# 编辑、运行与调试
本文将介绍 Syslab 软件编辑、运行和调试的常见问题及解决方案。
# 资源管理器未自动刷新
# 问题描述
在资源管理器中打开的文件夹包含大量文件时,新文件生成后资源管理器不会自动刷新,需要手动刷新资源管理器。
# 问题原因
资源管理器中打开文件夹后,Syslab 会监视该文件夹下所有文件,造成 CPU 和内存的消耗,当用户打开的文件夹下的文件数量达到了系统设置的文件监视上限时(Linux 系统默认是 16384 个),Syslab 只能监视到文件的修改,无法监视到新生成的文件,需要手动刷新资源管理器。
# 解决方法
针对大型文件夹,Syslab 提供了files.watcherExclude配置,用于排除不必要的文件监听,有效避免用户手动刷新资源管理器。操作步骤如下:
- 在 Syslab 左侧边栏打开设置。
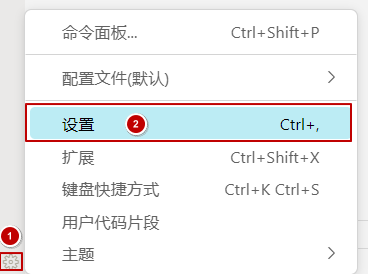
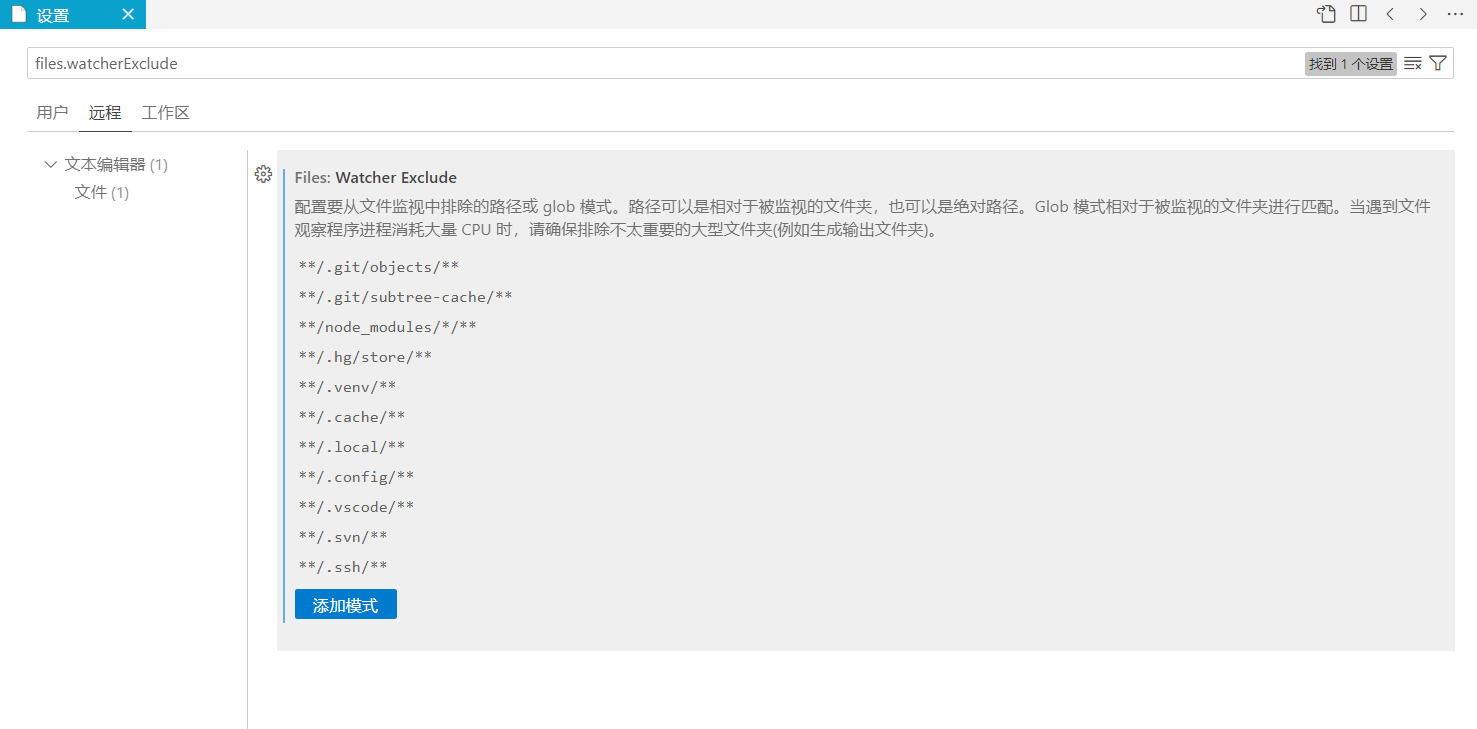
- 在搜索框输入 files.watcherExclude,找到下图所示的文件监视配置项,点击添加模式,配置要从文件监视中排除的路径。
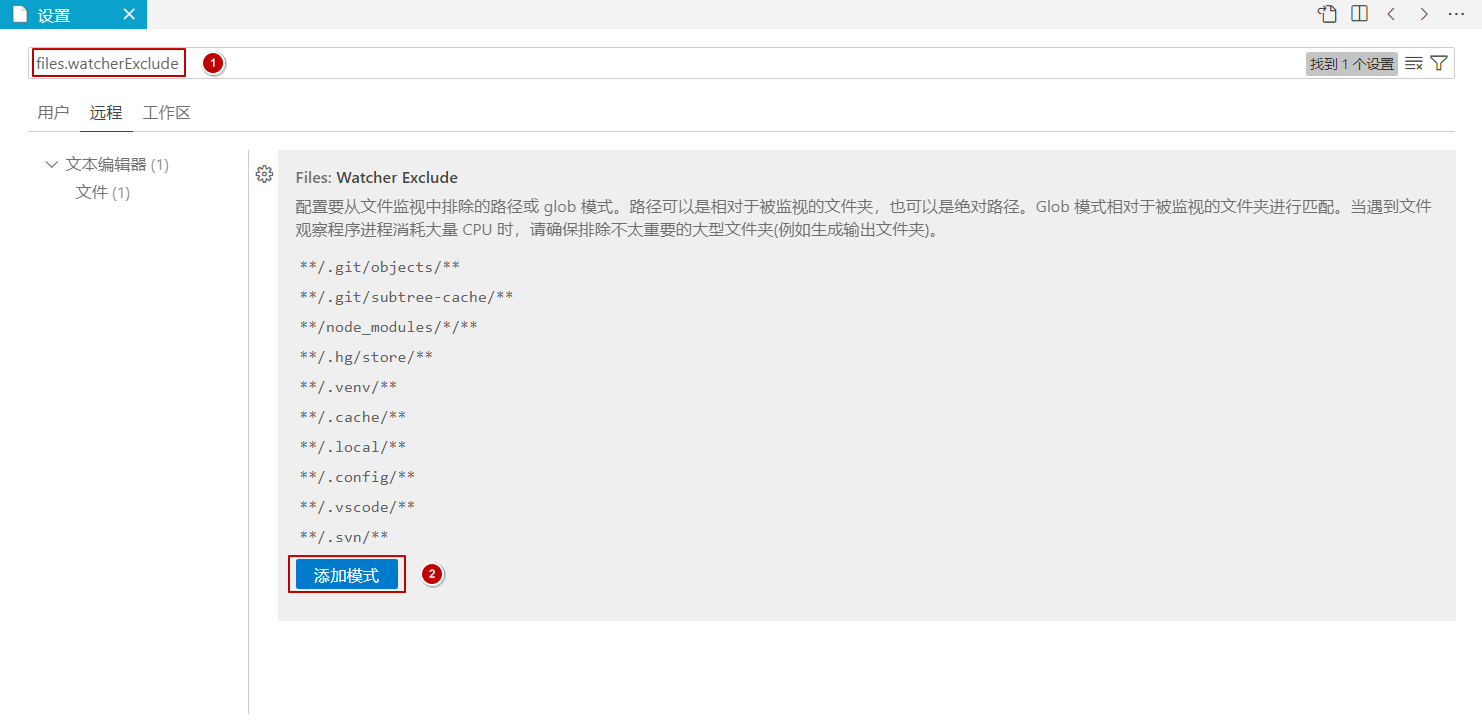
- 如下图所示在输入框输入要从文件监视中排除的路径,如 .ssh 文件夹,配置完成后点击确定即可。
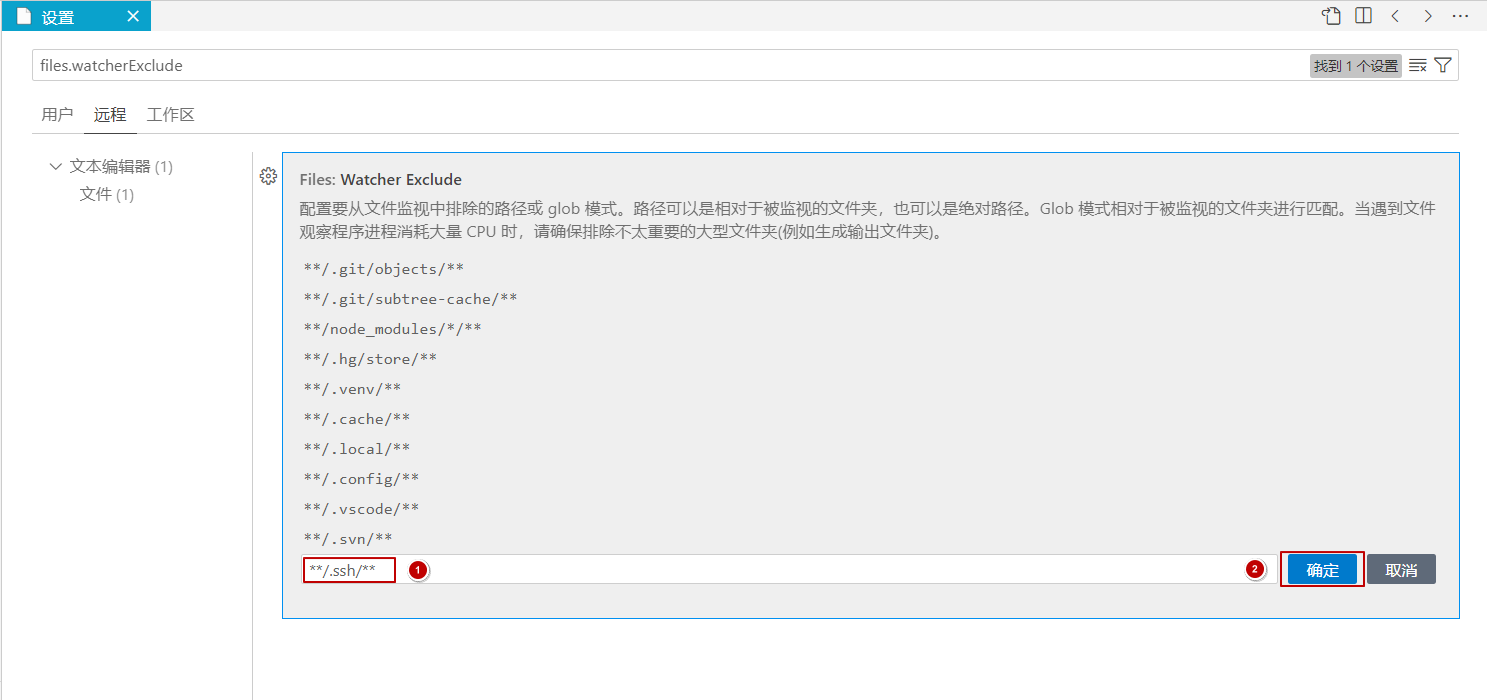
- 配置完成后效果。
# julia 命令行窗口加载函数库,长时间不响应
# 问题描述
启动 julia 命令行窗口,加载函数库过程中长时间不响应,函数库无法加载成功。
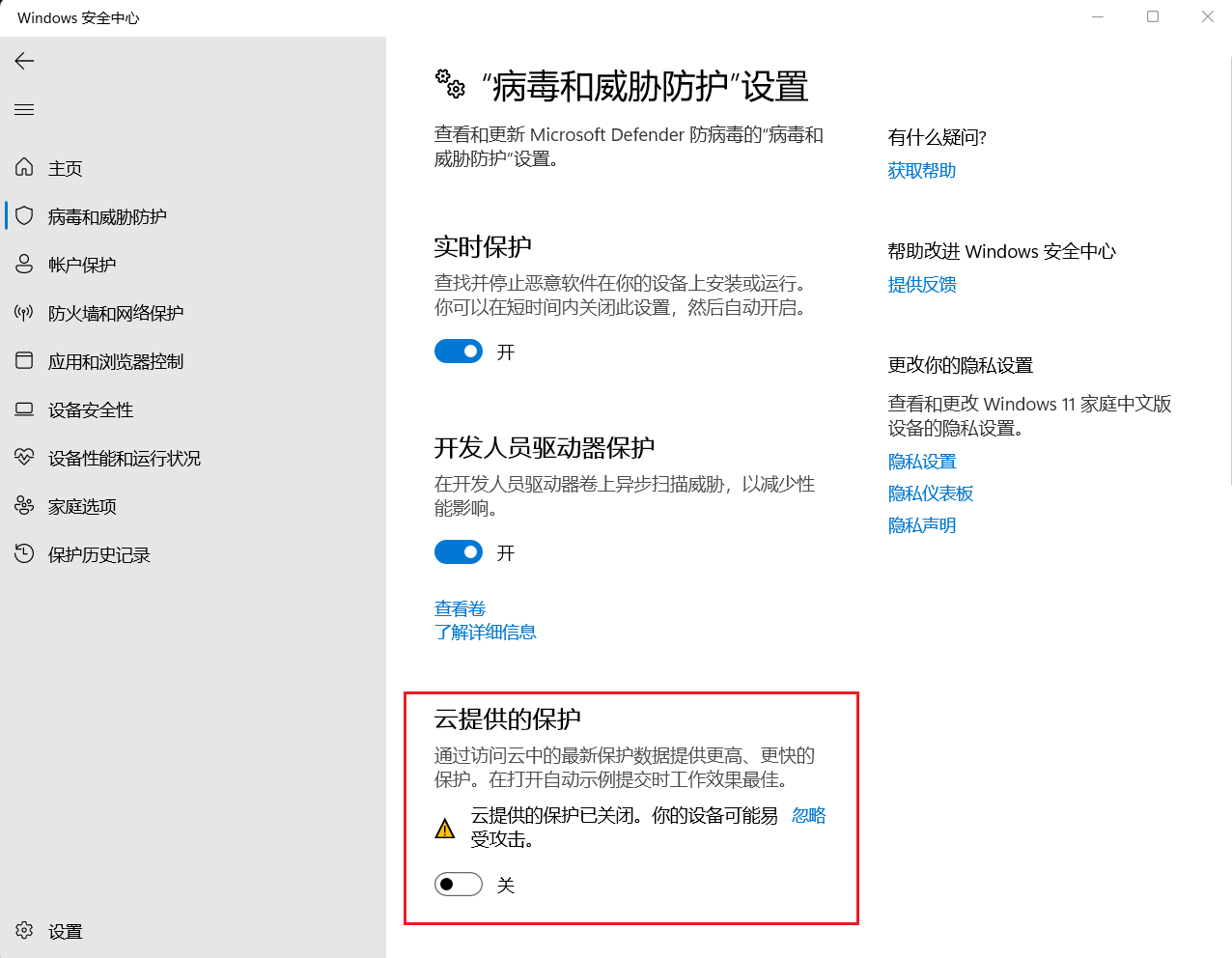
# 解决方法
通过设置 > 隐私和安全性 > Windows 安全中心 > 病毒和威胁防护 > 管理设置进入“病毒和威胁防护”设置页面,取消勾选“云提供的保护”选项,重启 julia 命令行窗口,加载函数库成功。
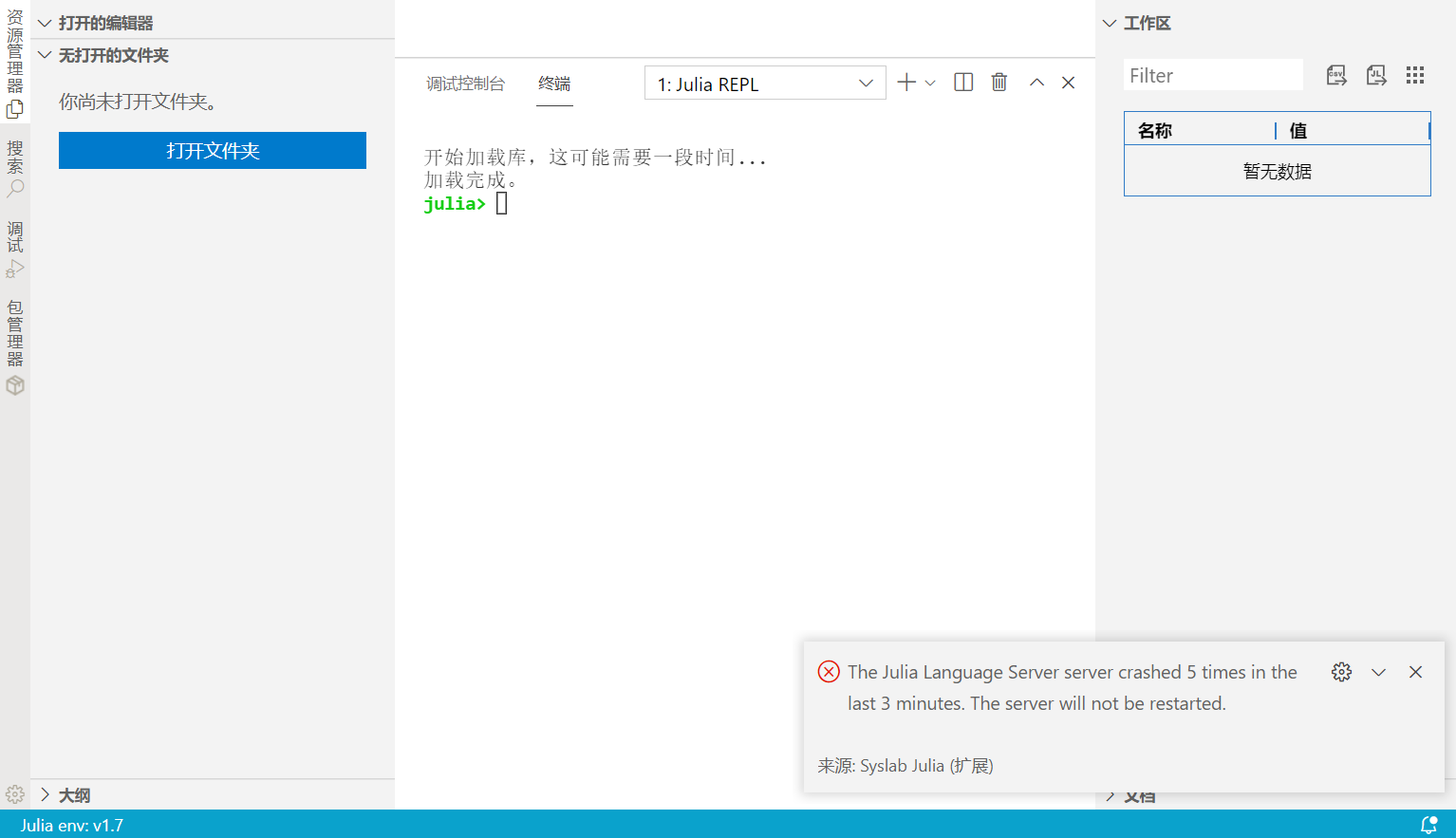
# Julia 语言服务加载崩溃
# 问题描述
出现如下图的语言服务崩溃,且重启多次 Syslab 都是如此。
# 问题原因
语言服务加载失败。
# 解决方法
Windows 系统: 删除
C:/Users/Public/TongYuan/.tycache目录下的“lsdepot”、“symbolstorev5”文件夹,然后重新启动 Syslab,等待语言服务加载完成;CentOS 系统: 删除
HOME/TongYuan/.tycache目录下的“lsdepot”、“symbolstorev5”文件夹,然后重新启动 Syslab,等待语言服务加载完成。
注意
重新生成语言服务缓存时间较长,请耐心等待。
# Syslab 的终端窗口如何在想要的插入点替换掉部分终端里的字符串
# 问题描述
在终端窗口的插入点进行复制粘贴,不管光标在哪里,都会直接复制到最后,也无法选中一部分字符进行替换或者删除。
# 解决方法(一)
直接按键盘上的左右键,将光标移动到需要进行操作的字符段处,按 Ctrl + C 、 Ctrl + V、Backspace 键进行复制、粘贴、删除操作。
# 解决方法(二)
光标定位至终端后,按住 Alt 键,鼠标箭头样式转变为“+”;

按住 Alt 键,将鼠标“+”移动到需要操作的字符段处并单击,光标成功移动到需要替换的字符段末尾;
将需要替换掉的字符串删除,再复制粘贴需要加入的字符串,即完成了替换。
# Ctrl+C 无法停止正在运行的程序
# 问题描述
Ctrl+C 在很多情况下无法停止正在运行的程序。如下图所示,在死循环程序下无法立即中断。
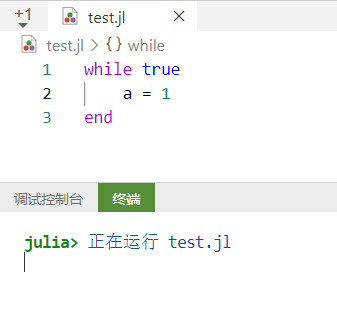
# 解决方法
脚本运行模式下,如果 Julia 正在运行 IO 密集型任务,Ctrl+C 能够立即起作用。如果 Julia 正在运行 CPU 密集型任务,Ctrl+C 可能不会立即起作用。在这种情况下,可能需要等待 Julia 完成当前操作,然后才能处理中断信号;
若已处于死循环中,Ctrl+C 未立即起作用情况下,可通过关闭终端停止;
建议手动给循环添加 Julia 运行时调度点,让循环重新被 Julia 运行时管理,给检测中断信号的机会,推荐添加 yield()。yield() 是 Julia 的主动调度函数,作用是强制让 Julia 运行时接管一次执行流,检测中断信号、GC 请求等。
while true a = 1 yield() # 关键:手动添加调度点,让运行时检测中断 end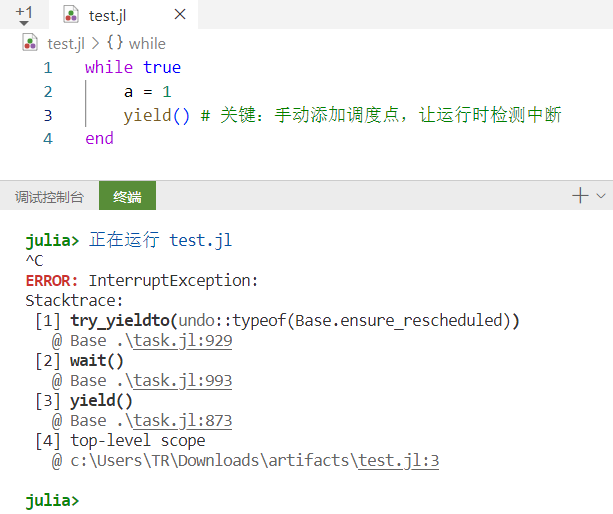
# 编辑代码时什么时候使用分号,什么时候不使用分号
# 问题描述
编辑代码时什么时候使用分号? 什么时候不使用分号?
# 解决方法
在代码语句后加上分号后运行,命令行窗口不会输出代码执行后的结果;
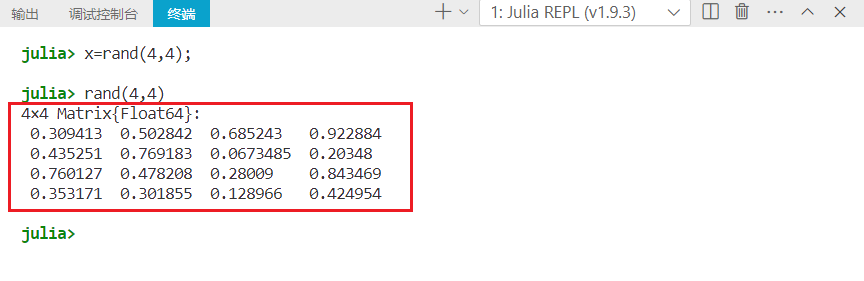
不在代码语句后加上分号并运行,命令行窗口会输出代码的执行结果。
# 如何快速修改因路径斜杠方向导致的运行报错
# 问题描述
Windows 系统上的文件资源管理器都是用反斜杠“\”作为路径分隔符,但CSV.read函数输入参数路径要求为正斜杠,若直接复制 Windows 文件资源管理器的路径运行会报错。
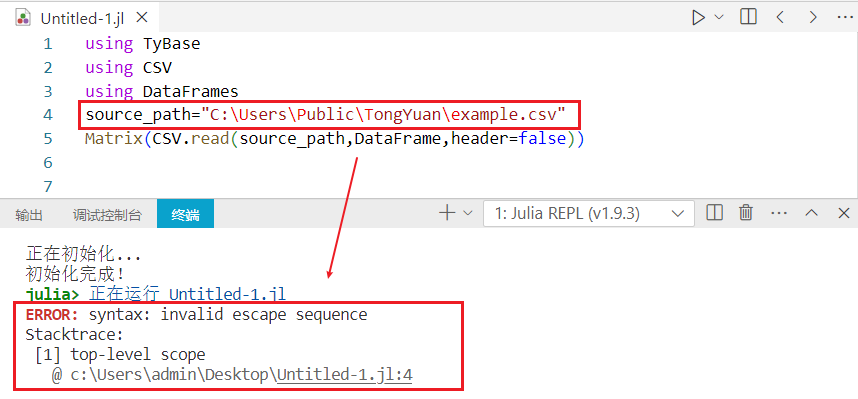
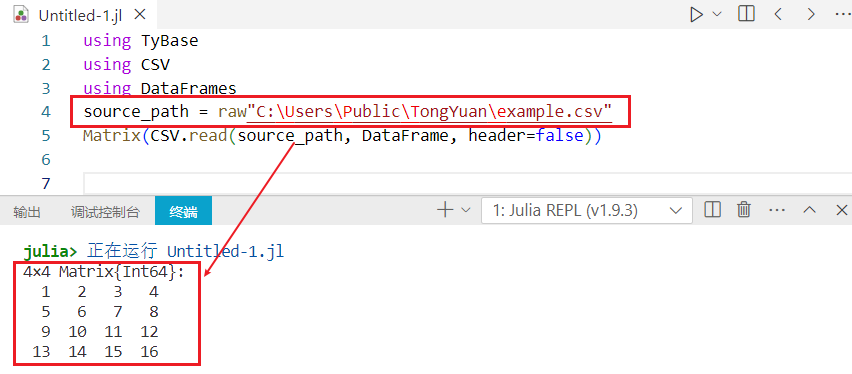
# 解决方法
在路径前加“raw”,即可使CSV.read函数可以正常读取 Windows 文件资源管理器的文件路径。
# 函数未定义报错
# 问题描述
x = [-3,-2,-1,0,1,2,3]
v = @. 3*x^2
xq = [-4,-2.5,-0.5,0.5,2.5,4]
vq = interp1(x,v,xq,"pchip",27)
运行上述代码,出现报错,报错信息为函数未定义 “ERROR: UndefVarError: interp1 not defined”,如下图所示。
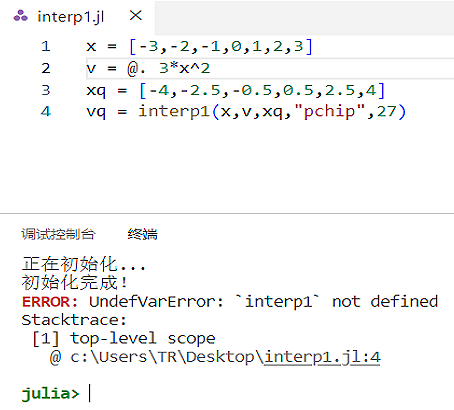
# 问题原因
若错误为 “UndefVarError: xxx not defined”,可能有以下两种原因:
未加载相应函数库。
排除未加载函数库的问题后,若使用的函数同时属于多个函数库且导入了其中不止一个函数库,此时直接使用该函数也会导致 “UndefVarError:
xxxnot defined” 的错误。
以上两种原因分别对应下面两种解决方法。
# 解决方法
针对问题原因 1,先打开帮助文档,查找该函数的所属函数库,并在代码中加载该函数库。
根据报错信息“ERROR: UndefVarError:
interp1not defined”,打开 Syslab 帮助文档。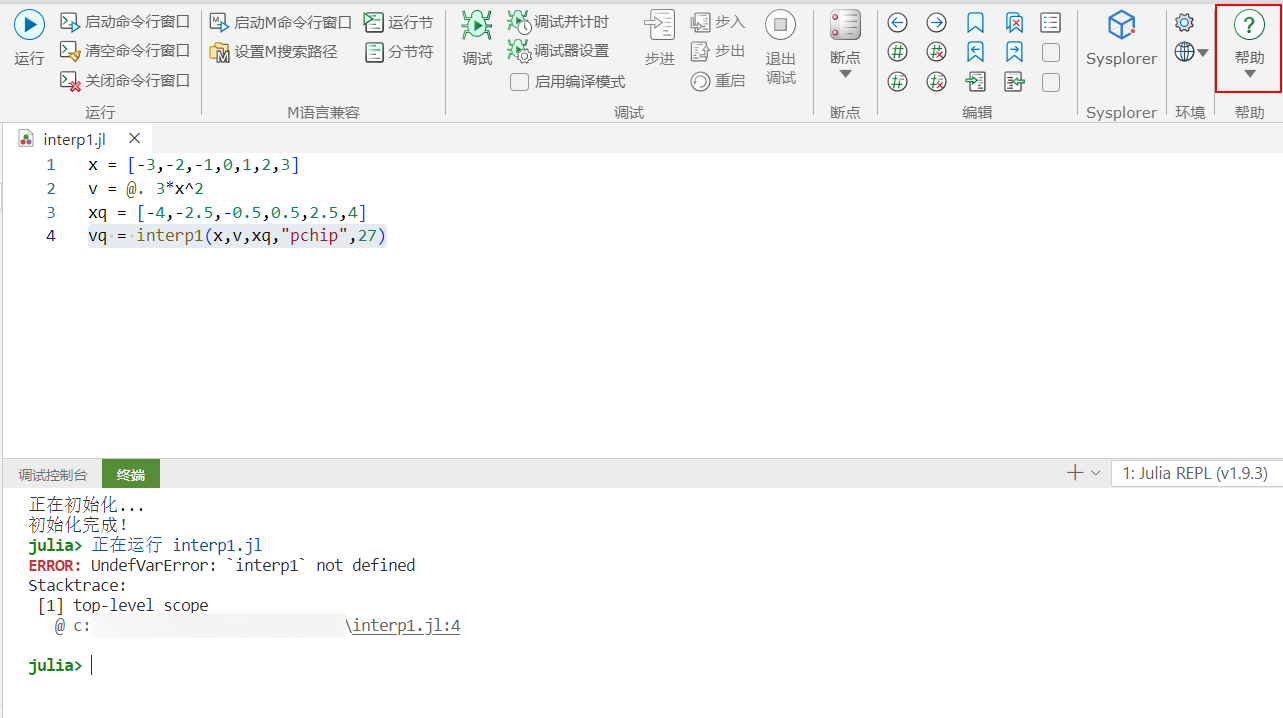
在帮助文档中全局搜索函数
interp1。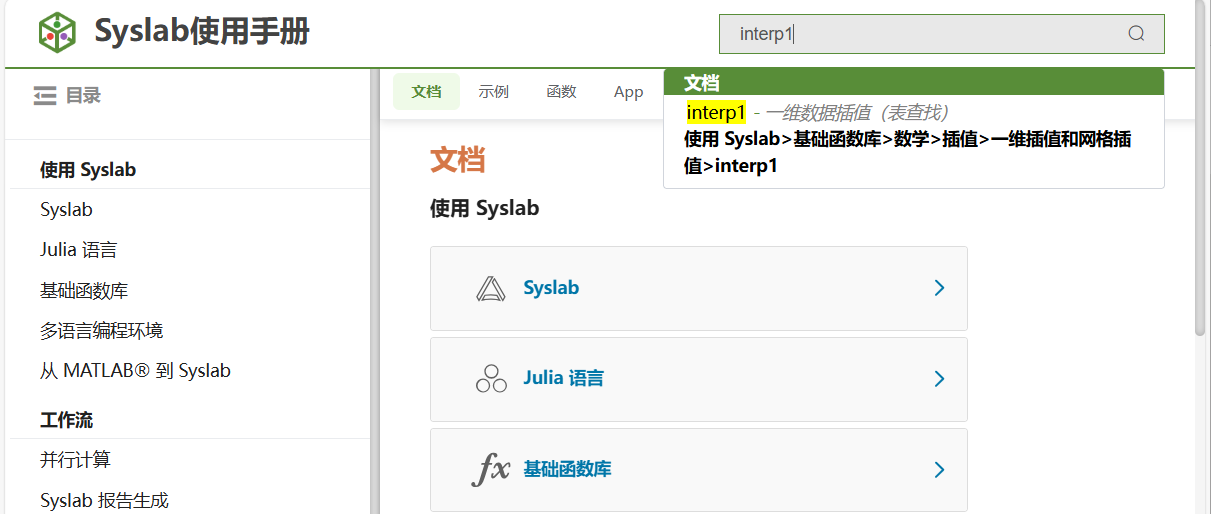
根据帮助文档搜索结果,找到函数所属的函数库
TyMath。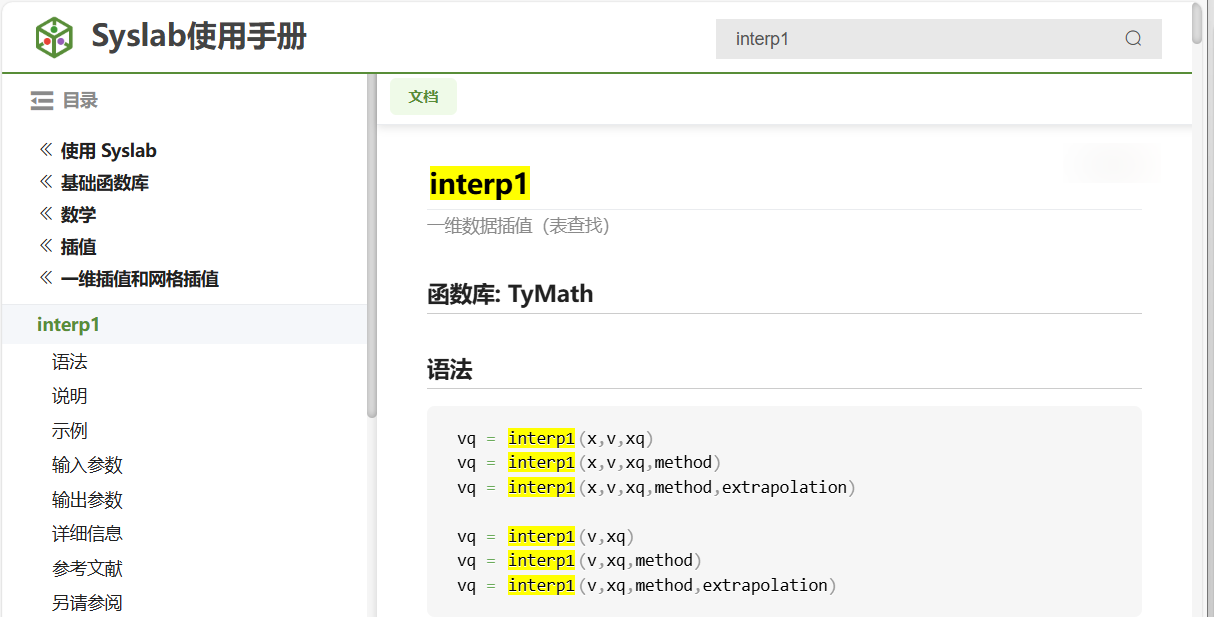
在 julia 文件中输入
using TyMath,再次运行示例,正常运行。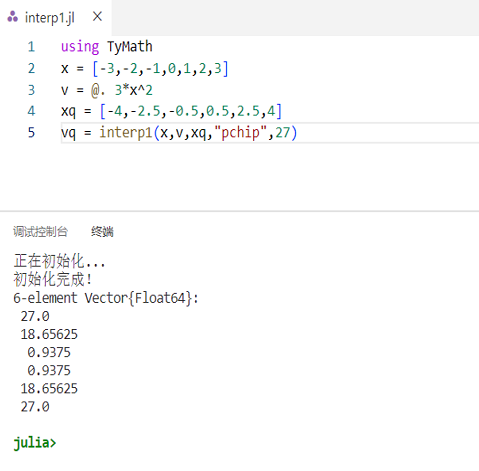
针对问题原因 2,如出现导入多个函数库包含相同名称函数的情况,请使用函数库.xxx 的形式避免函数未定义报错。
出现报错信息“ERROR: UndefVarError:
resamplenot defined”。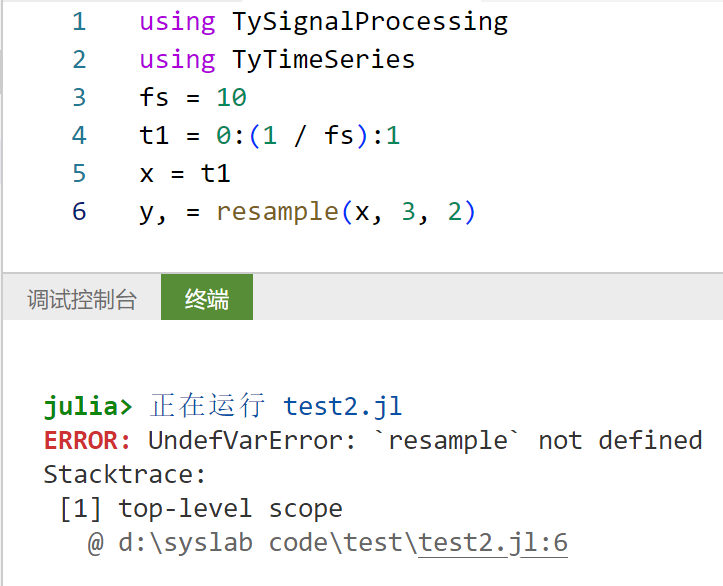
排除未引入函数库的问题后,选择要使用的函数库,以函数库.xxx 的形式对函数进行使用,再次运行示例,正常运行。
# 如何加快调试运行速度
# 问题描述
Julia 在调试大规模代码时,会花费较长的时间。例如以下示例,高亮的这行代码单步调试耗时 10 秒以上。
using JSON
dict = Dict()
for i in 1:30000
name = string("var", i)
dict[name] = i
end
json_str = JSON.json(dict)
len = length(json_str)
new_dict = JSON.parse(json_str) # 这行代码单步调试耗时超过10秒
res_type = typeof(new_dict)
# 问题原因
Julia 是一种即时编译型语言,在调试时需要额外的解析和分析步骤,以及需要动态类型推断等过程,所以调试运行的速度比直接运行慢,耗时较长。
Julia 调试器有两种调试模式,解释模式和编译模式,默认是解释模式。想要解决调试慢的问题,可以把不需要调试的模块设置为编译模式。请注意:设置为编译模式的模块也就意味着不能再进入调试。
# 解决方法
通过分析,以上示例是因为当 JSON 字符串很大时,JSON.parse()函数在解释模式下特别耗时,通过将 JSON 函数库配置成编译模式,可以解决以上示例调试慢的问题。下面讲述具体的修改方法。
打开 Syslab 后,单击首选项,然后下拉找到调试器性能选项,单击编辑,可以打开
setting.json配置文件进行配置。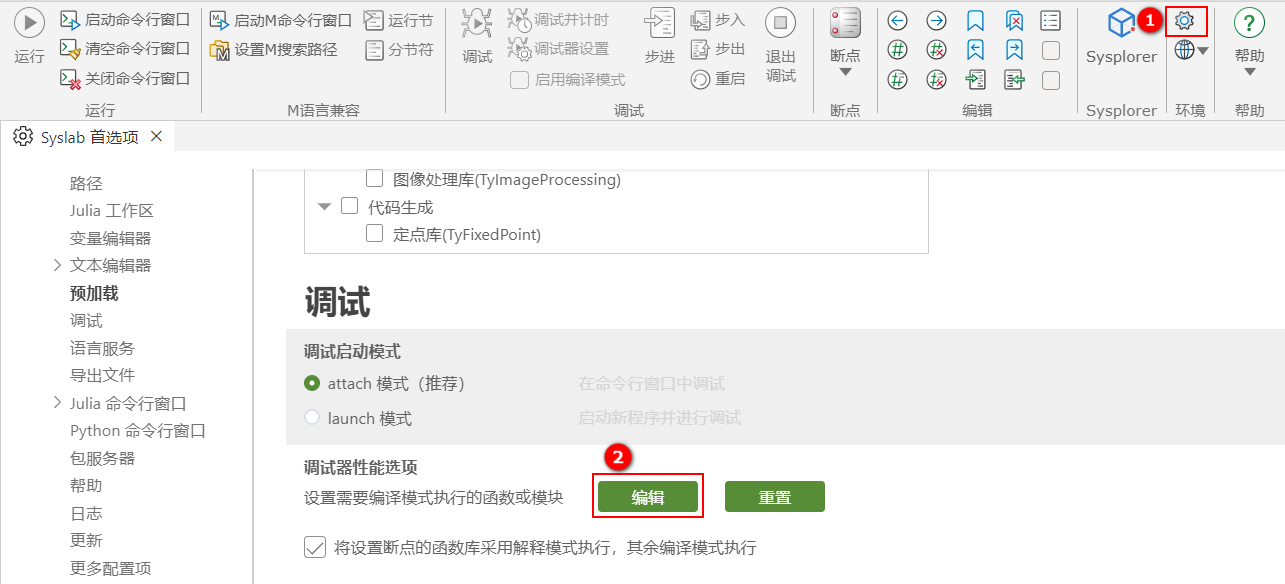
打开
settings.json配置文件后,在该列表中增加一行"JSON.",,效果如下图所示。详细信息,请参见 Julia 调试配置规则。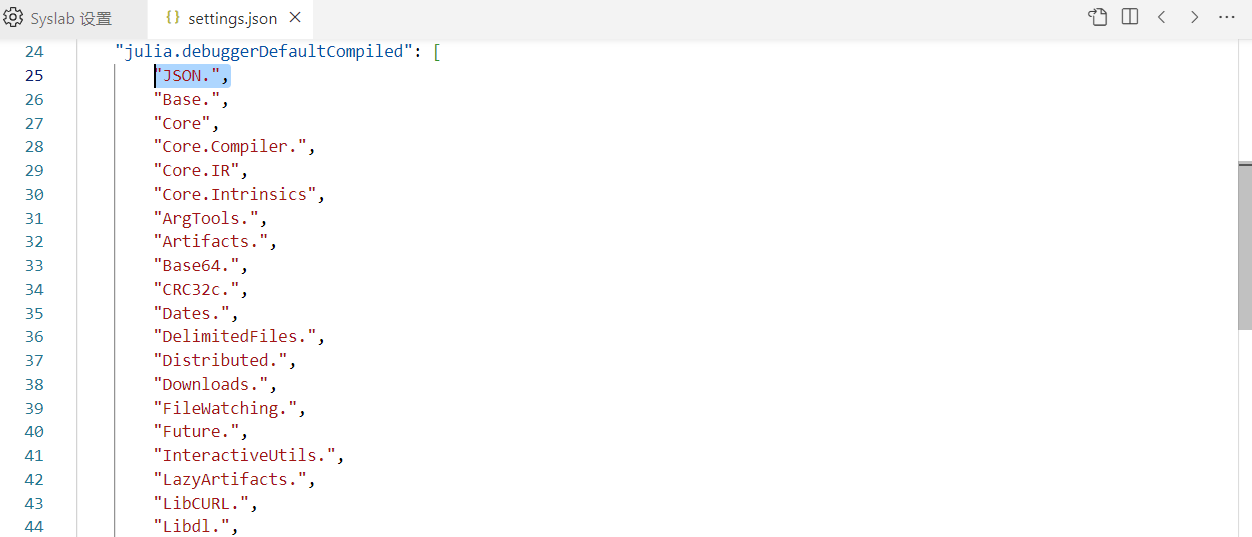
配置修改后,保存文件,然后立即生效。
再次调试该示例代码,原来调试慢的代码行耗时降低为 1 秒以内。
# Julia 调试配置规则
在配置文件的julia.debuggerDefaultCompiled列表中,将 Julia 模块和函数配置成编译模式或者解释模式。具体规则如下:
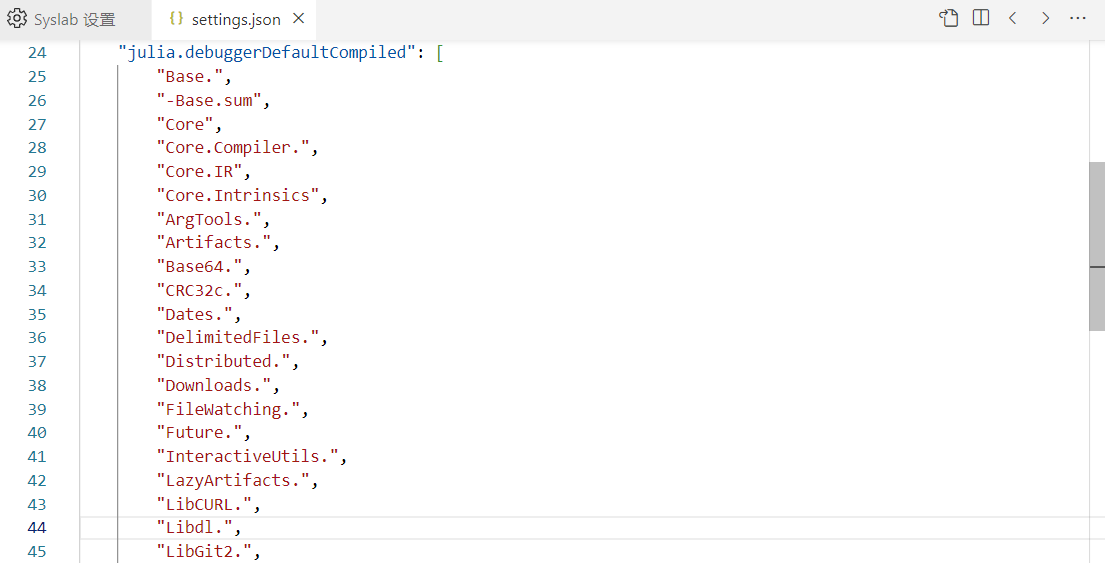
以 "
-" 开头的模块或函数,为解释模式;例如同时配置了“Base”和“-Base.sum”,代表 Base 模块为编译模式,但是
Base.sum函数为解释模式,这样就能调试Base.sum函数,但是 Base 模块中其他函数不能调试。没有以"
-"开头的模块或函数,为编译模式;例如“Base”,代表 Base 模块中所有函数为编译模式,但是子模块还是解释模式;
例如“Base.sum”,代表 Base 模块中
sum函数为编译模式。
以 "
." 结尾的模块,代表该模块及其所有的子模块都为编译模式。例如“Base.”,代表 Base 模块及其所有的子模块中所有函数为编译模式。
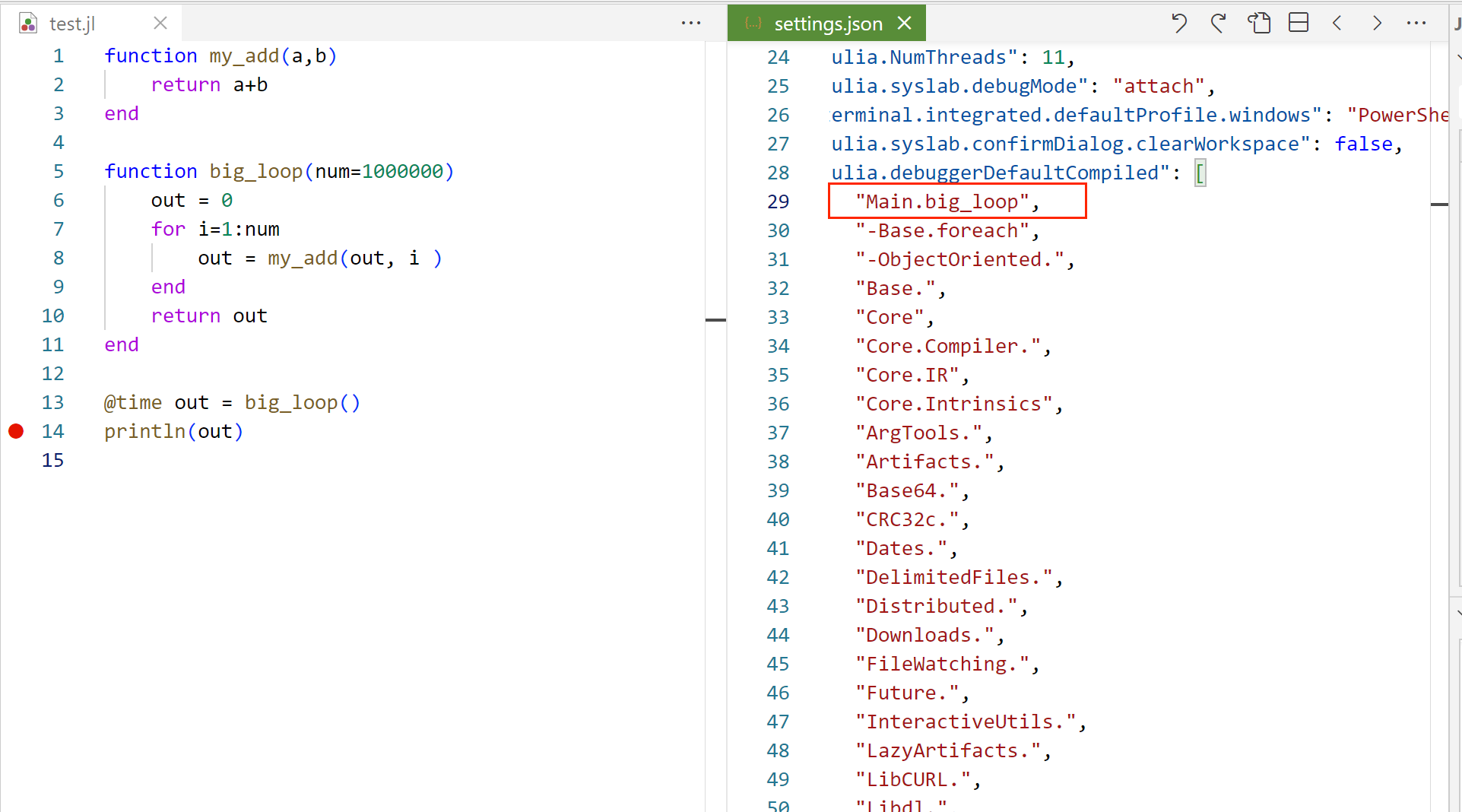
用户在脚本中设计的函数默认在 Main 模块下运行,如下图所示,若想将 big_loop 函数设置为编译模式,则需要在列表中添加 Main.big_loop。
# 机器限制 CPU 占用导致 Julia 进程被杀死
# 问题描述
Julia 为了实现高性能计算,通常会依赖一些底层的数值计算库,其中最常用的是 BLAS(Basic Linear Algebra Subprograms)。 在 Julia 中,BLAS 的实现默认会使用多线程来提高计算性能,旨在通过并行处理来增强计算性能,从而在处理大规模数据和复杂运算时展现出卓越的能力。
然而,值得注意的是,尽管多线程技术能够大幅提升计算速度,但在某些机器上,由于系统配置了严格的 CPU 占用限制策略,这可能会引发潜在的问题。当 Julia 借助 BLAS 进行计算时,如果 CPU 使用超出了预设的阈值,系统出于资源管理的考虑,可能会终止 Julia 进程,导致计算任务意外中断。
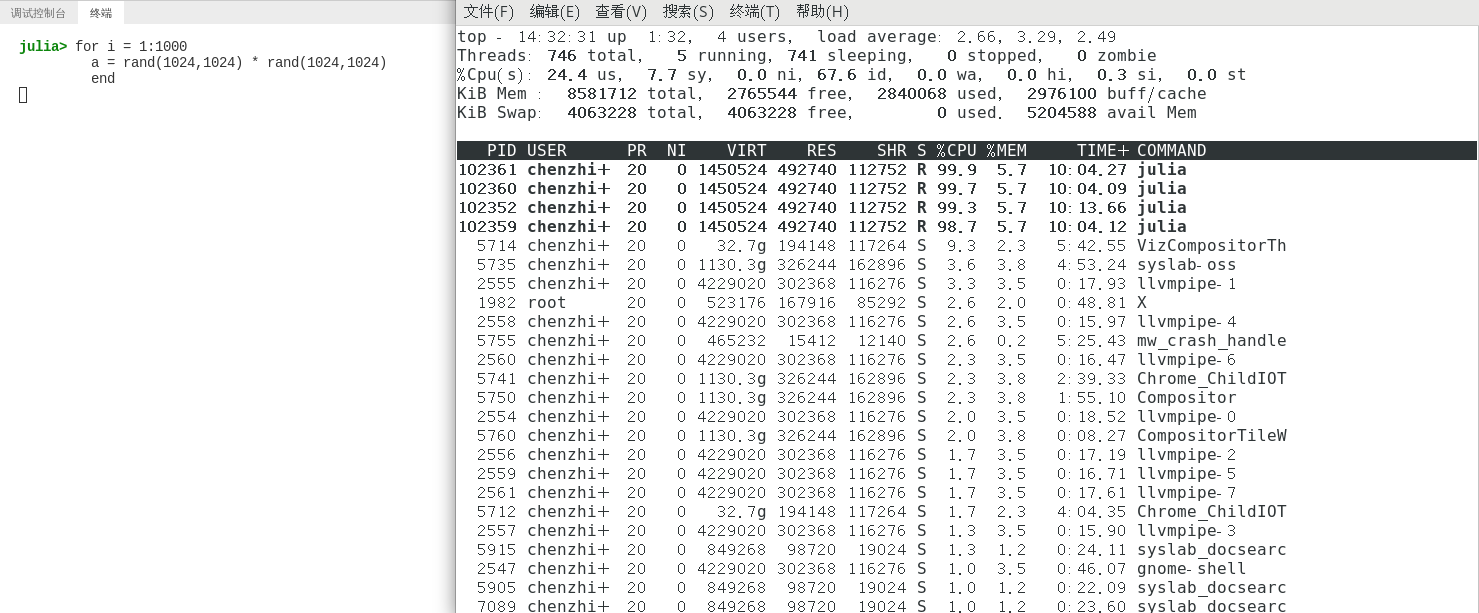
以 8 核机器(8 核的机子 CPU 占用率总上限是 800%)为例,运行如下代码:
for i = 1:10000
a = rand(1024,1024) * rand(1024,1024)
end
使用 top -H 命令查看,可以看出,CPU 占用达到了 400%。
# 问题原因
由于某些机器上系统配置了严格的 CPU 占用限制策略,当 Julia 借助 BLAS 进行计算时,如果 CPU 使用超出了预设的阈值,系统出于资源管理的考虑,会终止 Julia 进程,导致计算任务意外中断。
# 解决方法
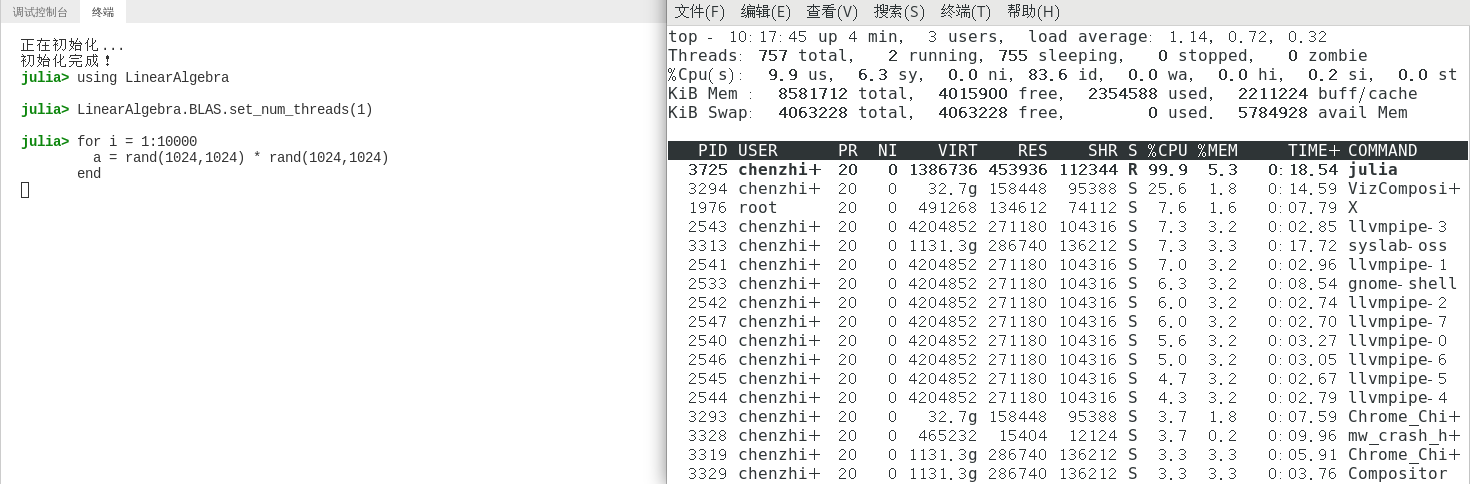
通过设置 LinearAlgebra.BLAS.set_num_threads(1) ,将 BLAS 设置成单线程。
using LinearAlgebra
LinearAlgebra.BLAS.set_num_threads(1)
for i = 1:10000
a = rand(1024,1024) * rand(1024,1024)
end
使用 top -H 命令查看,可以看出,CPU 只占用了 100%。
# 运行 Julia 示例内存溢出
# 问题描述
在运行 Julia 示例时,有时会出现内存占用过高的问题。
例如,以下面这段代码为例:
forecast_samples_adj = [randn(300) for i in 1:10_000]';
function f(arr)
reduce(vcat, arr)
@show Base.gc_live_bytes() / 2^20
return Base.gc_live_bytes() / 2^20
end
[f(forecast_samples_adj) for i in 1:100]
该示例运行后内存占用在 4.9G 左右。

# 解决方法
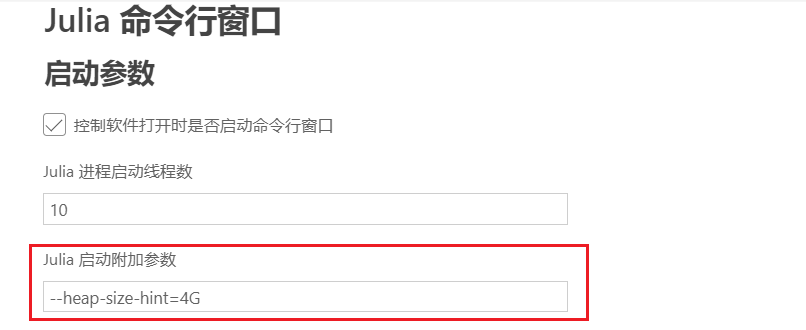
在 Syslab 首选项的 Julia 命令行窗口使用以下命令启动 Julia。打开 Syslab 后,单击首选项,然后下拉找到 Julia 命令行窗口,设置 --heap-size-hint=4G 选项(注,具体设置多大合适,用户自行决定),该选项能为 Julia 的内存使用提供一个建议性的上限,从而更好地控制资源使用。
然后重新运行示例,在运行过程中可以看到当 Julia 内存使用量超过 4G 时,会触发全量 GC 操作。示例运行完成后,内存占用在 800M 左右。
