 |
| 统计 | fitdist | 28.46 | 0.37 | 0.013 | Gamma 分布拟合 |
| 统计 | fitdist | 1.47 | 0.40 | 0.272 | Nakagami 分布拟合 |
| 统计 | fitdist | 13.53 | 1.27 | 0.094 | kernel 分布拟合 |
| 统计 | fitdist | 1.24 | 0.61 | 0.492 | ExtremeValue 分布拟合 |
| 统计 | fitdist | 2.79 | 1.85 | 0.663 | Weibull 分布拟合 |
| 统计 | fitdist | 6.73 | 1.53 | 0.227 | GeneralizedExtremeValue 分布拟合 |
| 统计 | fitdist | 2.52 | 1.25 | 0.496 | HalfNormal 分布拟合 |
| 统计 | fitdist | 5.99 | 1.27 | 0.212 | Rayleigh 分布拟合 |
| 统计 | fitdist | 1.58 | 1.38 | 0.873 | LogNormal 分布拟合 |
| 统计 | fitdist | 4.14 | 0.64 | 0.155 | Loglogistic 分布拟合 |
| 统计 | mle | 10.55 | 1.10 | 0.104 | Rician 分布进行 |
| 统计 | mle | 1.16 | 0.53 | 0.457 | Gamma 分布进行 |
| 统计 | mle | 3.72 | 1.66 | 0.446 | Nakagami 分布进行 |
| 统计 | mle | 2.11 | 0.92 | 0.436 | LogNormal 分布进行 |
| 统计 | mle | 6.06 | 0.97 | 0.16 | Loglogistic 分布进行 |
| 统计 | cdf | 2.74 | 0.13 | 0.047 | / |
| 统计 | 3.04 | 0.93 | 0.306 | / | |
| 统计 | paretotails | 0.93 | 0.73 | 0.785 | / |
| 统计 | boundary | 1.91 | 0.0007 | 3.66E-04 | / |
| 统计 | nsegments | 5.16 | 0.80 | 0.155 | / |
| 统计 | random | 1.64 | 0.0008 | 4.87E-04 | / |
| 统计 | gpfit | 3.28 | 0.47 | 0.143 | / |
| 统计 | ncx2pdf | 2.77 | 0.28 | 0.101 | / |
| 统计 | unifit | 17.35 | 1.74 | 0.1 | / |
| 统计 | chi2gof | 12.75 | 1.32 | 0.104 | / |
| 统计 | movmad | 7.73005 | 0.98692 | 0.128 | 10000*10000 数据量 |
| 信号 | thd | 2.34E-03 | 2.21E-03 | 0.944 | / |
| 信号 | snr | 5.56E-05 | 2.55E-05 | 0.459 | / |
| 信号 | sfdr | 4.213E-06 | 1.270E-06 | 0.301 | / |
| 信号 | firls | 3.56E-02 | 5.35E-03 | 0.150 | / |
| 信号 | medfilt1 | 3.223 | 2.87E-02 | 0.009 | 1e6 量级数据,1000 窗长 |
| 通信 | block_decode | 1.990E-05 | 1.140E-05 | 0.573 | / |
| 通信 | syndtable | 4.786E-06 | 1.780E-06 | 0.372 | / |
| 通信 | muxintrlv | 1.023E-05 | 3.0536E-07 | 0.03 | / |
| 通信 | muxdeintrlv | 8.30E-06 | 3.61E-07 | 0.043 | / |
| 通信 | convintrlv | 3.487 | 5.222E-04 | 1.50E-04 | / |
| 通信 | convdeintrlv | 3.487 | 5.611E-04 | 1.61E-04 | / |
| 通信 | helintrlv | 2.960 | 1.109E-03 | 3.75E-04 | / |
| 通信 | heldeintrlv | 2.881 | 1.165E-03 | 4.04E-04 | / |
| 通信 | comm_MultiplexedInterleaver | 3.117 | 4.797E-04 | 1.54E-04 | / |
| 通信 | comm_MultiplexedDeinterleaver | 3.309 | 5.379E-04 | 1.63E-04 | / |
| 通信 | comm_ConvolutionalInterleaver | 3.541 | 4.467E-04 | 1.26E-04 | / |
| 通信 | comm_ConvolutionalDeinterleaver | 2.952 | 4.301E-04 | 1.46E-04 | / |
| 通信 | comm_HelicalInterleaver | 1.930 | 1.123E-03 | 5.82E-04 | / |
| 通信 | comm_HelicalDeinterleaver | 2.273 | 1.425E-03 | 6.27E-04 | / |
| 通信 | comm_PhaseNoise | 3.27E-02 | 5.10E-04 | 0.016 | 针对标量的频偏和相噪输入情况 |
| 图像 | padarray | 1.853E-02 | 3.8E-04 | 0.021 | / |
| 图像 | imregionalmax | 0.3056 | 1.880E-03 | 0.006 | / |
| 图像 | imrotate | 1.938E-03 | 3.6E-04 | 0.186 | / |
基础工具箱
ty_unique 提升了输入大数组时的性能,并解决了部分场景下因内存不足导致的报错问题;
using TyBase using BenchmarkTools using Random Random.seed!(123) @btime ty_unique(rand(1:1.0:50_000_000, 100_000_000))大致的执行时间是:
R2025b SP2:9.31 秒
R2025b SP3:5.12 秒
对于 nargout = 2 的情况,ty_unique 解决了原算法超出内存报错的问题。示例如下:using TyBase using BenchmarkTools using Random Random.seed!(123) @btime ty_unique(rand(1:1.0:50_000_000, 10_000_000), nargout = 2)大致的执行时间是:
R2025b SP2:运行卡死
R2025b SP3:0.48 秒
对于字符串数组,ty_unique 的性能有较大提升。 示例如下:using TyBase using BenchmarkTools R = 10_000_000 A = repeat(["dog", "cat", "fish", "horse", "dog ", "fish "], R) @btime ty_unique(A)大致的执行时间是:
R2025b SP2:8.03 秒
R2025b SP3:3.48 秒此代码是运行在 Windows 11 的 16 核 Intel(R) Core(TM) Ultra 9 185H @ 2.30 GHz 的客户端版本 Syslab,使用 Julia 的 @btime 宏进行计时。
strfind:针对 strfind 进行了性能优化
using TyBase using BenchmarkTools using Random Random.seed!(123) N = 100_000 logs = [rand() < 0.001 ? "ERROR: Something failed" : "INFO: Running normally" for _ in 1:N] @btime strfind(logs, "ERROR");大致的执行时间是:
R2025b SP3:52.92 毫秒
R2025b SP4:3.12 毫秒using TyBase a = ["11111","11112","11121","11122","11211","11212","11221","11222", "12111","12112","12121","12122","12211","12212","12221","12222", "21111","21112","21121","21122","21211","21212","21221","21222", "22111","22112","22121","22122","22211","22212","22221","22222"]; b = 262144 * ones(Int, 39); b[end] = 38528; s = [repeat("1", b[i]) for i in 1:39]; @btime for i in 1:32 for ii in 1:39 stridx = strfind(s[ii], a[i]) end end大致的执行时间是:
R2025b SP3:8.09 秒
R2025b SP4:0.51 秒此代码是运行在 Windows 11 的 16 核 Intel(R) Core(TM) Ultra 9 185H @ 2.30 GHz 的客户端版本 Syslab,使用 Julia 的 @btime 宏进行计时。
fscanf:针对 fscanf 进行了性能优化。
using TyBase using BenchmarkTools A = repeat( [ 8.8 7.7 8800 7700 ], 1000000, ) filename = "num.txt" save(filename, "-ascii"; A) clear([:A]) fid = fopen("num.txt") @btime begin seek(fid, 0) fscanf(fid, "%f") end fclose(fid)大致的执行时间是:
R2025b SP5:5.67 秒
R2026a:0.083 秒delete:针对 delete 进行了性能优化。
filedir = "File_test" if !isdir(filedir) mkdir(filedir) end # 创建 10000 个空文件 for i in 1:10_000 filename = joinpath(filedir, "file_$(i).txt") open(filename, "w") do f # 不写内容,生成空文件 end end using TyBase n = 10_000 filedir = "File_test" files = [joinpath(filedir, "file_$(i).txt") for i in 1:n] @time delete(files)大致的执行时间是:
R2025b SP5:2.91 秒
R2026a:1.68 秒array2table:针对 array2table 进行了性能优化。
using TyBase using BenchmarkTools C = [ 5 "cereal" 110 "C+" 12 "pizza" 140 "B" 23 "salmon" 367 "A" 2 "cookies" 160 "D" ] CC = repeat(C, 10000000) @btime array2table(CC)大致的执行时间是:
R2025b SP5:8.01 秒
R2026a:5.59 秒此代码是运行在 Windows 11 的 16 核 Intel(R) Core(TM) Ultra 9 185H @ 2.30 GHz 的客户端版本 Syslab,使用 Julia 的 @btime、@time 宏进行计时。
图形工具箱
semilogx:针对 semilogx 进行了性能优化。
using TyPlot x = 1:10000000; y = log.(x); semilogx(x, y)大致的执行时间是:
R2025b SP4:4.675 秒
R2025b SP5:1.817 秒此代码是运行在 Windows 10 的 14 核 Intel(R) Core(TM) i7-12800H 的客户端版本 Syslab,使用 Julia @time 宏进行进行计时。
数学工具箱
- nufft:非均匀快速傅里叶变换;
使用采样点 t 返回 X 的非均匀离散傅里叶变换(NUDFT)时计算性能得到了提升,示例如下:
using TyMath using TyBase rng = MT19937ar(5489) x = rand(rng, 2000, 2000) t = [1:500; 1001:2500] y = nufft(x, t)大致的执行时间是:
R2025b SP2:3.25 秒
R2025b SP3:0.13 秒对于使用采样点 t 计算查询点 f 的 NUDFT,示例如下:
using TyMath using TyBase rng = MT19937ar(5489) x = rand(rng, 2000, 2000) t = [1:500; 1001:2500] f = [2001:3000; 4001:5000] y = nufft(x, t, f)大致的执行时间是:
R2025b SP2:3.33 秒
R2025b SP3:0.14 秒对于返回沿维度 dim 的 NUDFT,示例如下:
using TyMath using TyBase rng = MT19937ar(5489) x = rand(rng, 2000, 2000) t = [1:500; 1001:2500] f = [2001:3000; 4001:5000] y = nufft(x, t, f, 2)大致的执行时间是:
R2025b SP2:3.34 秒
R2025b SP3:0.19 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
filter1:对二维或三维散点数据插值;
使用由分子和分母系数 b 和 a 定义的有理传递函数对输入数据 x 进行滤波计算性能得到了提升,示例如下:
using TyMath using TyBase rng = MT19937ar(5489) b = randn(rng, 3042); x = randn(rng, 201326592); xx, = filter1(b, 1, x);大致的执行时间是:
R2025b SP2:62.88 秒
R2025b SP3:37.11 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
isbanded:确定矩阵是否在特定带宽范围内;
使用 box 方法从拟合中排除数据时性能得到了提升,示例如下:
using TyMath using TyBase rng = MT19937ar(5489) a = rand(rng, 10000, 10000); a = tril(a, 500); for i in 1:300000 isbanded(a, 9999, 300) end大致的执行时间是:
R2025b SP3:1.39 秒
R2025b SP4:0.004 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
griddata:对二维或三维散点数据插值;
使用 gridata 的 linear 内插时性能得到了提升,示例如下:
using TyMath using TyBase rng = MT19937ar(5489) x = -3 .+ 6 * rand(rng, 5000); y = -3 .+ 6 * rand(rng, 5000); v = sin.(x) .^ 4 .* cos.(y); xq, yq = meshgrid2(-3:0.01:3, -3:0.01:3); near = "linear" z1 = griddata(x, y, v, xq, yq, near);大致的执行时间是:
R2025b SP3:13.14 秒
R2025b SP4:0.97 秒使用 gridata 的 cubic 内插时性能得到了提升,示例如下:
using TyMath using TyBase rng = MT19937ar(5489) x = -3 .+ 6 * rand(rng, 10000); y = -3 .+ 6 * rand(rng, 10000); v = sin.(x) .^ 4 .* cos.(y); xq, yq = meshgrid2(-3:0.005:3, -3:0.005:3); near = "cubic" z1 = griddata(x, y, v, xq, yq, near);大致的执行时间是:
R2025b SP3:37.74 秒
R2025b SP4:8.37 秒使用 gridata 的 boundary 外插时性能得到了提升,示例如下:
using TyMath using TyBase rng = MT19937ar(5489) xy = -2.5 .+ 5 * rand(rng, 5000, 2); x = xy[:, 1]; y = xy[:, 2]; v = x .* exp.(-x .^ 2 - y .^ 2); xq, yq = meshgrid2(-3:0.01:3, -3:0.01:3); vq = griddata(x, y, v, xq, yq, "linear", "boundary");大致的执行时间是:
R2025b SP3:5.66 秒
R2025b SP4:1.22 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
interp1:一维数据插值(表查找);
使用 interp1 的 spline 方法计算时性能得到了提升,示例如下:
using TyMath using TyBase rng = MT19937ar(5489) xdata = 1:100000000 ydata = rand(100000000) .+ xdata zdata = rand(100000000) .+ xdata F = interp1(xdata, ydata, zdata, "spline", "spline")大致的执行时间是:
R2025b SP3:21.27 秒
R2025b SP4:2.93 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
interp2:meshgrid 格式的二维网格数据插值;
使用 interp2 的 spline 方法计算时性能得到了提升,示例如下:
using TyMath using TyBase rng = MT19937ar(5489) x, y = meshgrid2(0.02:0.02:100, 0.02:0.02:100); z = cos.(x) .+ sin.(y); a, b = meshgrid2(0.02:0.02:100, 0.02:0.02:100); a = a .+ rand(rng, 5000, 5000) b = b .+ rand(rng, 5000, 5000) c = interp2(x, y, z, a, b, "spline")大致的执行时间是:
R2025b SP3:5.00 秒
R2025b SP4:1.18 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
conv2:二维卷积;
使用 conv2 计算时性能得到了提升,示例如下:
using TyMath rng = MT19937ar(5489) u = rand(rng, 680000,1); v = rand(rng, 680000,1); y = conv2(u, v);大致的执行时间是:
R2025b SP3:176.96 秒
R2025b SP4:8.87 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
interp1:一维数据插值(表查找);
使用 pchip 方法进行计算时性能得到了提升,示例如下:
using TyMath using TyBase rng = MT19937ar(5489) sig_len = 20971520 sig_ana = rand(rng,1, 20971520) cc = rand(rng,20971520, 1) x = 1:sig_len y = vec(sig_ana) xq = vec(cc) sin_sig = interp1(x,y,xq, "pchip");大致的执行时间是:
R2025b SP5:0.402069 秒
R2026a:0.204279 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T@2.5GHz 测试环境上利用 julia 的@elapsed、@belapsed 综合得出。
interp3:meshgrid 格式的三维网格数据插值;
使用 cubic 方法时性能得到了提升,示例如下:
using TyMath using TyBase X, Y, Z, V = TyPlot.flow(10; nargout=4) Xq, Yq, Zq = meshgrid3(0.1:0.025:10, -3:0.025:3, -3:0.025:3) # mtest-setup end Vq = interp3(X, Y, Z, V, Xq, Yq, Zq, "cubic")大致的执行时间是:
R2025b SP5:2.46666 秒
R2026a:0.110469 秒使用 spline 方法时性能得到了提升,示例如下:
using TyMath using TyBase using TyPlot X, Y, Z, V = TyPlot.flow(10; nargout=4) Xq, Yq, Zq = meshgrid3(0.1:0.025:10, -3:0.025:3, -3:0.025:3) Vq = interp3(X, Y, Z, V, Xq, Yq, Zq, "spline")大致的执行时间是:
R2025b SP5:2.62934 秒
R2026a:0.205704 秒使用 nearest 方法时性能得到了提升,示例如下:
using TyMath using TyBase using TyPlot X, Y, Z, V = TyPlot.flow(10; nargout=4) Xq, Yq, Zq = meshgrid3(0.1:0.025:10, -3:0.025:3, -3:0.025:3) Vq = interp3(X, Y, Z, V, Xq, Yq, Zq, "nearest")大致的执行时间是:
R2025b SP5:0.278608 秒
R2026a:0.235736 秒
此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T@2.5GHz 测试环境上利用 julia 的@elapsed、@belapsed 综合得出。
padecoef:时滞的 Padé 逼近;
使用 padecoef 计算时性能得到了提升,示例如下:
using TyMath m = 20000000; for i in 1:10 a, b = padecoef(m, m) end大致的执行时间是:
R2025b SP5:2.95182 秒
R2026a:1.55652 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T@2.5GHz 测试环境上利用 julia 的@elapsed、@belapsed 综合得出。
pchip:分段三次 Hermite 插值多项式(PCHIP);
使用 pchip 时性能得到了提升,示例如下:
using TyMath using TyBase x = 0:0.000001:15; y = besselj.(1, x); xq2 = 0:0.01:15; s = pchip(x, y, xq2);大致的执行时间是:
R2025b SP5:1.62353 秒
R2026a:0.981722 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T@2.5GHz 测试环境上利用 julia 的@elapsed、@belapsed 综合得出。
delaunay:Delaunay 三角剖分;
使用 delaunay 计算时性能得到了提升,示例如下:
using TyMath rng = MT19937ar(5489); x = randn(rng, 300000); y = randn(rng, 300000); DT = delaunay(x, y);大致的执行时间是:
R2025b SP5:3.3267 秒
R2026a:0.626315 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T@2.5GHz 测试环境上利用 julia 的@elapsed、@belapsed 综合得出。
interp2:meshgrid 格式的二维网格数据插值;
使用 cubic 方法时性能得到了提升,示例如下:
using TyMath using TyBase rng = MT19937ar(5489) x, y = meshgrid2(0.1:0.1:100, 0.1:0.1:100); z = cos.(x) .+ sin.(y); a, b = meshgrid2(0.1:0.1:100, 0.1:0.1:100); a = a .+ rand(rng, 1000, 1000) b = b .+ rand(rng, 1000, 1000) c = interp2(x, y, z, a, b, "cubic")大致的执行时间是:
R2025b SP5:0.021797 秒
R2026a:0.0077543 秒使用 linear 方法时性能得到了提升,示例如下:
using TyMath using TyBase rng = MT19937ar(5489) x, y = meshgrid2(0.05:0.05:100, 0.05:0.05:100); z = cos.(x) .+ sin.(y); a, b = meshgrid2(0.05:0.05:100, 0.05:0.05:100); a = a .+ rand(rng, 2000, 2000) b = b .+ rand(rng, 2000, 2000) c = interp2(x, y, z, a, b, "linear")大致的执行时间是:
R2025b SP5:0.0752287 秒
R2026a:0.0093791 秒
此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T@2.5GHz 测试环境上利用 julia 的@elapsed、@belapsed 综合得出。
- nufft:非均匀快速傅里叶变换;
优化工具箱
fmincon:寻找约束非线性多变量函数的最小值;
使用 fmincon 求解线性与边界约束时计算性能得到了提升,示例如下:
using TyMath using TyOptimization PrG1f = x -> begin x1 = @views x[1:4] x2 = @views x[5:13] y = 5 * sum(x1) - 5 * dot(x1, x1) - sum(x2) return y end A = [ 2 2 0 0 0 0 0 0 0 0 1 0 0 2 0 2 0 0 0 0 0 0 1 0 1 0 0 2 2 0 0 0 0 0 0 0 1 1 0 -8 0 0 0 0 0 0 0 0 1 0 0 0 0 -8 0 0 0 0 0 0 0 0 1 0 0 0 0 -8 0 0 0 0 0 0 0 0 1 0 0 0 0 -2 -1 0 0 0 0 1 0 0 0 0 0 0 0 0 -2 -1 0 0 0 1 0 0 0 0 0 0 0 0 0 -2 -1 0 0 1 0 ] b = [10, 10, 10, 0, 0, 0, 0, 0, 0] lb = zeros(13) ub = ones(13) ub[10:12] .= 100.0 rng = MT19937ar(5489) x0 = rand(rng, 13) opts = optimoptions(:fmincon; Algorithm="active-set", Display="off") for i in 1:2000 x, fval = fmincon(PrG1f, x0, A, b, [], [], lb, ub, nothing, opts) end大致的执行时间是:
R2025b SP2:1.39 秒
R2025b SP3:1.26 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
fminunc:求无约束多变量函数的最小值;
使用 fminunc 默认算法求解大规模无约束问题的计算性能得到了提升,示例如下:
using TyMath using TyOptimization N = 2000 x0 = fill(-2.0, N) x0[2:2:N] .= 2.0 function multirosenbrockval(x) F = 0.0 @inbounds for i in eachindex(x) if iseven(i) F += abs2(10.0 * (x[i] - x[i - 1]^2)) else F += abs2(1.0 - x[i]) end end return F end options = optimoptions(:fminunc; Display="off", Algorithm="quasi-newton") X, FVAL, EXITFLAG, OUTPUT, GRAD, HESSIAN = fminunc(multirosenbrockval, x0, options)大致的执行时间是:
R2025b SP2:7.52 秒
R2025b SP3:4.25 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
quadprog:二次规划;
使用 active-set 算法求解二次规划问题时计算性能得到了提升,示例如下:
using TyOptimization opts = optimoptions(:quadprog; Algorithm="active-set", Display="off") H = [1.0 -1.0; -1.0 2.0] f = [-2.0, -6.0] A = [1.0 1.0; -1.0 2.0; 2.0 1.0] b = [2.0, 2.0, 3.0] for i in 1:100000 x, fval, exitflag, output, lambda = quadprog(H, f, A, b, [], [], [], [], [], opts) end大致的执行时间是:
R2025b SP3:1.28 秒
R2025b SP4:0.86 秒使用 trust-region-reflective 算法求解二次规划问题时计算性能得到了提升,示例如下:
using TyOptimization opts = optimoptions(:quadprog; Algorithm="trust-region-reflective", Display="off") H = [ 1 -1 1 -1 2 -2 1 -2 4 ] f = [2; -3; 1] Aeq = ones(1, 3) beq = [1 / 2] for i in 1:100000 x, fval, exitflag, output, lambda = quadprog(H, f, [], [], Aeq, beq, [], [], [], opts) end大致的执行时间是:
R2025b SP3:8.14 秒
R2025b SP4:6.75 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
lsqlin:求解约束线性最小二乘问题;
使用 active-set(默认)算法求解约束线性最小二乘问题时计算性能得到了提升,示例如下:
using TyOptimization opt = optimoptions(:lsqlin; Algorithm="active-set", Display="off") C = [ 0.9501 0.7620 0.6153 0.4057 0.2311 0.4564 0.7919 0.9354 0.6068 0.0185 0.9218 0.916 0.4859 0.8214 0.7382 0.4102 0.8912 0.4447 0.1762 0.8936 ] d = [ 0.0578 0.3528 0.8131 0.0098 0.1388 ] A = [ 0.2027 0.2721 0.7467 0.4659 0.1987 0.1988 0.4450 0.4186 0.6037 0.0152 0.9318 0.8462 ] b = [ 0.5251 0.2026 0.6721 ] for i in 1:200000 x, fval = lsqlin(C, d, A, b, [], [], [], [], [], opt) end大致的执行时间是:
R2025b SP3:2.69 秒
R2025b SP4:1.89 秒使用 trust-region-reflective 算法求解约束线性最小二乘问题时计算性能得到了提升,示例如下:
using TyOptimization rng = MT19937ar(5489) n = 100 x0 = 5 .* rand(rng, n) options = optimoptions(:lsqlin; Algorithm="trust-region-reflective", Display="off") r = 1:(n - 1) v = Vector{Float64}(undef, n) v[n] = (-1)^(n + 1) / n v[r] = (-1) .^ (r .+ 1) ./ r C = TestArrays.circul(v) C = vcat(C, C) r = 1:(2 * n) d = zeros(r) d[r] = n .- r lb = fill(-5, n) ub = fill(5, n) for i in 1:1000 x, fval = lsqlin(C, d, [], [], [], [], lb, ub, x0, options) end大致的执行时间是:
R2025b SP3:25.01 秒
R2025b SP4:6.97 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
fminsearch:使用无导数法计算无约束的多变量函数的最小值。
使用 fminsearch 时计算性能得到了提升,示例如下:
using TyOptimization fun = x -> begin f = 0 for k in -10:10 f = f + exp(-(x[1] - x[2])^2 - 2 * x[1]^2) * cos(x[2]) * sin(2 * x[2]) end return f end x0 = [0.25, -0.25] opts = optimset(; Display="off", StepTolerance=1e-12) for i in 1:10000 x, = fminsearch(fun, x0, opts) end大致的执行时间是:
R2025b SP3:1.28 秒
R2025b SP4:0.54 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
全局优化工具箱
paretosearch:寻找帕累托解集。
使用 paretosearch 计算带边界约束的多目标优化时计算性能得到了提升,示例如下:
using TyMath using TyGlobalOptimization f1(x) = norm(x - [1, 2])^2 f2(x) = norm(x + [2, 1])^2 f(x) = [f1(x), f2(x)] lb = [-10, -10] ub = [10, 10] nvars = 2 ParetoSolution, ParetoFront = paretosearch(f, nvars, lb, ub)大致的执行时间是:
R2025b SP2:8.07 秒
R2025b SP3:0.02 秒使用非默认选项 paretosearch 优化时计算性能得到了提升,示例如下:
using TyMath using TyGlobalOptimization f(x) = [norm(x - [i + 1, i, 1 - i])^2 for i in 1:10] lb = [-10, -10, -10] ub = [10, 10, 10] nvars = 3 options = paretosearch_options(; step_tolerance=1e-5) for i in 1:10 ParetoSolution, ParetoFront = paretosearch(f, nvars, lb, ub, options) end大致的执行时间是:
R2025b SP2:208.34 秒
R2025b SP3:0.62 秒
此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
曲线拟合工具箱
excludedata:从拟合中排除数据;
使用 box 方法从拟合中排除数据时性能得到了提升,示例如下:
using TyMath using TyCurveFitting rng = MT19937ar(5489) x = 6 * rand(rng, 1000000) .- 3 y = 6 * rand(rng, 1000000) .- 3 method = "box" v = [-1 1 -1 1] for i in 1:200 f = excludedata(x, y, method, v) end大致的执行时间是:
R2025b SP3:1.95 秒
R2025b SP4:0.29 秒使用 domain 方法从拟合中排除数据时性能得到了提升,示例如下:
using TyMath using TyCurveFitting rng = MT19937ar(5489) x = 6 * rand(rng, 1000000) .- 3 y = 6 * rand(rng, 1000000) .- 3 method = "domain" v = [-2 2] for i in 1:400 f = excludedata(x, y, method, v) end大致的执行时间是:
R2025b SP3:1.42 秒
R2025b SP4:0.31 秒使用 range 方法从拟合中排除数据时性能得到了提升,示例如下:
using TyMath using TyCurveFitting rng = MT19937ar(5489) x = 6 * rand(rng, 1000000) .- 3 y = 6 * rand(rng, 1000000) .- 3 method = "range" v = [-1, 1] for i in 1:400 f = excludedata(x, y, method, v) end大致的执行时间是:
R2025b SP3:1.81 秒
R2025b SP4:0.31 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
prepareCurveData:为曲线拟合准备数据输入;
使用 prepareCurveData 时性能得到了提升,示例如下:
using TyMath using TyCurveFitting rng = MT19937ar(5489) x = rand(rng, 2000, 2000) + rand(rng, 2000, 2000) * im y = rand(rng, 2000, 2000) + rand(rng, 2000, 2000) * im XOUT, YOUT = prepareCurveData(x, y)大致的执行时间是:
R2025b SP3:3.17 秒
R2025b SP4:0.54 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @time 测的第二次运行时间。
category:FitResult 或 FitType 对象的类别;
使用 category 返回 FitResult 或 FitType 对象 fun 的类别时性能得到了提升,示例如下:
using TyMath using TyCurveFitting t = fittype("a*x^2+b*exp(n*x)") for i in 1:500000 args = category(t) end大致的执行时间是:
R2025b SP3:1.24 秒
R2025b SP4:0.004 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
prepareSurfaceData:为曲面拟合准备数据输入;
使用 prepareCurveData 时性能得到了提升,示例如下:
using TyMath using TyCurveFitting rng = MT19937ar(5489) x = randn(rng, 1000000) y = randn(rng, 1000000) z = randn(rng, 1000000) w = randn(rng, 1000000) for i in 1:5 XOUT, YOUT, ZOUT, WOUT = prepareSurfaceData(x, y, z, w) end大致的执行时间是:
R2025b SP3:3.33 秒
R2025b SP4:0.82 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
numargs:FitResult 或 FitType 对象的输入参数个数;
使用 numargs 返回 FitResult 或 FitType 对象 fun 的输入参数个数时性能得到了提升,示例如下:
using TyMath using TyCurveFitting t = fittype("poly23") for i in 1:30000000 args = numargs(t) end大致的执行时间是:
R2025b SP3:3.18 秒
R2025b SP4:0.02 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
islinear:判断 FitResult 或 FitType 对象是否线性;
使用 islinear 判断 FitResult 或 FitType 对象 fun 是否线性时性能得到了提升,示例如下:
using TyMath using TyCurveFitting t = fittype("poly23") for i in 1:4000000 args = islinear(t) end大致的执行时间是:
R2025b SP3:1.94 秒
R2025b SP4:0.01 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
typecur:FitResult 或 FitType 对象的名称;
使用 typecur 获取 FitResult 或 FitType 对象 fun 的名称时性能得到了提升,示例如下:
using TyMath using TyCurveFitting t = fittype("thinplateinterp") for i in 1:10000000 args = typecur(t) end大致的执行时间是:
R2025b SP3:2.66 秒
R2025b SP4:0.04 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
fittype:曲线与曲面拟合的拟合类型;
使用 fittype 创建拟合类型时性能得到了提升,示例如下:
s = "n*u^a" for i in 1:3000 f = fittype(s; problem="n", independent="u") end大致的执行时间是:
R2025b SP3:13.26 秒
R2025b SP4:1.07 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
dependnames:FitResult 或 FitType 对象的因变量名;
使用 dependnames 返回 FitResult 或 FitType 对象 fun 的因变量名时性能得到了提升,示例如下:
using TyMath using TyCurveFitting t = fittype("a*x^2+b*exp(n*x)") for i in 1:3000000 args = dependnames(t) end大致的执行时间是:
R2025b SP4:0.04 秒
R2025b SP5:0.03 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
indepnames:FitResult 或 FitType 对象的自变量名;
使用 dependnames 返回 FitResult 或 FitType 对象 fun 的自变量名时性能得到了提升,示例如下:
using TyMath using TyCurveFitting t = fittype("a*x^2+b*exp(n*x)") for i in 1:3000000 args = indepnames(t) end大致的执行时间是:
R2025b SP4:0.04 秒
R2025b SP5:0.01 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @time 测的第二次运行时间。
probnames:FitResult 或 FitType 对象的问题参数名;
使用 probnames 返回 FitResult 或 FitType 对象 fun 的问题参数名时性能得到了提升,示例如下:
using TyMath using TyCurveFitting t = fittype("a*x^2+b*exp(n*x)") for i in 1:100000000 args = probnames(t) end大致的执行时间是:
R2025b SP4:1.57 秒
R2025b SP5:0.50 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
islinear:判断 FitResult 或 FitType 对象是否线性;
使用 islinear 判断 FitResult 或 FitType 对象 fun 是否线性时性能得到了提升,示例如下:
using TyMath using TyCurveFitting t = fittype("a*x^2+b*exp(n*x)") for i in 1:4000000 args = islinear(t) end大致的执行时间是:
R2025b SP4:0.019 秒
R2025b SP5:0.008 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
coeffnames:FitType 对象的系数名;
使用 coeffnames 获取 FitType 对象的系数名时性能得到了提升,示例如下:
using TyMath using TyCurveFitting t = fittype("a*x^2+b*exp(n*x)") for i in 1:10000000 args = coeffnames(t) end大致的执行时间是:
R2025b SP4:0.16 秒
R2025b SP5:0.08 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的@elapsed、@belapsed 综合得出。
typecur:FitResult 或 FitType 对象的名称;
使用 typecur 获取 FitResult 或 FitType 对象 fun 的名称时性能得到了提升,示例如下:
using TyMath using TyCurveFitting t = fittype("a*x^2+b*exp(n*x)") for i in 1:400000 args = typecur(t) end大致的执行时间是:
R2025b SP4:0.006 秒
R2025b SP5:0.003 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
formula:FitResult 或 FitType 对象的公式;
使用 typecur 获取 FitResult 或 FitType 对象 fun 的公式时性能得到了提升,示例如下:
using TyMath using TyCurveFitting t = fittype("a*x^2+b*exp(n*x)") for i in 1:300000000 args = formula(t) end大致的执行时间是:
R2025b SP4:5.20 秒
R2025b SP5:2.51 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
fit:为数据拟合曲线或曲面;
使用 fit 创建三维线性插值对象时性能得到了提升,示例如下:
using TyMath using TyCurveFitting rng = MT19937ar(5489) x = rand(rng, 100000) y = rand(rng, 100000) z = rand(rng, 100000) method = "linearinterp" for i in 1:20 ft = fit(method, [x y], z) end大致的执行时间是:
R2025b SP4:48.67 秒
R2025b SP5:0.47 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
numcoeffs:FitResult 或 FitType 对象的参数个数;
使用 numcoeffs 获取 FitResult 或 FitType 对象 fun 的参数个数时性能得到了提升,示例如下:
using TyMath using TyCurveFitting include(pkgdir(TyCurveFitting) * "/examples/docs/census.jl") ft = fit("poly2", cdate, pop) for i in 1:300000000 args = numcoeffs(ft) end大致的执行时间是:
R2025b SP4:9.69 秒
R2025b SP5:2.79 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
integrate:积分 FitResult 对象;
使用 integrate 获取 积分 FitResult 对象时性能得到了提升,示例如下:
using TyMath using TyCurveFitting include(pkgdir(TyCurveFitting) * "/examples/docs/census.jl") ft = fit("poly2", cdate, pop) x0 = 1700 for i in 1:10000 args = integrate(ft, cdate, x0) end大致的执行时间是:
R2025b SP4:1.67 秒
R2025b SP5:0.01 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
excludedata:从拟合中排除数据。
使用 excludedata 计算时性能得到了提升,示例如下:
using TyMath using TyCurveFitting rng = MT19937ar(5489) x = 6 * rand(rng, 1000000) .- 3 y = 6 * rand(rng, 1000000) .- 3 method = "box" v = [-1 1 -1 1] for i in 1:200 f = excludedata(x, y, method, v) end大致的执行时间是:
R2025b SP5:0.397108 秒
R2026a:0.0936431 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T@2.5GHz 测试环境上利用 julia 的@elapsed、@belapsed 综合得出。
统计工具箱
gamfit:Gamma 参数估计;
使用 gamfit 计算时性能得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) a = rand(rng, 500000); c = randi(rng, (false, true), 500000); gamfit(a, 0.1, c);大致的执行时间是:
R2025b SP3:2.20 秒
R2025b SP4:0.70 秒gamlike:Gamma 负对数似然;
使用 gamlike 计算时性能得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) a = rand(rng, 10000000); c = randi(rng, (false, true), 10000000); gamlike([0.5, 0.5], a, c);大致的执行时间是:
R2025b SP3:1.81 秒
R2025b SP4:0.91 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
fitdist:对数据进行概率分布对象拟合;
使用 fitdist 对数据进行 Rician 分布拟合时得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) x = rand(rng, 1000000) fitdist(x, "Rician")大致的执行时间是:
R2025b SP3:20.89 秒
R2025b SP4:0.64 秒使用 fitdist 对数据进行 Gamma 分布拟合时得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) a = rand(rng, 5000000); c = randi(rng, (false, true), 5000000); pd = fitdist(a, "Gamma"; cens=c)大致的执行时间是:
R2025b SP3:28.46 秒
R2025b SP4:0.37 秒使用 fitdist 对数据进行 Nakagami 分布拟合时得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) a = rand(rng, 2000000) pd = fitdist(a, "Nakagami")大致的执行时间是:
R2025b SP3:1.47 秒
R2025b SP4:0.40 秒使用 fitdist 对数据进行 kernel 分布拟合时得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) data = rand(rng, 1000000) * 0.5 .+ 1.5 test = rand(rng, 1, 500) * 0.5 .+ 1.5 pd = fitdist(data, "kernel") pdf(pd.Pd, test);大致的执行时间是:
R2025b SP3:13.53 秒
R2025b SP4:1.27 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
mle :最大似然估计;
使用 mle 对 Rician 分布进行最大似然估计时得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) x = rand(rng, 500000) p, = mle(x; dist="Rician")大致的执行时间是:
R2025b SP3:10.55 秒
R2025b SP4:1.10 秒使用 mle 对 Gamma 分布进行最大似然估计时得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) a = rand(rng, 10000000); mle(a; dist="Gamma", alpha=0.08, OptimFun="fmincon")大致的执行时间是:
R2025b SP3:1.16 秒
R2025b SP4:0.53 秒使用 mle 对 Nakagami 分布进行最大似然估计时得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) a = rand(rng, 5000000) p1, p2 = mle(a; dist="Nakagami")大致的执行时间是:
R2025b SP3:3.72 秒
R2025b SP4:1.66 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
cdf:累积分布函数;
使用 cdf 计算广义帕累托分布时性能得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) a = rand(rng, 1500000); pd = paretotails(a, 0.3, 0.7); x = rand(rng, 12000); # mtest-setup end cdf(pd, x, "upper"); # R2025b SP3 使用方法为cdf.(pd, x, "upper");大致的执行时间是:
R2025b SP3:2.74 秒
R2025b SP4:0.13 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
pdf:概率密度函数;
使用 cdf 计算广义帕累托分布时性能得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) a = rand(rng, 1500000) pd = paretotails(a, 0.2, 0.8); x = rand(rng, 1000); pdf(pd, x);大致的执行时间是:
R2025b SP3:3.04 秒
R2025b SP4:0.02 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
paretotails:具有 Pareto 尾部的广义帕累托分布;
使用 paretotails 创建广义帕累托分布对象时性能得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) a = rand(rng, 1500000); pd = paretotails(a, 0.2, 0.8);大致的执行时间是:
R2025b SP3:0.93 秒
R2025b SP4:0.73 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
boundary:帕累托分布边界;
使用 boundary 计算广义帕累托分布对象的边界点时性能得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) a = rand(rng, 1500000); pd = paretotails(a, 0.3, 0.7); for i in 1:3000000 boundary(pd) end大致的执行时间是:
R2025b SP3:1.91 秒
R2025b SP4:0.0007 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
nsegments:广义帕累托分布中的段数;
使用 nsegments 计算广义帕累托分布对象的段数时性能得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) a = rand(rng, 1500000); pd = paretotails(a, 0.3, 0.9); for i in 1:100000000 nsegments(pd) end大致的执行时间是:
R2025b SP3:5.16 秒
R2025b SP4:0.80 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
random:随机数;
使用 random 从广义帕累托分布返回随机数时性能得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) a = rand(rng, 1500000); pd = paretotails(a, 0.3, 0.9); random(rng, pd, 6000);大致的执行时间是:
R2025b SP3:1.64 秒
R2025b SP4:0.0008 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
gpfit:广义帕累托分布参数估计;
使用 gpfit 计算时性能得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) a = rand(rng, 500000); gpfit(a);大致的执行时间是:
R2025b SP3:3.28 秒
R2025b SP4:0.47 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
ncx2pdf:非中心卡方分布概率密度函数;
使用 ncx2pdf 计算时性能得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) x1 = rand(rng, 3000, 3000) x2 = rand(rng, 3000, 3000) x3 = rand(rng, 3000, 3000) y = ncx2pdf(x1, x2, x3)大致的执行时间是:
R2025b SP3:2.77 秒
R2025b SP4:0.28 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
unifit:连续均匀分布参数估计;
使用 unifit 计算时性能得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) x = rand(rng, 100000000) # mtest-setup end for i in 1:5 ahat,bhat,ACI,BCI = unifit(x) end大致的执行时间是:
R2025b SP3:17.35 秒
R2025b SP4:1.74 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
chi2gof:卡方拟合优度检验;
使用 chi2gof 计算时性能得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) x = randn(rng, 10000000) for i in 1:4 h, p = chi2gof(x; Alpha=0.01) end大致的执行时间是:
R2025b SP3:12.75 秒
R2025b SP4:1.32 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
ncx2pdf:非中心卡方分布概率密度函数;
使用 ncx2pdf 计算时性能得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) x1 = rand(rng, 200, 200, 200) x2 = rand(rng, 200, 200, 200) x3 = rand(rng, 200, 200, 200) y = ncx2pdf(x1, x2, x3)大致的执行时间是:
R2025b SP3:7.70 秒
R2025b SP4:1.57 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
fitdist:对数据进行概率分布对象拟合;
使用 fitdist 对数据进行 ExtremeValue 分布拟合时得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) x = rand(rng, 10000000) fitdist(x, "ExtremeValue")大致的执行时间是:
R2025b SP4:1.24 秒
R2025b SP5:0.61 秒使用 fitdist 对数据进行 Weibull 分布拟合时得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) x = rand(rng, 10000000) for i in 1:2 fitdist(x, "Weibull") end大致的执行时间是:
R2025b SP4:2.79 秒
R2025b SP5:1.85 秒使用 fitdist 对数据进行 GeneralizedExtremeValue 分布拟合时得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) a = rand(rng, 1000000) pd = fitdist(a, "GeneralizedExtremeValue")大致的执行时间是:
R2025b SP4:6.73 秒
R2025b SP5:1.53 秒使用 fitdist 对数据进行 HalfNormal 分布拟合时得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) a = rand(rng, 10000000); for i in 1:10 pd = fitdist(a, "HalfNormal") end大致的执行时间是:
R2025b SP4:2.52 秒
R2025b SP5:1.25 秒使用 fitdist 对数据进行 Rayleigh 分布拟合时得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) x = randi(rng, [0, 10000], 10000000) for _ in 1:10 fitdist(x, "Rayleigh") end大致的执行时间是:
R2025b SP4:5.99 秒
R2025b SP5:1.27 秒使用 fitdist 对数据进行 LogNormal 分布拟合时得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) a = rand(rng, 50000) c = randi(rng, (0, 1), 50000) for i in 1:50 pd = fitdist(a, "LogNormal"; cens=c) end大致的执行时间是:
R2025b SP4:1.58 秒
R2025b SP5:1.38 秒使用 fitdist 对数据进行 Loglogistic 分布拟合时得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) a = rand(rng, 2000000) pd = fitdist(a, "Loglogistic")大致的执行时间是:
R2025b SP4:4.14 秒
R2025b SP5:0.64 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T @ 2.5 GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
mle:最大似然估计;
使用 mle 对 LogNormal 分布进行最大似然估计时得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) a = rand(rng, 3000000) for i in 1:8 p1, p2 = mle(a; dist="LogNormal") end大致的执行时间是:
R2025b SP4:6.06 秒
R2025b SP5:0.97 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM)i3-13100T@2.5GHz 测试环境上利用 julia 的 @elapsed、@belapsed 综合得出。
movmad:移动中位数绝对偏差。
使用 movmad 计算时得到了提升,示例如下:
using TyMath using TyStatistics rng = MT19937ar(5489) x1 = rand(rng, 10000, 10000) x2 = 2 y = movmad(x1, x2);大致的执行时间是:
R2025b SP5:7.73005 秒
R2026a:0.98692 秒此代码是运行在 Windows 11 的 8 核 Intel(R) Core(TM) i3-13100T@2.5GHz 测试环境上利用 julia 的@elapsed、@belapsed 综合得出。
信号处理工具箱
thd:总谐波失真
优化了寻找谐波位置部分的算法,性能有少量提升。
using TyMath using TySignalProcessing t = [0:0.001:(10-0.001);] x = @. 2 * cos(2 * pi * 100 * t) + 0.01 * cos(2 * pi * 200 * t) + 0.005 * cos(2 * pi * 300 * t); tharmdist = 10 * log10((0.01^2 + 0.005^2) / 2^2) r, = thd(x)大致的执行时间是:
R2025b SP4:2.349 毫秒
R2025b SP5:2.210 毫秒snr:信噪比
优化了 snr 函数输入信号和噪声估计时的计算方式。
using TyControlSystems using TySignalProcessing using TyMath Tpulse = 20e-3 Fs = 10e3 t = [-1:(1/Fs):1;] x = rectpuls(t, Tpulse) rng = MT19937ar(1234) SNR = 53; y = randn(rng, size(x)) * std(x) / db2mag(SNR) pulseSNR, = snr(x, y)大致的执行时间是:
R2025b SP4:55.600 微秒
R2025b SP5:25.500 微秒sfdr:无杂散动态范围
优化了 sfdr 输入功率谱时的寻峰算法。
using TySignalProcessing deltat = 1e-8 fs = 1 / deltat t = [0:deltat:(1e-2-deltat);] x = @. cos(2 * pi * 10e6 * t) + 3.16e-4 * cos(2 * pi * 20e6 * t) + 3.16e-4 * cos(2 * pi * 30e6 * t) + 0.1e-5 * cos(2 * pi * 25e6 * t) + 0.1e-5 * cos(2 * pi * 28e6 * t) sxx, f = ty_periodogram(x[1:512], hann(512), [], fs, stype="power") sfdr(sxx, f, "power")大致的执行时间是:
R2025b SP4:4.213 微秒
R2025b SP5:1.270 微秒此代码是运行在 Windows 11 的 14 核 Intel(R) Core(TM) i7-12800H 的客户端版本 Syslab,使用 Julia @benchmark 宏进行进行计时。
firls:最小二乘线性相位 FIR 滤波器设计
优化了内部计算内存分配,使用更加高效的正弦积分算法。
using TySignalProcessing N = 255 W = [1 1 1 1 1 1 1] F = [0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5 0.55 0.6 1] A = [1 1.004124204 1.0166407385 1.0379928618 1.0689593321 1.1107207345 1.1649666232 1.2340621521 1.3213063997 1.4313388505 1.5707963268 1.7494141507 0 1] firls(N, F, A, W, "differentiator")大致的执行时间是:
R2025b SP5:0.035606 秒
R2026a:0.005351 秒medfilt1:一维中值滤波
基于双堆法重做了算法。
using TySignalProcessing fs = 1000000 t = 0:1/fs:1-1/fs x = sin.(2 * pi * t * 3) + 0.25 * sin.(2 * pi * t * 40) medfilt1(x, 1000)大致的执行时间是:
R2025b SP5:3.223 秒
R2026a:0.028694 秒
通信工具箱
block_decode:重做了 block_decode 函数的功能,函数的执行速度得到提升;
using TyCommunication using TyMath rng = MT19937ar(1234) n = 15 k = 11 data = rand(rng, 0:1, k) encData, = block_encode(data, n, k, "hamming/binary") encData[4] = Int(Bool(encData[4])) decData, = block_decode(encData, n, k, "hamming/binary")大致的执行时间是:
R2025b SP2:19.900 微秒
R2025b SP3:11.400 微秒此代码是运行在 Windows 11 的 14 核 Intel(R) Core(TM) i7-12800H 的客户端版本 Syslab,使用 Julia @benchmark 宏进行进行计时。
syndtable:优化了 syndtable;
using TyCommunication m = 3 n = 2^m - 1 k = n - m parmat, = hammgen(m) trt = syndtable(parmat)大致的执行时间是:
R2025b SP2:4.786 微秒
R2025b SP3:1.780 微秒 此代码是运行在 Windows 11 的 14 核 Intel(R) Core(TM) i7-12800H 的客户端版本 Syslab,使用Julia @benchmark 宏进行进行计时。muxintrlv:使用具有指定延迟的移位寄存器置换符号;
using TyCommunication data7 = 1:10 delay7 = [0, 1, 2] a7, b7, c7 = muxintrlv(data7, delay7)大致的执行时间是:
R2025b SP3:10.233 微秒
R2025b SP4:305.357 纳秒muxdeintrlv:使用指定的移位寄存器恢复符号的顺序;
using TyCommunication delay7 = [0, 1, 2] a7 = [1, 0, 0, 4, 2, 0, 7, 5, 3, 10] g7, h7, i7 = muxdeintrlv(a7, delay7)大致的执行时间是:
R2025b SP3:8.300 微秒
R2025b SP4:361.290 纳秒convintrlv:使用移位寄存器置换符号;
using TyCommunication using TyMath rng = MT19937ar(1234) x8 = rand(rng, 0:1, Int(5e4)) nrows8 = 5 slope8 = 3 convintrlv(x8, nrows8, slope8)大致的执行时间是:
R2025b SP3:3.487 秒
R2025b SP4:522.200 微秒convdeintrlv:使用移位寄存器恢复符号的顺序;
using TyCommunication using TyMath rng = MT19937ar(1234) x8 = rand(rng, 0:1, Int(5e4)) nrows8 = 5 slope8 = 3 y8, = convintrlv(x8, nrows8, slope8) dei, = convdeintrlv(y8, nrows8, slope8)大致的执行时间是:
R2025b SP3:3.487 秒
R2025b SP4:561.150 微秒helintrlv:使用螺旋数组置换符号;
using TyMath using TyCommunication rng = MT19937ar(1234) data = randi(rng, [0, 7], Int(5e4)) i1, state = helintrlv(data, 500, 100, 1)大致的执行时间是:
R2025b SP3:2.960 秒
R2025b SP4:1.109 毫秒heldeintrlv:恢复使用 helintrlv 排列的符号的顺序;
using TyMath using TyCommunication rng = MT19937ar(1234) data = randi(rng, [0, 7], Int(5e4)) i1, state = helintrlv(data, 500, 100, 1) heldeintrlv(i1, 500, 100, 1)大致的执行时间是:
R2025b SP3:2.881 秒
R2025b SP4:1.165 毫秒comm_MultiplexedInterleaver:使用一组具有指定延迟的移位寄存器来置换输入符号;
using TyCommunication interleaver = comm_MultiplexedInterleaver(Delay=[1; 0; 2; 1]) rng = MT19937ar(1234) data = randi(rng, [0 7], Int(5e4)) intrlvSequence = step(interleaver, data)大致的执行时间是:
R2025b SP3:3.117 秒
R2025b SP4:479.700 微秒comm_MultiplexedDeinterleaver:使用一组具有指定延迟的移位寄存器对输入符号进行解交织;
using TyCommunication interleaver = comm_MultiplexedInterleaver(Delay=[1; 0; 2; 1]) deinterleaver = comm_MultiplexedDeinterleaver(Delay=[1; 0; 2; 1]) rng = MT19937ar(1234) data = randi(rng, [0 7], Int(5e4)) intrlvSequence = step(interleaver, data) deintrlvSequence = step(deinterleaver, intrlvSequence)大致的执行时间是:
R2025b SP3:3.309 秒
R2025b SP4:537.900 微秒comm_ConvolutionalInterleaver:使用具有相同属性值的移位寄存器置换输入符号;
using TyCommunication rng = MT19937ar(1234) data10 = randi(rng, [0, 7], Int(5e4)) con10 = comm_ConvolutionalInterleaver(NumRegisters=2, RegisterLengthStep=3) intrlved10, = step(con10, data10)大致的执行时间是:
R2025b SP3:3.541 秒
R2025b SP4:446.700 微秒comm_ConvolutionalDeinterleaver:使用移位寄存器恢复符号的顺序;
using TyCommunication rng = MT19937ar(1234) data10 = randi(rng, [0, 7], Int(5e4)) con10 = comm_ConvolutionalInterleaver(NumRegisters=2, RegisterLengthStep=3) deinterleaver = comm_ConvolutionalDeinterleaver(; NumRegisters=2, RegisterLengthStep=3) intrlved10, = step(con10, data10) deintrlvData, = step(deinterleaver, intrlved10)大致的执行时间是:
R2025b SP3:2.952 秒
R2025b SP4:430.100 微秒comm_HelicalInterleaver:使用螺旋数组置换输入符号;
using TyMath using TyCommunication rng = MT19937ar(1234) data = randi(rng, [0, 7], Int(5e4)) hel = comm_HelicalInterleaver(; NumColumns=500, GroupSize=100, StepSize=1) step(hel, data)大致的执行时间是:
R2025b SP3:1.930 秒
R2025b SP4:1.123 毫秒comm_HelicalDeinterleaver:使用螺旋数组恢复符号的顺序;
using TyMath using TyCommunication rng = MT19937ar(1234) data = randi(rng, [0, 7], Int(5e4)) hel = comm_HelicalInterleaver(; NumColumns=500, GroupSize=100, StepSize=1) held = comm_HelicalDeinterleaver(; NumColumns=500, GroupSize=100, StepSize=1) indata = step(hel, reshape(data, :, 1)) step(held, indata)大致的执行时间是:
R2025b SP3:2.273 秒
R2025b SP4:1.425 毫秒此代码是运行在 Windows 11 的 14 核 Intel(R) Core(TM) i7-12800H 的客户端版本 Syslab,使用 Julia @benchmark 宏进行进行计时。
comm_PhaseNoise:对基带信号添加相位噪声
重做了结构体,优化了滤波部分的算法。
using TyCommunication using TyMath Random.seed!(1234) pnoise = comm_PhaseNoise(; Level=-50, FrequencyOffset=20) M = 16 data = randi([0 M-1], 1000) modData = qammod(data, M) y = step(pnoise, modData)大致的执行时间是:
R2025b SP5:0.032651 秒
R2026a:0.0005097 秒此代码是运行在 Windows 11 的 14 核 Intel(R) Core(TM) i7-12800H 的客户端版本 Syslab,使用 Julia @benchmark 宏进行进行计时。
相控阵工具箱
- phased_CFARDetector:结构体类型稳定,优化内存分配,首次运行优化比例 39%;
- phased_MonopulseFeed:结构体类型稳定,首次运行优化比例 76%;
- getTaper:性能优化,首次运行优化比例 52%;
- aictest:性能优化,首次运行优化比例 43%;
- mdltest:性能优化,首次运行优化比例 26%;
- spsmooth:性能优化,首次运行优化比例 42%。
图像处理工具箱
-
优化了 padarray 函数最常用的 constant pad 算法,函数的执行速度得到提升。
using TyImageProcessing, TyRandom using BenchmarkTools rng = MT19937ar(5489) A = rand(rng, 500, 500) @btime padarray(A, [1 1], 2, "pre");大致的执行时间是:
R2025b SP4:18.53 毫秒
R2025b SP5:0.38 毫秒 -
优化了 imregionalmax 函数性能。
using TyImageProcessing, TyRandom using BenchmarkTools rng = MT19937ar(5489) A = rand(rng, 500, 500) * 255 A = round.(A); @btime imregionalmax(A);大致的执行时间是:
R2025b SP4:305.66 毫秒
R2025b SP5:1.880 毫秒 -
优化了 imrotate 函数性能。
using TyImageProcessing, TyRandom using BenchmarkTools rng = MT19937ar(5489) A = rand(rng, 500, 500) * 255 A = round.(A); @btime imrotate(A, 90);大致的执行时间是:
R2025b SP4:1.938 毫秒
R2025b SP5:0.36 毫秒此代码是运行在 Windows 11 的 14 核 Intel(R) Core(TM) i7-12800H 的客户端版本 Syslab,使用 Julia @benchmark 宏进行进行计时。
-
# ★科学计算 APP
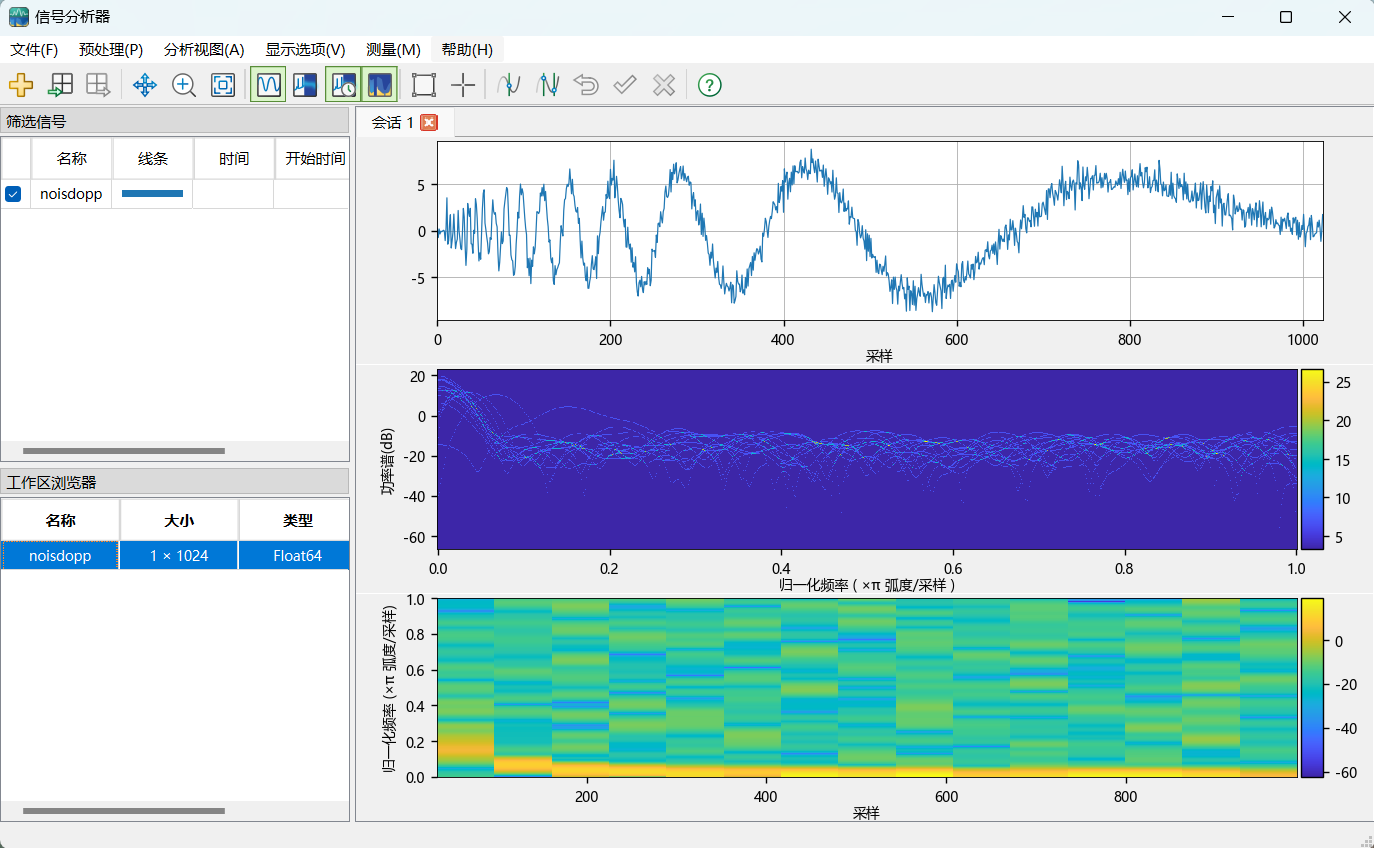
# 信号分析器(全新发布)
全新发布信号分析器 APP:信号分析器(新增)是一款交互式信号处理工具,用于在时域、频域和时频域中可视化、预处理、测量、分析和比较信号。通过此应用程序,可以轻松访问 Syslab 工作区中所有符合要求的信号,对信号进行截断、削波、拆分、提取、裁剪、滤波、去趋势、去噪等预处理操作,同时可视化和比较信号的波形、频谱、持久频谱、频谱图,测量最小值、最大值、均值、中位数、峰间、RMS 等信号统计量,支持将处理后的信号导出至 Syslab 工作区或保存为 MAT 文件。
# 滤波器可视化工具
- 修复启动函数对分子系数为标量时不兼容的问题;滤波器可视化工具支持一键关闭所有已开滤波器可视化工具窗口
- 修复复数系数时双边带相位响应在 0 点不连续的问题
# 滤波器设计工具
桌面版滤波器设计工具新增对 IIR 滤波器的结构转换选项
# 曲线拟合器工具
- 修复二维、三维自定义方程、线性拟合模型更改自变量名后表格不显示的问题
- 修复输入数据为整型时打印警告太多的问题
- 修复所有拟合选项对应的系数个数不正确的问题
# 删除或变更功能 ⚠️
# Julia 内核
Julia 内核升级引入破坏性更新 1 个。
Julia 内核升级,修改了多个元素合并类型的顺序,由逆序修改为正序,可能导致极少数特殊场景报错。
问题现象:
using Symbolics
@variables t::Real x::Number y::Complex # 旧版本正常,新版本报错
@variables y::Complex x::Number t::Real # 旧版本报错,新版本正常
问题原因:
由于该库本身的类型合并依赖合并的顺序,且 Julia 内核修改了多个元素合并类型的顺序,由逆序修改为正序,导致了上述问题。
解决方案:
对于拼接的元素,不进行类型标注,则不会产生依赖合并的顺序。
using Symbolics
@variables t x y
# Python 版本升级至 3.11.4
Python 从 3.7.5 升级至 3.11.4 原因:
- Python 3.7.5 已于 2023 年终止官方维护,无安全补丁更新,存在漏洞风险
- 现代工业级库(如 matplotlib 3.5.0=>3.7.5、numpy 1.21=>1.26 新版)逐步放弃 3.7 支持,而 Python 3.11.4 可兼容主流库,避免依赖断更
- Python 3.7.5 已于 2023 年终止官方维护,无安全补丁更新,存在漏洞风险
破坏性说明:
由于 Python 3.11.4 不支持 Win7 版本,Win7 版本会另外推出对应的安装包(Python3.7.5)
部分 Python 库升级导致的不兼容,您需要确保 Python 工程代码在 Syslab 环境中运行时的兼容性(尤其升级 Python 版本后),如有需要,可通过反馈渠道给我们反馈详细信息。下图以 numpy 升级作为示例说明:
import numpy as np arr = np.array([[1.2, 3.4], [5.6, 7.8]], dtype=np.float)# numpy 1.24+已废弃numpy.float
numpy 1.26 移除了 np.float 等废弃别名,导致 Python 3.11 环境报错;修复关键是将模糊的 np.float 替换为 float 或 np.float64,全版本兼容,需要修改成以下代码:
import numpy as np arr = np.array([[1.2, 3.4], [5.6, 7.8]], dtype=np.float64)# numpy 1.24+已废弃numpy.float
核心 python 库升级列表(minor 及以上版本变更)
库名 python 升级前 python 升级后 matplotlib 3.5.0 3.7.5 numpy 1.21.6 1.26.4 scipy 1.7.3 1.11.4 mindspore 2.1.1 2.5.0
# 数学工具箱
数学工具箱引入破坏性更新 1 个。
R2025b SP5 数学工具箱默认的线性代数底层算法库由 OpenBLAS 切换至 MKL。为保证精度,部分函数(linsolve)底层线性代数算法库仍保留为 OpenBLAS。
如果希望仍保留原本 OpenBLAS 作为底层算法库计算某段代码,可以使用 with_blas("libopenblas64_") do ... end 方式单独执行代码,例如:
using TyMath
A = [1 2; 3 4; 5 6; 7 8]
U,S,V = with_blas("libopenblas64_") do
ty_svd(A)
end
# 图形工具箱
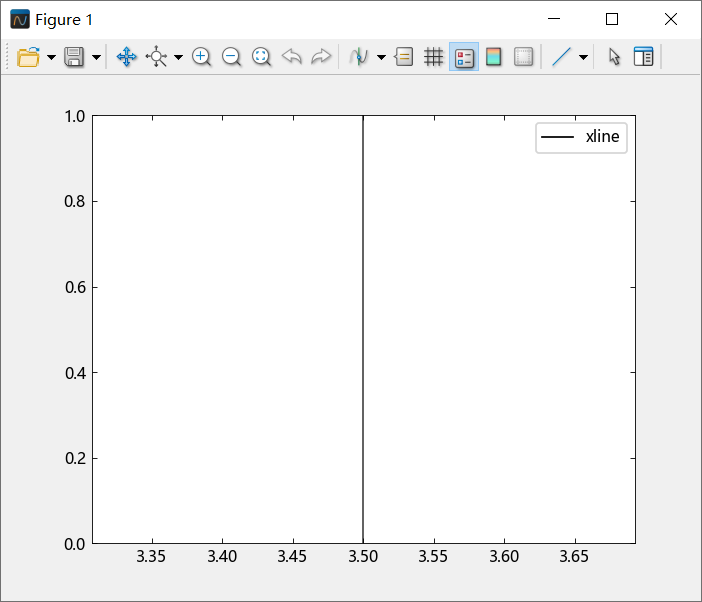
图形工具箱引入破坏性更新 1 个。
图形库函数 xline、yline 关键字参数 label 功能不再为修改图例标签。在以前的版本中,关键字参数 label 功能为修改图例标签。例如:
using TyPlot
xline(3.5;label = "xline")
legend()
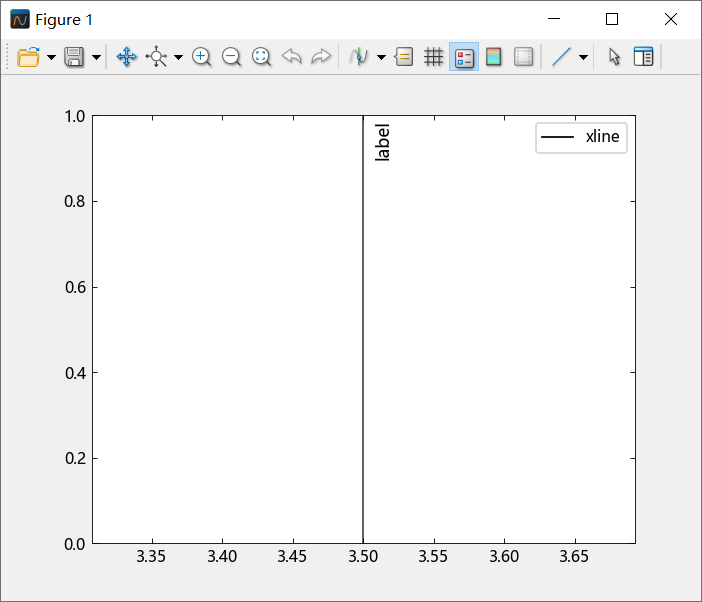
从 2026a 开始关键字参数 label 为添加行标签功能,可以通过关键字参数 displayname 修改图例标签。例如:
using TyPlot
xline(3.5;label = "label", displayname = "xline")
legend()
# 通信工具箱
通信工具箱引入破坏性更新 2 个。
comm_MultiplexedInterleaver:修改了参数:为寄存器设置初始状态时使用 InitialConditions 字段,删除了 Initstate_value、Initstate_index 字段,无需再手动输入所有寄存器的初始状态;
2025b SP3 及之前版本调用方式:
using TyCommunication intr = comm_MultiplexedInterleaver(Initstate_value=[[0 0], Matrix{Int64}(undef, 1, 0), [0;;], [0 0 0], [0 0 0 0 0 0 0 0 0 0]]', Initstate_index=1)2025b SP4 调用方式:
using TyCommunication intr = comm_MultiplexedInterleaver(InitialConditions=0)两种调用的方式生成的是功能相同的多路复用交织/解交织对象。
comm_MultiplexedDeinterleaver:修改了参数:为寄存器设置初始状态时使用 InitialConditions 字段,删除了 Initstate_value、Initstate_index 字段,无需再手动输入所有寄存器的初始状态。
2025b SP3 及之前版本调用方式:
using TyCommunication deintr = comm_MultiplexedDeinterleaver(Initstate_value=[[0 0], Matrix{Int64}(undef, 1, 0), [0;;], [0 0 0], [0 0 0 0 0 0 0 0 0 0]]', Initstate_index=1)2025b SP4 调用方式:
using TyCommunication deintr = comm_MultiplexedDeinterleaver (InitialConditions=0)两种调用的方式生成的是功能相同的多路复用交织/解交织对象。
# 附录:函数列表
# 基础工具箱
基础工具箱新增函数 1 个。
| 函数名 | 函数说明 |
|---|---|
| @include_dir | 加载指定文件夹下的 jl 文件,不会递归加载子文件中的 jl 文件 |
基础工具箱修改函数 43 个。
| 函数名 | 函数变更说明 |
|---|---|
| fullfile | 实现正确拼接路径,增加入参检测 |
| clear | 增加入参检测 |
| clc | 增加入参检测 |
| dir | 增加入参检测 |
| ty_format | 增加入参检测 |
| rmmissing | 增加入参检测 |
| ty_round | 增加入参检测 |
| bitget | 增加入参检测 |
| hex2dec | 增加入参检测 |
| strfind | 增加入参检测,并对函数性能进行了优化 |
| strcmpi | 增加入参检测 |
| regexp | 增加入参检测 |
| meshgrid2 | 增加入参检测 |
| regexprep | 修复输入参数中含特定参数时的报错问题 |
| mode | 增加入参检测 |
| bitshift | 增加入参检测 |
| ty_floor | 增加入参检测 |
| bsxfun | 增加入参检测 |
| ty_unique | 优化输入大数组时的函数性能;增加入参检测,并对 byrows=true 时输入大数组进行内存优化 |
| fopen | 增加入参检测 |
| fprintf | 增加入参检测 |
| fread | 增加入参检测,修复了指针错误定位的问题,以及修复了原先对于精度匹配(如"2*UInt16")的错误处理和报错问题 |
| fwrite | 增加入参检测 |
| fgetl | 增加入参检测 |
| fclose | 增加入参检测 |
| readtable | 增加入参检测 |
| delete | 增加入参检测;性能优化 |
| fscanf | 增加入参检测;性能优化 |
| detectImportOptions | 增加入参检测 |
| fileparts | 增加入参检测 |
| diary | 增加入参检测,增加支持使用新 io 类型来截获 stdout 的输出 |
| save | 支持追加写入 JLD2 文件时含有已存在变量名的场景;支持对 MAT 文件追加写入已存在变量名的变量 |
| addsample | 支持正确写入 Quality、支持输入空 timeseries 场景和支持时间维度不匹配场景的报错 |
| appendtimeseries | 支持 timeseries 合并时 Quality 的正确拼接 |
| delevent | 支持对于事件名使用字符串数组的输入 |
| getdatasamplesize | 修复特定场景报错的问题 |
| timeseries | 支持 AbstractFloat 类型的输入 |
| ty_issorted | 支持 AbstractArray 长度为 1 的场景 |
| xlswrite | 修复 range 超过 Z 的场景;新增参数 writemode 支持 将数据写入附加到现有文件中,而不是覆盖写入 |
| xlsread | 对于前后含有空格可转成数字的字符串进行转数字操作 |
| Importdata | 修复读取单元素电子表格不能正常显示的问题 |
| sortrows | 修复输入向量选择双输出报错的 bug |
| array2table | 性能优化 |
# 图形工具箱
图形工具箱新增函数 3 个。
| 函数名 | 函数说明 |
|---|---|
| groot | 图形根对象 |
| activate_figure | 激活图窗 |
| plt_isvalid | 确定有效句柄 |
图形工具箱修改函数 59 个。
| 函数名 | 函数变更说明 |
|---|---|
| colorbar | 修复 colobar 创建报错 |
| gca | 新增入参检查 |
| gcf | 新增入参检查 |
| savefig | 新增入参检查 |
| polarplot | 输入矩阵类型 bug 修复;入参检查;图形对象属性完善 |
| contour | 补充关键字参数;图形对象属性完善 |
| texlabel | 性能优化 |
| symvar | 性能优化 |
| pcolor | 入参检查 |
| sortx | 修复 M 兼容调用出错 |
| sorty | 修复 M 兼容调用出错 |
| grid | 支持用法 grid("minor") |
| fplot | 函数 bug 修复 |
| xlim | 修复 M 兼容调用报错 |
| ylim | 修复 M 兼容调用报错 |
| histogram2 | 修复 histogram2 存在空值报错,设置 binwidth 绘图错误 |
| stem | 完善 plt_get/plt_set 属性 |
| imagesc | 完善 plt_get/plt_set 属性;处理缩放功能 bug |
| yyaxis | 入参检查 |
| xline | 入参检查;新增用法 xline(xvalue,LineSpec,label) |
| yline | 入参检查;新增用法 yline(yvalue,LineSpec,label) |
| ginput | 入参检查 |
| loglog | 入参检查 |
| shading | 入参检查 |
| openfig | 入参检查 |
| pie | 入参检查 |
| box | 入参检查 |
| wraptopi | 入参检查 |
| linkaxes | 入参检查 |
| tightlayout | 入参检查 |
| nexttitle | 入参检查 |
| xticks | 入参检查 |
| yticks | 入参检查 |
| sgtitle | 入参检查 |
| xticklabels | 入参检查 |
| findobj | 入参检查 |
| heatmap | 入参检查 |
| plotyy | 入参检查 |
| scatter3 | 入参检查 |
| enable_show | 入参检查;修复 enable_show 函数在单机版部分场景不生效的 bug |
| bar | 支持参数 hist,histc;支持分类数组 |
| barh | 支持参数 hist,histc |
| meshc | 函数属性完善 |
| errorbar | 图形对象属性完善 |
| quiver | 图形对象属性完善 |
| heatmap | 图形对象属性完善 |
| area | 图形对象属性完善 |
| rectangle | 图形对象属性完善 |
| stairs | 图形对象属性完善 |
| polaraxes | 图形对象属性完善 |
| semilogx | 性能优化 |
| semilogy | 性能优化 |
| histcounts | 修复 histcounts 返回值错误 |
| imdistline | 无界面模式 bug 修复 |
| figure | 性能优化 |
| plot | 修复输入复数报错 |
| colormap | colormap 函数用法修改 |
| histogram | 性能优化 |
| surf | surf 图形支持按照坐标区范围裁剪对象 |
# 数学工具箱
数学工具箱新增函数 3 个。
| 函数名 | 函数说明 |
|---|---|
| mfft | 傅里叶变换(一维、二维、三维) |
| scatteredInterpolant1 | 对二维或三维散点数据插值 |
| numgrid | 对二维区域中的网格点进行编号 |
数学工具箱修改函数 21 个。
| 函数名 | 函数变更说明 |
|---|---|
| nufft | 非均匀快速傅里叶变换:提升函数运行效率 |
| filter1 | 1 维数字滤波器:提升函数运行效率 |
| isbanded | 确定矩阵是否在特定带宽范围内:提升函数运行效率 |
| detrend | 去除多项式趋势:新增支持复数输入 |
| griddata | 对二维或三维散点数据插值:新增支持 linear 外插方法,提升函数运行效率 |
| interp1 | 一维数据插值(表查找):提升函数运行效率;一维数据插值(表查找):优化 pchip 函数性能 |
| interp2 | meshgrid 格式的二维网格数据插值:提升函数运行效率;meshgrid 格式的二维网格数据插值:优化 cubic、linear 算法性能,且修复当外插未 NaN 不生效的 bug |
| interp3 | meshgrid 格式的三维网格数据的插值:优化 cubic、spline、nearest 算法性能 |
| Graph | 具备无向边的图:修复不支持空图的 bug |
| conv2 | 二维卷积:提升函数运行效率 |
| nextpow2 | 2 的更高次幂的指数:修复函数 bug |
| cart2pol | 将笛卡尔坐标转换为极坐标或柱坐标:修复函数 bug |
| cart2sph | 将笛卡尔坐标转换为球面坐标:修复函数 bug |
| pol2cart | 将极坐标或柱坐标转换为笛卡尔坐标:修复函数 bug |
| treelayout | 设置树或森林的布局:修复函数 bug |
| detrend | 去除多项式趋势:修复函数 bug |
| ppval | 计算分段多项式:优化了函数运行速度 |
| padecoef | 时滞的 Padé 逼近:优化函数性能 |
| pchip | 分段三次 Hermite 插值多项式(PCHIP):优化函数性能 |
| delaunay | Delaunay 三角剖分:优化函数性能,修复一些四点共圆情况的 bug |
| mfft | 傅里叶变换 (一维、二维、多维):修复函数 bug |
# 符号数学工具箱
符号数学工具箱新增函数 1 个。
| 函数名 | 函数说明 |
|---|---|
| sym_gcd | 求最大公约数 |
符号数学工具箱修改函数 6 个。
| 函数名 | 函数变更说明 |
|---|---|
| numden | 提取分子和分母:增加接口控制是否约分化简 |
| sym_collect | 收集系数:增加接口控制升序或降序 |
| dsolve | 解微分方程组:修复函数 bug |
| ^ | 符号矩阵幂:修复函数 bug |
| sym_svd | 符号矩阵奇异值分解:修复函数 bug |
| int | 定积分和不定积分:修复函数 bug |
# 曲线拟合工具箱
曲线拟合工具箱修改函数 11 个。
| 函数名 | 函数变更说明 |
|---|---|
| dependnames | FitResult 或 FitType 对象的因变量名:优化函数运行速度 |
| indepnames | FitResult 或 FitType 对象的自变量名:优化函数运行速度 |
| probnames | FitResult 或 FitType 对象的问题参数名:优化函数运行速度 |
| islinear | 判断 FitResult 或 FitType 对象是否线性:优化函数运行速度 |
| coeffnames | FitType 对象的系数名:优化函数运行速度:优化函数运行速度 |
| typecur | FitResult 或 FitType 对象的名称:优化函数运行速度 |
| formula | FitResult 或 FitType 对象的公式:优化函数运行速度 |
| fit | 为数据拟合曲线或曲面:优化函数运行速度;修复一些函数 bug |
| numcoeffs | FitResult 或 FitType 对象的参数个数:优化函数运行速度 |
| integrate | 积分 FitResult 对象:优化函数运行速度 |
| excludedata | 从拟合中排除数据:优化函数性能 |
# 统计工具箱
统计工具箱修改函数 24 个。
| 函数名 | 函数变更说明 |
|---|---|
| mle | 最大似然估计:修改 Rician 分布的 bug;提升函数运行效率(Rician 分布,gamma 分布、Nakagamil 分布);优化了 lognormal 分布、Loglogistic 分布运行速度 |
| andrewsplot | 安德鲁斯图:新增指定 x 轴范围的选项 |
| gamfit | Gamma 参数估计:提升函数运行效率 |
| gamlike | Gamma 负对数似然:提升函数运行效率 |
| fitdist | 对数据进行概率分布对象拟合:提升函数运行效率(Rician 分布,gamma 分布、Nakagami 分布、kernel 分布);优化了 ExtremeValue 分布、Weibull 分布,GeneralizedExtremeValue 分布、halfnormal 分布、Rayleigh 分布、lognormal 分布、Loglogistic 分布运行速度,新增支持 tLocationScale 分布 |
| cdf | 累积分布函数:提升函数运行效率(paretotails 分布) |
| 概率密度函数:提升函数运行效率(paretotails 分布) | |
| paretotails | 具有 Pareto 尾部的广义帕累托分布:提升函数运行效率 |
| boundary | 帕累托分布边界:提升函数运行效率 |
| nsegments | 广义帕累托分布中的段数:提升函数运行效率 |
| random | 随机数:提升函数运行效率,新增支持 kernel 分布;随机数:新增支持 rician,inversegaussian 分布 |
| gpfit | 广义帕累托分布参数估计:提升函数运行效率 |
| mean | 计算均值:新增支持 kernel 分布 |
| var | 样本方差:新增支持 kernel 分布 |
| std | 样本标准差:新增支持 kernel 分布 |
| icdf | 逆累积分布函数:新增支持 kernel 分布 |
| median | 概率分布的中位数:新增支持 kernel 分布 |
| ncx2pdf | 非中心卡方分布概率密度函数:提升函数运行效率 |
| unifit | 连续均匀分布参数估计:提升函数运行效率 |
| chi2gof | 卡方拟合优度检验:提升函数运行效率 |
| scatterhist | 带边缘直方图的散点图:修复 kernel 关键字参数为 overlay 时报错; 修复函数 bug |
| lillietest | Lilliefors 检验:修复函数 bug |
| movmad | 移动中位数绝对偏差:优化函数性能 |
| hist3 | 双变量直方图:修复当 plot =false 时 绘空窗口的 bug |
# 优化工具箱
优化工具箱修改函数 7 个。
| 函数名 | 函数变更说明 |
|---|---|
| fminunc | 求无约束多变量函数的最小值:修正输出 Hessian 矩阵的非对称异常,提升计算 Hessian 矩阵的运算效率 |
| fmincon | 寻找约束非线性多变量函数的最小值:提升函数运行效率;寻找约束非线性多变量函数的最小值:新增支持 sqp-legacy 算法选项 |
| lsqlin | 求解约束线性最小二乘问题:新增支持 interior-point 算法;提升函数运行效率 |
| lsqnonlin | 求解非线性最小二乘(非线性数据拟合)问题:新增支持 interior-point 算法,兼容数组初值与数组边界 |
| lsqcurvefit | 用最小二乘求解非线性曲线拟合(数据拟合)问题:新增支持 interior-point 算法 |
| quadprog | 二次规划:提升函数运行效率 |
| fminsearch | 使用无导数法计算无约束的多变量函数的最小值:提升函数运行效率 |
# 全局优化工具箱
全局优化工具箱修改函数 1 个。
| 函数名 | 函数说明 |
|---|---|
| paretosearch | 寻找帕累托解集:提升函数运行效率 |
# 信号处理工具箱
信号处理工具箱修改函数 12 个。
| 函数名 | 函数变更说明 |
|---|---|
| sinad | 修改了函数内部调用 |
| thd | 修复了函数内部会修改输入值的问题,优化了性能 |
| snr | 优化了性能 |
| sfdr | 修复了函数内部会修改输入值的问题,优化了性能 |
| medfreq | 修改了函数内部调用 |
| fvtool | 修复了复数系数双边相位响应不连续的问题 |
| freqz | 修改了部分内部派发 |
| filtfilt | 修改了部分内部派发 |
| ss2zp | 修改了部分内部派发 |
| firls | 优化性能,内部 sin 积分算法替换 |
| zplane | 删除了部分依赖 |
| medfilt1 | 优化性能,重做了算法 |
# DSP 系统工具箱
DSP 系统工具箱修改函数 1 个。
| 函数名 | 函数说明 |
|---|---|
| dsp_SpectrumAnalyzer | 新增关键字参数 unit,referenceload |
# 通信工具箱
通信工具箱新增函数 1 个。
| 函数名 | 函数说明 |
|---|---|
| mlseeq | 使用最大似然估计 (MLSE) 对线性调制信号进行均衡 |
通信工具箱修改函数 21 个。
| 函数名 | 函数变更说明 |
|---|---|
| block_decode | 函数优化,修复部分 bug |
| syndtable | 函数优化 |
| comm_LDPCDecoder | 传入稠密校验矩阵时,作为稀疏矩阵索引进行处理;修复了 FinalParityChecksOutputPort 为 true,NumIterationsOutputPort 为 false 时报错的问题 |
| comm_LDPCEncoder | 传入稠密校验矩阵时,作为稀疏矩阵索引进行处理 |
| mskdemod | 修复了矩阵输入时的部分问题 |
| muxintrlv | 优化寄存器移位部分的核心算法 |
| muxdeintrlv | 优化寄存器移位部分的核心算法 |
| convintrlv | 优化寄存器移位部分的核心算法 |
| convdeintrlv | 优化寄存器移位部分的核心算法 |
| helintrv | 优化寄存器移位部分的核心算法 |
| heldeintrlv | 优化寄存器移位部分的核心算法 |
| comm_ConvolutionalInterleaver | 优化了函数执行流程与核心算法,减少了冗余计算 |
| comm_ConvolutionalDeinterleaver | 优化了函数执行流程与核心算法,减少了冗余计算 |
| comm_HelicalInterleaver | 优化了函数执行流程与核心算法,减少了冗余计算 |
| comm_HelicalDeintrleaver | 优化了函数执行流程与核心算法,减少了冗余计算 |
| comm_MultiplexedInterleaver | 优化了函数执行流程与核心算法,减少了冗余计算。为寄存器设置初始状态时使用 InitialConditions 字段,删除了 Initstate_value、Initstate_index 字段。 |
| comm_MultiplexedDeinterleaver | 优化了函数执行流程与核心算法,减少了冗余计算。为寄存器设置初始状态时使用 InitialConditions 字段,删除了 Initstate_value、Initstate_index 字段。 |
| pskdemod | 修复了输出类型为 llr,且自定义符号顺序 bug |
| blkdiagbfweights | 修复了函数计算结果的错误 |
| comm_MLSEEqualizer | 修复了当状态数为 1 时算法无法正确工作的问题 |
| comm_PhaseNoise | 重做算法,新版算法解决了在采样率较高时,在低频处相噪拟合精度差的问题;解决了滤波器群延迟导致部分情况下 step 后数据未添加相噪的问题;更新后的 comm_PhaseNoise 不再支持修改一个不同类型的 FrequencyOffset 或 Level。例如,pn =comm_PhaseNoise(Level=[-90,-100]),此后无法令 pn.Level = -90(由向量修改为标量) |
# 相控阵工具箱
相控阵工具箱新增函数 3 个。
| 函数名 | 函数说明 |
|---|---|
| phased_WidebandLOSChannel | 宽带视距 LOS 传播信道 |
| phased_RangeEstimator | 距离估计 |
| phased_PhaseCodedWaveform | 新增相位编码波形函数 |
相控阵工具箱修改函数 8 个。
| 函数名 | 函数变更说明 |
|---|---|
| phased_CFARDetector | 用法不变,提高函数运行效率 |
| phased_MonopulseFeed | 用法不变,提高函数运行效率 |
| getTaper | 用法不变,提高函数运行效率 |
| aictest | 用法不变,提高函数运行效率 |
| mdltest | 用法不变,提高函数运行效率 |
| spsmooth | 用法不变,提高函数运行效率 |
| stokes | 入参检查 |
| azelaxes | 入参检查 |
# 雷达工具箱
雷达工具箱修改函数 1 个。
| 函数名 | 函数变更说明 |
|---|---|
| radarpropfactor | 修复绘图不兼容的问题 |
# 射频工具箱
射频工具箱新增函数 16 个。
| 函数名 | 函数说明 |
|---|---|
| gamma2z | 将反射系数转换为阻抗 |
| gammaml | 计算两端口网络的负载反射系数 |
| gammams | 计算两端口网络的源反射系数 |
| gammaout | 计算两端口网络的输出反射系数 |
| gammain | 计算两端口网络的输入反射系数 |
| z2gamma | 将阻抗转换为反射系数 |
| powergain | 根据两端口 S 参数计算功率增益 |
| vswr | 给定反射系数 Γ 下的电压驻波比 |
| stabilityk | 两端口网络的稳定性因子 K |
| stabilitymu | 两端口网络的稳定性因子 μ |
| s2rlgc | 将 S 参数转换为 RLGC 传输线参数 |
| s2t | 将 S 参数转换为 T 参数 |
| g2h | 将 g 参数转换为混合 h 参数 |
| t2s | 将 T 参数转换为 S 参数 |
| smm2s | 将混合模式 2N 端口 S 参数转换为单端 4N 端口 S 参数 |
| rlgc2s | 将 RLGC 传输线参数转换为 S 参数 |
# 控制系统工具箱
控制系统工具箱新增函数 5 个。
| 函数名 | 函数说明 |
|---|---|
| namedTF | 创建带有名称标签的传递函数模型 |
| namedSS | 创建带有名称标签的状态空间模型 |
| AnalysisPoint | 控制设计模块,用于将控制系统模型中的位置标记为线性分析和控制器调整的兴趣点。 |
| getIOTransfer | 广义控制系统模型的闭环传递函数 |
| sumblk | 基于名称的互连求和连接 |
控制系统工具箱修改函数 13 个。
| 函数名 | 函数变更说明 |
|---|---|
| step | 修复时域响应计算时可能的内存溢出问题;添加用法,支持 y,t,x,ysd = step(___,config; fig = false)返回数据 |
| stepplot | 修复时域响应计算时可能的内存溢出问题 |
| stepdata | 修复时域响应计算时可能的内存溢出问题 |
| impulse | 修复时域响应计算时可能的内存溢出问题 |
| impulseplot | 修复时域响应计算时可能的内存溢出问题 |
| impulsedata | 修复时域响应计算时可能的内存溢出问题 |
| initial | 修复时域响应计算时可能的内存溢出问题 |
| initialplot | 修复时域响应计算时可能的内存溢出问题 |
| initialdata | 修复时域响应计算时可能的内存溢出问题 |
| pid | 完善数据显示 |
| pid2 | 完善数据显示 |
| pidstd | 完善数据显示 |
| pidstd2 | 完善数据显示 |
# 系统辨识工具箱
系统辨识工具箱修改函数 31 个。
| 函数名 | 函数变更说明 |
|---|---|
| detrend | 错误提示修改,新增入参检测 |
| ifft | 错误提示修改,新增入参检测 |
| chgFreqUnit | 错误提示修改,新增入参检测 |
| idinput | 错误提示修改,新增入参检测 |
| setpvec | 错误提示修改,新增入参检测 |
| lsim | 错误提示修改,新增入参检测;修复越界导致的性能缺陷问题 |
| coherence | 错误提示修改,新增入参检测 |
| cra | 错误提示修改,新增入参检测 |
| ar | 错误提示修改,新增入参检测 |
| arma | 错误提示修改,新增入参检测 |
| arma_ssa | 错误提示修改,新增入参检测 |
| armax | 错误提示修改,新增入参检测 |
| arx | 错误提示修改,新增入参检测 |
| arxar | 错误提示修改,新增入参检测 |
| bj | 错误提示修改,新增入参检测 |
| oe | 错误提示修改,新增入参检测 |
| pem | 错误提示修改,新增入参检测 |
| polyest | 错误提示修改,新增入参检测 |
| n4sid | 错误提示修改,新增入参检测;修复越界导致的性能缺陷问题 |
| subSpaceid | 错误提示修改,新增入参检测 |
| tfest | 错误提示修改,新增入参检测;修复拟合不精准问题;优化拟合效果 |
| estimate_x0 | 错误提示修改,新增入参检测 |
| iddata | 错误提示修改,新增入参检测 |
| idfrd | 错误提示修改 |
| idgrey | 错误提示修改;修复传参类型不支持问题 |
| init | 错误提示修改 |
| sensitivity | 错误提示修改 |
| bode | 错误提示修改,新增入参检测 |
| compare | 错误提示修改 |
| greyest | 新增 greyestOption:lsqnonline 优化算法;优化拟合效果 |
| findstates | 修复越界导致的性能缺陷问题 |
# 鲁棒控制工具箱
鲁棒控制工具箱修改函数 14 个。
| 函数名 | 函数变更说明 |
|---|---|
| augw | 错误提示修改,新增入参检测 |
| makeweight | 错误提示修改,新增入参检测 |
| mixsyn | 错误提示修改,新增入参检测 |
| umat | 错误提示修改,新增入参检测 |
| diag | 错误提示修改,新增入参检测 |
| uss | 错误提示修改,新增入参检测 |
| balancmr | 错误提示修改,新增入参检测 |
| bstmr | 错误提示修改,新增入参检测 |
| hankelmr | 错误提示修改,新增入参检测 |
| ncfmr | 错误提示修改,新增入参检测 |
| schurmr | 错误提示修改,新增入参检测 |
| reduce | 错误提示修改,新增入参检测 |
| hinfsyn | 错误提示修改,新增入参检测 |
| diskmargin | 修复数学库引起的衰退问题 |
# 图像处理工具箱
图像处理工具箱新增函数 1 个。
| 函数名 | 函数说明 |
|---|---|
| pcwrite | 3D 点云数据保存功能 |
图像处理工具箱修改函数 30 个。
| 函数名 | 函数变更说明 |
|---|---|
| imread | 优化读取.TIF 序列文件时报错 bug |
| imfilter | 修复报错提示信息中的变量名错误 |
| imhistmatch | 修复多重判断时,变量名错误 bug |
| imreducehaze | 修复报错提示信息中的变量名错误 |
| imregionalmax | 修复报错提示信息中的变量名错误;优化 imregionalmax 函数性能 |
| stdfilt | 修复基于 std 的箱体滤波计算 bug;新增输入数组超过 3 维的报错提示 |
| imrotate | 优化函数功能实现 |
| integralBoxFilter | 支持 4 维及以上数组;新增对 4 维及以上数组的支持 |
| ORBPoints | 修复输入有 NaN 时的异常报错 |
| bwlookup | 新增输入数组为空时的报错提示 |
| bwmorph | 新增输入数组为空时的报错提示 |
| bwperim | 新增输入数组为空时的报错提示 |
| image | 新增 python3.11.4 的兼容;hold on 时绘图 y 轴坐标调整,对标 MATLAB |
| bwboundaries | 修复输入为空数组时的报错 |
| bwulterode | 修复输入为空数组时的报错 |
| bwhitmiss | 修复输入为空数组时的报错 |
| xyz2double | 补充异常输入时的报错提示帮助文档链接 |
| xyz2uint16 | 补充异常输入时的报错提示 |
| padarray | 优化 padarray 函数性能 |
| pcread | 新增支持对.ply, .pcd 格式数据的 color, normal, intensity 字段读取 |
| imshow | 新增跳过多线程处理 |
| drawcircle | 新增跳过多线程处理 |
| drawellipse | 新增跳过多线程处理 |
| drawrectangle | 新增跳过多线程处理 |
| getframe | 新增跳过多线程处理 |
| hasframe | 新增跳过多线程处理 |
| imdistline | 新增跳过多线程处理 |
| imfinfo | 新增跳过多线程处理 |
| montage | 新增跳过多线程处理 |
| readFrame | 新增跳过多线程处理 |
# 机器学习工具箱
机器学习工具箱修改函数 15 个。
| 函数名 | 函数变更说明 |
|---|---|
| view | 增加入参检查;兼容 python3.11 |
| test | 增加入参检查,添加 i=0 时输出全折测试掩码矩阵的功能 |
| partialDependence | 兼容 python3.11 |
| fitsemigraph | 兼容 python3.11 |
| fitsemiself | 兼容 python3.11 |
| kmeans | 兼容 python3.11 |
| ridge | 兼容 python3.11 |
| evfit | 移除对 TyOptimization 与 TyStatistics 的依赖 |
| HistcGradientBoosting | 兼容 python3.11 |
| tsne | 兼容 python3.11 |
| lasso | 兼容 python3.11 |
| dummyvar | 兼容 python3.11 |
| AdaBoostrTree | 兼容 python3.11 |
| kmedoids | 修复在出现空簇时的断言失败问题 |
| SVRbagger | 兼容 python3.11 |
# 深度学习工具箱
深度学习工具箱修改函数 6 个。
| 函数名 | 函数变更说明 |
|---|---|
| dataset_dir | 增加入参检查 |
| trainNetwork | 兼容 python3.11 |
| envinit | 兼容 python3.11 |
| align | 兼容 python3.11 |
| softmax | 兼容 python3.11 |
| softmaxLayer | 使用自定义的 StableSoftmax 以避免训练出现 NaN |
# M 兼容新增函数
M 兼容新增 52 个 M 函数,当前共提供 2033 个 M 函数及帮助文档。
| 函数名 | 函数说明 |
|---|---|
| lineprof | 探查函数执行时间 |
| profile | 探查脚本的执行时间 |
| fdesign_lowpass | 低通滤波器规格 |
| ga | 用遗传算法求函数的最小值 |
| diary | 将命令行窗口文本记录到日志文件中 |
| reordercats | 对 categorical 数组中的类别重新排序 |
| hex | fi 对象的存储整数的十六进制表示 |
| rotx | 绕 x 轴旋转的旋转矩阵 |
| roty | 绕 y 轴旋转的旋转矩阵 |
| rotz | 绕 z 轴旋转的旋转矩阵 |
| fmmod | 调频 |
| uigetfile | 打开文件选择对话框 |
| msgbox | 创建消息对话框 |
| matfile | 访问和更改 MAT 文件中的变量,而不必将文件加载到内存中 |
| restoredefaultpath | 将搜索路径还原为出厂安装时的状态 |
| genvarname | 从字符串构造有效的变量名称 |
| wdenoise | 小波信号去噪 |
| mlseeq | 使用最大似然序列估计均衡线性调制信号 |
| spdiags | 提取非零对角线并创建稀疏带状对角矩阵 |
| dsolve | 解微分方程组 |
| pagemldivide | 逐页矩阵左除 |
| s2s | 将 S 参数转换为具有不同阻抗的 S 参数 |
| timeit | 测量运行函数所需的时间 |
| spalloc | 为稀疏矩阵分配空间 |
| spfun | 将函数应用于非零稀疏矩阵元素 |
| spones | 将非零稀疏矩阵元素替换为一 |
| sprandsym | 稀疏对称随机矩阵 |
| doppler | 构建多普勒频谱结构 |
| roifill | (不推荐)在灰度图像中填充指定的感兴趣区域(ROI 多边形) |
| mvnrnd | 多元正态随机数 |
| cholcov | Cholesky 类协方差分解 |
| dsp.SineWave | 产生离散正弦波 |
| comm.PhaseNoise | 对基带信号添加相位噪声 |
| dlmread | (不推荐)将 ASCII 分隔的数值数据文件读取到矩阵 |
| isvalid | 确定有效句柄 |
| waitbar | 创建或更新等待条对话框 |
| inputParser | 函数的输入解析器 |
| parse | 解析函数输入 |
| mxGetIr | 稀疏矩阵 IR 数组 |
| mxGetJc | 稀疏矩阵 JC 数组 |
| mxGetPr | 获取数组中实数数据元素 |
| mxCreateSparse | 2-D 稀疏矩阵 |
| mxIsLogicalScalar | 判断标量数组是否为 mxLogical 类型 |
| mxCreateLogicalScalar | 创建逻辑值标量 |
| mxIsSparse | 判断输入的 mxArray 是否为稀疏矩阵 |
| mxDestroyArray | 释放通过 MXCREATE* 系列函数分配的动态内存 |
| mex | 编译 MEX 函数和引擎或 MAT 文件应用程序 |
| mexFunction | 使用 C Matrix API 编译的 C/C++ MEX 函数的入口函数 |
| pcwrite | 给 PLY 或 PCD 文件中写入三维点云数据 |
| getIOTransfer | 广义控制系统模型的闭环传递函数 |
| sumblk | 基于名称进行互连的求和点 |
| AnalysisPoint | 线性分析点 |