# importdata
从文件加载数据
# 语法
A = importdata(filename)
A = importdata('-pastespecial')
A = importdata(___,delimiterIn)
A = importdata(___,delimiterIn,headerlinesIn)
[A,delimiterOut,headerlinesOut] = importdata(___)
# 说明
A = importdata(filename) 将数据加载到数组 A 中。示例
A = importdata('-pastespecial') 从系统剪贴板而不是文件加载数据。示例
A = importdata(___,delimiterIn) 将 delimiterIn 解释为 ASCII 文件 filename 或剪贴板数据中的列分隔符。您可以将 delimiterIn 与以上语法中的任何输入参数结合使用。
A = importdata(___,delimiterIn,headerlinesIn) 从 ASCII 文件 filename 或剪贴板加载数据,并读取从第 headerlinesIn+1 行开始的数值数据。示例
[A,delimiterOut,headerlinesOut] = importdata(___) 使用先前语法中的任何输入参数,在 delimiterOut 中额外返回检测到的输入 ASCII 文件中的分隔符,以及在 headerlinesOut 中返回检测到的标题行数。示例
注意
在 Linux 系统下,若使用 importdata("-pastespecial") 从系统剪切板加载数据,系统需安装 xsel 或 xclip 库。
# 示例
导入并显示图像
导出并显示示例图像 ngc6543a.jpg。
A = importdata('ngc6543a.jpg');
image(A)
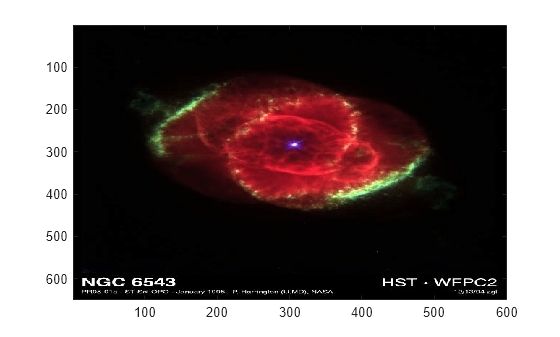
输出 A 为 uint8 类,因为辅助函数 imread 对 colormap 和 alpha 返回空结果。
导入文本文件并指定分隔符和列标题
使用文本编辑器创建一个带有列标题的称为 myfile01.txt 的空格分隔 ASCII 文件。
Day1 Day2 Day3 Day4 Day5 Day6 Day7
95.01 76.21 61.54 40.57 5.79 20.28 1.53
23.11 45.65 79.19 93.55 35.29 19.87 74.68
60.68 1.85 92.18 91.69 81.32 60.38 44.51
48.60 82.14 73.82 41.03 0.99 27.22 93.18
89.13 44.47 17.63 89.36 13.89 19.88 46.60
导入该文件并指定空格分隔符和单个列标题。
filename = 'myfile01.txt';
delimiterIn = ' ';
headerlinesIn = 1;
A = importdata(filename,delimiterIn,headerlinesIn);
查看第 3 列和第 5 列。
for k = [3, 5]
disp(A.colheaders{1, k})
disp(A.data(:, k))
disp(' ')
end
Day3
61.5400
79.1900
92.1800
73.8200
17.6300
Day5
5.7900
35.2900
81.3200
0.9900
13.8900
导入文本文件并返回检测到的分隔符
使用文本编辑器创建一个称为 myfile02.txt 的逗号分隔 ASCII 文件。
1,2,3
4,5,6
7,8,9
导入该文件并显示输出数据和检测到的分隔符。
filename = 'myfile02.txt';
[A,delimiterOut]=importdata(filename)
A =
1 2 3
4 5 6
7 8 9
delimiterOut =
','
从剪贴板导入数据
将以下行复制到剪贴板。选择相应文本,右键点击,然后选择复制。
1,2,3
4,5,6
7,8,9
键入以下内容将剪贴板数据导入到 MLang 中。
A = importdata('-pastespecial')
A =
1 2 3
4 5 6
7 8 9
导入电子表格
导出电子表格文件 test_importdata.xlsx,并显示输出数据。
data = importdata("test_importdata.xlsx")
data =
1x1 struct
textdata: 1x4 cell
data: 11x4 double
colheaders: 1x4 cell
写入电子表格文件并查看
使用 writematrix 创建一个多页的含标题电子表格文件。
filename = 'test.xlsx';
M1 = ["a", "b", "c"; 1, 2, 3];
M2 = [4, 5, 6];
writematrix(M1, filename, 'Sheet', 'Sheet1');
writematrix(M2, filename, 'Sheet', 'Sheet2');
对于多页并且含标题的电子表格,需要使用对应字段访问。
查看 Sheet2 的数字数据。
A = importdata(filename)
A.data.Sheet2
ans =
4 5 6
查看 Sheet1 的文本数据。
A.textdata.Sheet1
ans =
2x3 cell
{'a'} {'b'} {'c'}
{'1'} {'2'} {'3'}
# 输入参数
filename - 要导入的文件的名称和扩展名字符串
要导入的文件的名称和扩展名,指定为字符串。如果 importdata 可识别文件扩展名,则会调用用于导入关联的文件格式的 Syslab 辅助函数(如用于 MAT 文件的 load)或调用 XLSX 库进行读取处理。否则,importdata 会将文件解释为分隔的 ASCII 文件。
对于 ASCII 文件和电子表格,importdata 预计会查找矩形格式(即像矩阵一样)的数值数据。文本标题可显示在数值数据的上方或左侧,如下所示:
文件顶部的列标题或文件说明文本,位于数值数据上方;
数值数据左侧的行标题。
示例: 'myFile.jpg'
数据类型: char | string
delimiterIn - 列分隔符字符串
列分隔符,指定为字符串。默认字符根据文件进行解释。对选项卡使用 '\t'。
示例: ','
示例: ' '
数据类型: char | string
headerlinesIn - ASCII 文件中的文本标题行数非负整数标量
ASCII 文件中的文本标题行数,指定为非负整数标量。如果您不指定 headerlinesIn,importdata 函数将会在文件中检测该值。
数据类型: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
# 输出参数
A - 文件中的数据矩阵 | 多维数组 | 字典
文件中的数据,以矩阵、多维数组或字典形式返回,具体取决于文件的特征。根据输入文件的文件格式,importdata 会调用辅助函数来读取数据。当辅助函数返回多个非空输出时,importdata 会将这些输出组合成一个 struct 数组。
下表列出了与可返回多个输出的辅助函数关联的文件格式,以及字典 A 中的可能字段。
| 文件格式 | 可能的字段 | 类 |
|---|---|---|
| MAT 文件 | 每个字段对应一个变量 | 与每个变量关联。 |
| ASCII 文件和电子表格 | data textdata colheaders | 对于 ASCII 文件,data 包含一个 double 数组。其他字段包含字符串数组。textdata 包含行标题和列标题。对于电子表格,每个字段包含一个字典,并且每个字段对应一个工作表。 |
| 图像 | cdata colormap alpha | 请参阅 imread。 |
用于支持的大多数其他文件格式的 MLang 辅助函数返回一个输出。有关每个输出的类的详细信息,请参阅支持的导入和导出文件格式中列出的函数。
如果 ASCII 文件或电子表格包含列标题,importdata 会在输出字典中返回 colheaders ,其中:
colheaders 仅包含最后一行列标题文本。importdata 将所有文本都存储在 textdata 字段中。
delimiterOut - 在输入 ASCII 文件中检测到的列分隔符字符向量
在输入 ASCII 文件中检测到的列分隔符,以字符向量形式返回。
headerlinesOut - 在输入 ASCII 文件中检测到的文本标题行数整数
在输入 ASCII 文件中检测到的文本标题行数,以整数形式返回。