# anova1
单向方差分析
函数库: TyStatistics
# 语法
# 说明
p,tbl,stats = anova1(y) 对样本值 y 进行单侧 ANOVA 并返回 p 值 p,ANOVA 矩阵 tbl 以及用于多重比较校验的结构体 stats。anova1 将 y 的每一列视为一个单独的组。该函数的测试原假设为 y 的列具有相同的总体均值,而备择假设为 y 的列的总体均值不同。多重比较检验使您能够决定哪一组的均值显著不同。为了进行这样的检验,请将 stats 结构体作为 multicompare 的输入参数。示例
p,tbl,stats = anova1(y,group) 对于以 group 分组的样本数据 y 进行单向 ANOVA。示例
# 示例
单项 ANOVA
创建列为常数与符合均值为 0 标准差为 1 的正态分布扰动的和的样本矩阵 y。
using TyStatistics
using TyBase
using TyMath
y, = meshgrid2(1:5)
rng = MT19937ar(5489) # 可复现
y = y + normrnd(rng,0,1,5,5)
y = 5×5 Matrix{Float64}:
1.53767 0.692312 1.65011 3.79503 5.6715
2.83389 1.56641 6.03492 3.87586 3.79251
-1.25885 2.34262 3.7254 5.4897 5.71724
1.86217 5.5784 2.93695 5.40903 6.63024
1.31877 4.76944 3.71474 5.41719 5.48889
进行单向 ANOVA。
p,tbl = anova1(y)
p = 0.0023320169746242074
tbl = 3×5 Matrix{Float64}:
53.7238 4.0 13.4309 6.04889 0.00233202
44.408 20.0 2.2204 Inf Inf
98.1318 24.0 Inf Inf Inf
ANOVA 矩阵展示了组间方差(第一行)与组内方差(第二行)。第一列为平方和(SS),第二列为自由度(df)。总自由度(第三行)为总观测次数减一,即 25-1=24。组间自由度为组的格式减一,即 5-1=4。组内自由度为总自由度减去组间自由度,即 24-4=20。
第三列为均方误差(MS),对每个变量为 SS/df。F 统计量(第四列)为均方误差之比(13.4309/2.2204)。p 值为测试统计量大于求得的测试统计量的概率,即 P(F>6.04)(第五列)。小的 p 值 0.0023 意味着组间差别很大。
使用单项 ANOVA 比较梁强度
输入样本数据。
using TyStatistics
strength = [82,86,79,83,84,85,86,87,74,82,78,75,76,77,79,79,77,78,82,79]
alloy = ["st","st","st","st","st","st","st","st","al1","al1","al1","al1","al1","al1","al2","al2","al2","al2","al2","al2"]
该数据来自于 Hogg(1987)对于结构梁强度的研究。向量 strength 表示在3000 磅力下以千分之一英寸为单位的梁的挠度。而 alloy 向量把每个梁标记为钢("st")、合金 1(”al1")与合金 2("al2")。虽然这里 alloy 是排好序的,但是分组变量不需要排好序。
原始假设为钢制梁与两个更贵的合金制作的梁强度上相同,返回 ANOVA 结果。
p, tbl = anova1(strength,alloy)
p = 0.0001526436388304918
tbl = 3×5 Matrix{Float64}:
184.8 2.0 92.4 15.4 0.000152644
102.0 17.0 6.0 Inf Inf
286.8 19.0 Inf Inf Inf
总自由度(第三行)为总观测次数减一,即 20-1=19。组间自由度为组的数目减一,即 3-1=2。组内自由度为总自由度减去组间自由度,即 19-2=17。
第三列为均方误差(MS),对每个变量为 SS/df。F 统计量(第四列)为均方误差之比。p 值为测试统计量大于求得的测试统计量的概率(第五列)。小的 p 值 0.000152644 表示我们应该采用备择假设。
您可以从 ANOVA 矩阵中得到其中的值。在新变量 Fstat 和 pvalue 中保存 F 统计量值以及 p 值。
Fstat = tbl[1,4]
Fstat = 15.40000000000001
pvalue = tbl[1,5]
pvalue = 0.0001526436388304918
单向 ANOVA 的多重比较
输入样本数据。
using TyStatistics
strength = [82,86,79,83,84,85,86,87,74,82,78,75,76,77,79,79,77,78,82,79]
alloy = ["st","st","st","st","st","st","st","st","al1","al1","al1","al1","al1","al1","al2","al2","al2","al2","al2","al2"]
该数据来自于 Hogg(1987)对于结构梁强度的研究。向量 strength 表示在3000 磅力下以千分之一英寸为单位的梁的挠度。而 alloy 向量把每个梁标记为钢("st")、合金 1(”al1")与合金 2("al2")。虽然这里 alloy 是排好序的,但是分组变量不需要排好序。
使用 anova1 进行单向 ANOVA。返回结构体 stats,其中包含了 multcompare 进行多重比较的全部数据。
p,_,stats=anova1(strength,alloy)
p = 0.0001526436388304918
stats = TyStatisticsCore.__Internal__.Anova1{Vector{Int64}, Vector{Float64}}(["st", "al1", "al2"], [8, 6, 6], "anova1", [84.0, 77.0, 79.0], 17, 2.4494897427831774)
小的 p 值 0.0001526436388304918 表明梁的强度并不相同。
# 输入参数
y - 样本数据向量 | 矩阵
样本数据,指定为向量或矩阵。
- 如果 y 是向量,您必须指定 group 为输入参数。每个 group 中的元素表示 y 中的对应元素的组名。anova1 函数将对应于 group 的相同值的 y 值视为同一组。在各组元素数目不同时使用该语法(非平衡 ANOVA)。
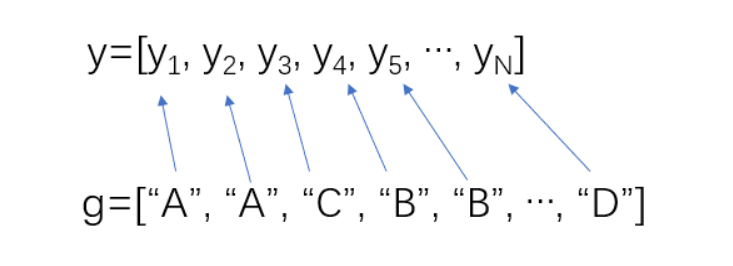
- 如果 y 是矩阵而且您不指定 group,则 anova1 把 y 的每一列视为不同组的元素。在这个用法中,函数计算的是每一列的总体均值是否相同。在每个组元素数目相同时使用该语法(平衡 ANOVA)。
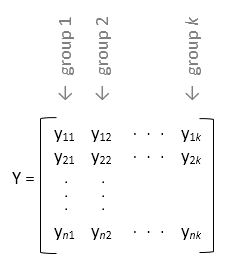
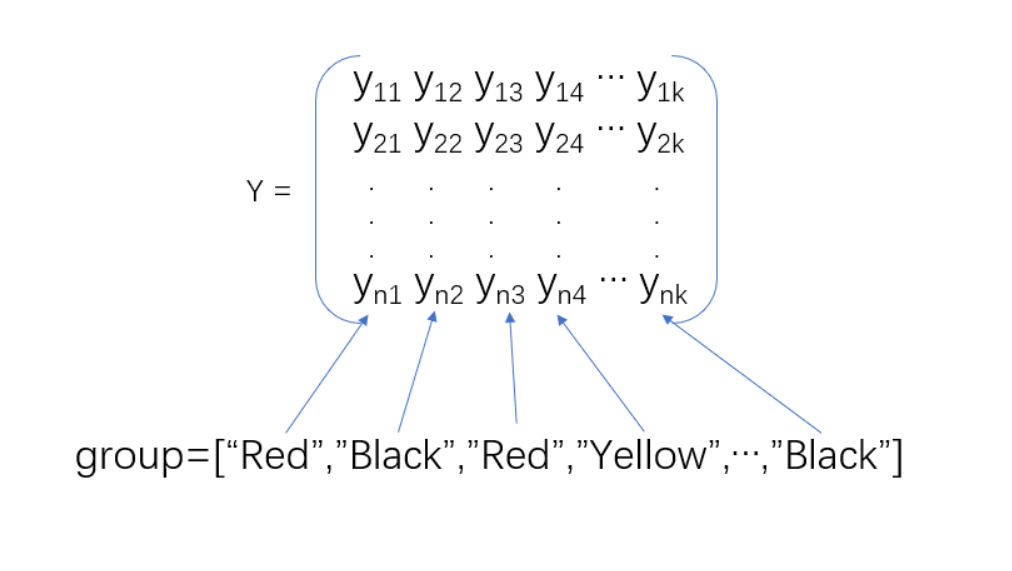
- 如果 y 是矩阵而且您指定了 group,则 group 中的每个元素表示 y 中对应列的组名。anova1 函数将具有相同组名的列视为同一组。
注意
anova1 会忽视 y 中的 NaN 值。如果 group 中包含空值或 NaN,anova1 也会忽视 y 中对应的观测。如果在函数排除 NaN 或 空值后每个组元素相同,anova1 会进行平衡 ANOVA,否则则会进行非平衡 ANOVA。
group - 分组变量数值向量 | 逻辑值向量 | 字符串向量
包含组名的分组变量,指定为数值向量、逻辑值向量或字符串向量。
- 如果 y 是向量,则每个 group 中的元素表示 y 中的对应元素的组名。anova1 函数将对应于 group 的相同值的 y 值视为同一组。
N 为总观测次数。
- 如果 y 是矩阵,则 group 中的每个元素表示 y 中对应列的组名。anova1 函数将具有相同组名的列视为同一组。
如果您为矩阵样本数据指定组名,则 anova1 将 y 的每列视为不同组。
如果 group 包含空或 NaN 值,anova1 会忽视 y 中的对应观测值。
示例:group=[1,2,1,3,1,...,3,1] 当 y 是分为 1,2,3 组的向量观测值。
示例:group=["white","red","white","black","red"] 当 y 是一个五列矩阵,且每一列分组为 red, white 和 black。
# 输出参数
p - F 检测 p 值标量值
F 检测 p 值,以标量形式返回。p 值为 F 统计量比计算测试统计量大的概率。anova1 原假设为所有组均值相同而备择假设为至少有一个组有不同的均值。该函数从 F 分布的累积分布函数中得到 p 值。
小于显著性水平的均值意味着至少有一个样本均值与其他不同。一般的显著性水平为 0.05 或 0.01。
tbl - ANOVA 矩阵矩阵
ANOVA 矩阵,以矩阵形式返回。tbl 有五列,三行。
| 列序号 | 定义 |
|---|---|
| 1 | SS,每个源的平方和。 |
| 2 | df,与源相关的自由度。假设 N 是观测总次数,k 为组数。则 N-k 为组内自由度(Error,误差),k-1 为组间自由度(Columns,列),而 N-1 为总自由度。N-1=(N-k)+(k-1)。 |
| 3 | MS,每个源的均方,这是 SS/df。 |
| 4 | F,F 统计量,这是均方的比。 |
| 5 | Prob>F,p 值,这是 F 统计量比计算测试统计量大的概率。anova1 原假设为所有组均值相同而备择假设为至少有一个组有不同的均值。该函数从 F 分布的累积分布函数中得到 p 值。 |
ANOVA 矩阵的行展示了数据由源区分的变量。
| 行序号 | 定义 |
|---|---|
| 1 | Groups,与组间均值差有关的变量(在组之间的变量)。 |
| 2 | Error,与组内与组内均值差有关的变量(在组内部的变量)。 |
| 3 | Total,总变量。 |
stats - 多重比较检验统计量结构体
多重比较检验统计量,以包含下表所示的域元的结构体形式返回。
| 域元 | 定义 |
|---|---|
| gnames | 组名 |
| n | 每个组的观测量 |
| source | stats 输出的来源 |
| means | 均值估计 |
| df | (组内)误差自由度(N-k,其中 N 为总观测次数,k 为组数) |
| s | 均方误差平方根 |
# 参考
[1] Hogg, R. V., and J. Ledolter. Engineering Statistics. New York: MacMillan, 1987.