# zscore
标准化 z 分数
函数库: TyStatistics
# 语法
Z,mu,sigma = zscore(X,flag,dim)
Z,mu,sigma = zscore(X,flag,vecdim)
# 说明
Z,mu,sigma = zscore(X) 返回 X 的每个元素的 z 分数,使得 X 的列居中以具有均值 0 并按比例缩放以具有标准差 1。Z 与 X 的大小相同。示例
如果 X 是向量,则 Z 是 z 分数的向量。
如果 X 是一个矩阵,那么 Z 是一个与 X 大小相同的矩阵,Z 的每一列均值为 0,标准差为 1。
对于多维数组,Z 中的 z 分数是沿 X 的第一个非单一维度计算的。
Z,mu,sigma = zscore(X,flag) 使用标志指示的标准差对 X 进行缩放。
如果 flag 为 0(默认值),则 zscore 使用样本标准差对 X 进行缩放,标准差公式的分母为 n - 1。 zscore(X,0) 与 zscore(X) 相同。
如果 flag 为 1,则 zscore 使用总体标准差对 X 进行缩放,n 在标准差公式的分母中。
Z,mu,sigma = zscore(X,flag,dim) 沿操作维度 dim 对 X 进行标准化。例如,对于矩阵 X,如果 dim = 1,则 zscore 使用沿 X 列的均值和标准差,如果 dim = 2,则 zscore 使用沿 X 行的均值和标准差。
Z,mu,sigma = zscore(X,flag,vecdim) 在向量 vecdim 指定的维度上对 X 进行标准化。示例
# 示例
两个数据向量的 Z 分数
加载示例数据。 两个变量加载到工作区中:gpa 和 lsat。
using TyPlot
using TyStatistics
pkg_dir = pkgdir(TyStatistics)
source_path = pkg_dir * "/examples/Descriptive Statistics and Visualization/Range,Deviation,andz-Score/zscore_tests/zscore_data_1.jl"
include(source_path)
在同一轴上绘制两个变量。
plot([gpa lsat])
legend(["gpa","lsat"],loc="east")
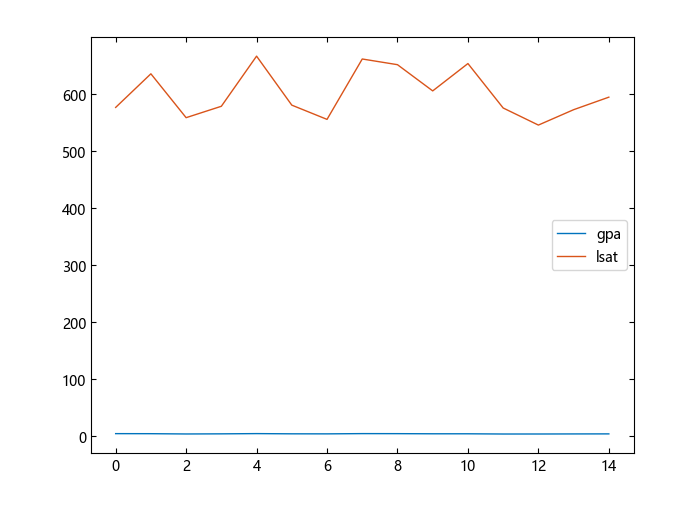
很难比较这两项措施,因为它们的规模非常不同。
在同一轴上绘制 gpa 和 lsat 的 z 分数。
Zgpa = zscore(gpa)[1];
Zlsat = zscore(lsat)[1];
plot([Zgpa Zlsat])
legend(["gpa z-scores","lsat z-scores"],loc="northeast")
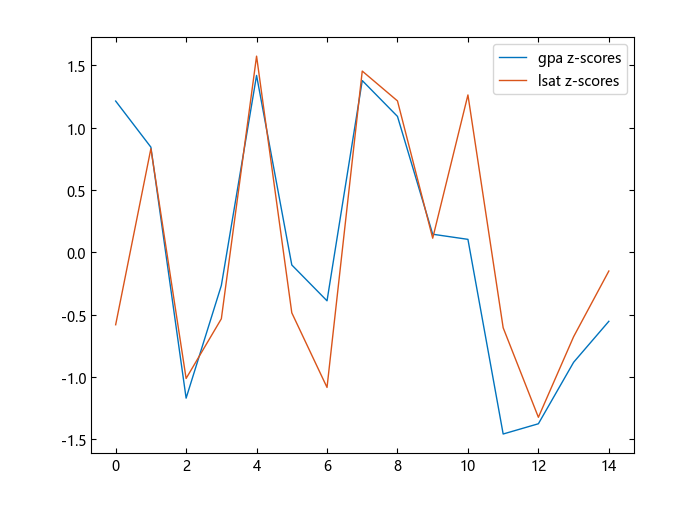
现在,您可以看到个人在 gpa 和 lsat 结果方面的相对表现。 例如,第三个人的 gpa 和 lsat 结果都比样本均值低一个标准差。 第十一个人的 gpa 在样本平均值附近,但 lsat 分数比样本平均值高出近 1.25 个标准差。
检查您创建的 z 分数的均值和标准差。
mean([Zgpa Zlsat],1)
1×2 Matrix{Float64}:
-1.08802e-15 3.57122e-16
std([Zgpa Zlsat],dims=1)
1×2 Matrix{Float64}:
1.0 1.0
人口与样本的 Z 分数
using TyStatistics
pkg_dir = pkgdir(TyStatistics)
source_path = pkg_dir * "/examples/Descriptive Statistics and Visualization/Range,Deviation,andz-Score/zscore_tests/zscore_data_1.jl"
include(source_path)
两个变量加载到工作区中:gpa 和 lsat。
使用标准偏差的总体公式计算 gpa 的 z 分数。
Z,gpamean,gpastdev = zscore(gpa)
Z = 15-element Vector{Float64}:
1.2128081187324247
0.8432164798410523
-1.1690046652341892
-0.26555843683306096
1.418136807005408
-0.10129548621467369
-0.38875564979685057
1.377071069350812
1.0896109057686334
0.14509893971290727
0.10403320205831135
-1.4564648288163662
-1.3743333535071742
-0.8815445016520125
-0.5530186004152379
gpamean = 3.094666666666667
gpastdev = 0.24351200224649142
# 输入参数
X - 输入数据
向量 | 矩阵 | 多维数组
数据类型: Float32 | Float64 | Int8 | Int16 | Int32 | Int64 | Int128 | UInt8 | UInt16 | UInt32 | UInt64 | UInt128
flag - 标准偏差的指标
0(默认) | 1
dim - 维度
正整数标量
例如,对于矩阵 X,如果 dim = 1,则 zscore 使用 X 列的均值和标准差,如果 dim = 2,则 zscore 使用 X 的行的均值和标准差。
dim - 维度向量
正整数向量
例如,如果 X 是一个 2×3×3 数组,则 zscore(X,0,[1 2]) 使用 X 各页的均值和标准差来标准化 X 的值。
数据类型: Float32 | Float64 | Int8 | Int16 | Int32 | Int64 | Int128 | UInt8 | UInt16 | UInt32 | UInt64 | UInt128
# 输出参数
Z — z 分数
向量 | 矩阵 | 多维数组
Z 的值取决于您指定的是 dim 还是 vecdim。 如果您未指定任何这些输入参数,则适用以下条件:
如果 X 是向量或者矩阵,则 Z 是均值为 0 方差为 1 的 z 分数向量。
如果 X 是数组,则 zscore 沿 X 的第一个非单一维度进行标准化。
mu - 均值
标量 | 向量 | 矩阵 | 多维数组
例如,如果 X 是一个 2×3×3 数组并且 vecdim 是 [1 2],则 mu 是一个 1×1×3 均值数组。 mu 中的每个值对应于 X 中一页的平均值。
sigma - 标准偏差
标量 | 向量 | 矩阵 | 多维数组
例如,如果 X 是 2×3×3 数组并且 vecdim 是 [1 2],则 sigma 是标准差的 1×1×3 数组。 sigma 中的每个值对应于 X 中页面的标准偏差。
# 详细信息
Z分数
对于具有均值的样本数据
z 分数根据标准差衡量数据点与平均值的距离。 这也称为数据标准化。 标准化数据集的均值为 0,标准差为 1,并保留了原始数据集的形状属性(相同的偏度和峰度)。
多维数组
第一非单一维度
样本标准差
S 是从中抽取 X 的总体方差的无偏估计量的平方根,只要 X 由独立的、同分布的样本组成。
请注意,此方差公式中的分母为 n – 1。
总体标准差
如果 X 是总体中的随机样本,则均值 μ 由样本均值估计,σ 是总体标准差的有偏最大似然估计量。
请注意,此方差公式中的分母为 n。