# histcounts
直方图 bin 计数
函数库: TyPlot
# 语法
n,edges = histcounts(X;nargout = 2)
n,edges = histcounts(X,nbins;nargout = 2)
n,edges = histcounts(X,edges;nargout = 2)
n,edges,bin = histcounts(___;nargout = 3)
___ = histcounts(___;Key = Value)
# 说明
n,edges = histcounts(X;nargout = 2) 将 X 的值划分为多个 bin,并返回每个 bin 中的计数以及 bin 边界。histcounts 函数使用自动 bin 划分算法,返回均匀宽度的 bin,这些 bin 可涵盖 X 中的元素范围并显示基本分布的形状。示例
n,edges = histcounts(X,nbins;nargout = 2) 使用标量 nbins 指定的 bin 数量。示例
n,edges = histcounts(X,edges;nargout = 2) 将 X 划 分到由向量 edges 来指定 bin 边界的 bin 内。如果 edges[k] ≤ X[i] < edges[k+1],值 X[i] 位于第 k 个 bin 中。最后一个 bin 也包含 bin 的右边界,这样如果 edges[end-1] ≤ X[i] ≤ edges[end],它包含 X[i]。
n,edges,bin = histcounts(___;nargout = 3) 还使用以前的任何语法返回索引数组 bin。bin 是大小与 X 相同的数组,其元素是 X 中的对应元素的 bin 索引。第 k 个 bin 中的元素数量是 nnz(bin==k),与 N[k] 相同。示例
___ = histcounts(___;Key = Value) 使用一个或多个 Key=Value 对组指定的其他选项,这些选项使用上述语法中的任意输入或输出参数组合。例如,您可以指定 "binwidth" 和一个标量来调整数值数据的 bin 的宽度。示例
# 示例
bin 计数和 bin 边界
将 100 个随机值分布到多个 bin 内。histcounts 自动选择合适的 bin 宽度以显示数据的基本分布。
using TyPlot
X = randn(100,1) # 返回由正态分布的随机数组成的 m×n 矩阵
n, edges = histcounts(X; nargout=2)
n =
1×7 Matrix{Int64}:
3 13 38 31 11 3 1
edges =
8-element Vector{Float64}:
-3.0
-2.0
-1.0
0.0
1.0
2.0
3.0
4.0
指定 bin 数
将 10 个随机数分布到 6 个等间距 bin 内。
using TyPlot
X = [2 3 5 7 11 13 17 19 23 29];
n, edges = histcounts(X, 6; nargout=2)
n =
1×6 Matrix{Int64}:
2 2 2 2 1 1
edges =
7-element Vector{Float64}:
0.0
4.9
9.8
14.700000000000001
19.6
24.5
29.400000000000002
归一化的 bin 计数
将小于 100 的所有质数分布到多个 bin 内。将 "normalization" 指定为 "probability" 以对 bin 计数进行归一化,从而 sum(n) 为 1。即,每个 bin 计数代表观测值属于该 bin 的可能性。
using TyPlot
X=[2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97]
n, edges = histcounts(X; normalization="probability", nargout=2)
n =
1×4 Matrix{Float64}:
0.4 0.28 0.28 0.04
edges =
5-element Vector{Float64}:
0.0
30.0
60.0
90.0
120.0
确定 bin 放置
将介于 -5 和 5 之间的 100 个随机整数分布到多个 bin 内,并将 "binmethod" 指定为 "integers" 以使用以整数为中心的单位宽度 bin。指定 histcounts 的第三个输出以返回代表数据 bin 索引的向量。
using TyPlot
import PyCall: @pyimport
@pyimport numpy as np
X = []
for i in 1:100
push!(X, np.random.randint(-5,6))
end
n, edges, bin = histcounts(X; binmethod="integers", nargout=3)
通过计算数字 3 在 bin 索引向量 bin 中的出现次数求第三个 bin 的 bin 计数。结果与 n[3] 相同。
count = sum(bin .== 3)
count = 8
# 输入参数
X - 要分布到各 bin 的数据向量 | 矩阵 | 多维数组
要分布到各 bin 的数据,指定为向量、矩阵或多维数组。如果 X 不是向量,则 histcounts 将它视作单列向量 X[:]。
histcounts 忽略所有的 NaN 值。
数据类型: Int16 | Int32 | Int64 | Float16 | Float32 | Float64
nbins - bin 数量正整数
bin 数量,指定为正整数。如果不指定 nbins,则 histcounts 基于 X 中的值自动计算将使用多少个 bin。
示例: n,edges = histcounts(X,15; nargout=2) 使用 15 个 bin。
edges - bin 边界向量
bin 边界,指定为向量。edges[1] 是第一个 bin 的左边界,edges[end] 是最后一个 bin 的右边界。
数据类型: Int16 | Int32 | Int64 | Float16 | Float32 | Float64
# 名称-值对组参数
指定可选的、以逗号分隔的 Key=Value 对组参数。Key 为参数名称,Value 为对应的值。您可采用任意顺序指定多个名称-值对组参数,如 Key1=Value1,...,KeyN=ValueN 所示。
示例: n,edges = histcounts(X,normalization="probability"; nargout=2) 对 n 中的 bin 计数进行归一化,这样 sum(n) 为 1。
binlimits - bin 范围二元素向量
bin 范围,指定为二元素向量 [bmin,bmax]。该选项仅包括 X 中介于 bmin 和 bmax(含二者)之间的值,即 X(X>=bmin & X<=bmax)。
示例: n,edges = histcounts(X,binlimits=[1,10]; nargout=2) 仅包括 X 中介于 1 与 10(含二者)之间的值。
binmethod - bin 划分算法"auto" (默认) | "scott" | "integers" | "sturges" | "sqrt" | ...
bin 划分算法,指定为此表中的一个值。
| 值 | 说明 |
|---|---|
| "auto" | 默认的 "auto" 算法选择一个 bin 宽度,以便涵盖数据范围并显示基础分布形状。 |
| "scott" | 如果数据接近正态分布,则 scott 规则最佳。该规则也适用于大多数的其他分布。它使用 bin 宽度 3.5*std(X[:])*numel(X)^(-1/3)。 |
| "integers" | 整数规则对整数数据有用,因为它为每个整数创建一个 bin。它使用 bin 宽度 1 并将 bin 边界放在整数的中间。为避免无意间创建太多 bin,可以使用该规则创建 65536 (216) 个 bin 的限制。如果数据范围大于 65536,则整数规则改用更宽的 bin。 |
| "sturges" | Sturges 规则因其简单性而广受欢迎。它将 bin 数量选择为 ceil(1 + log2(numel(X)))。 |
| "sqrt" | 平方根规则是广泛用于其他软件包。它将 bin 数量选择为 ceil(sqrt(numel(X)))。 |
示例: n,edges = histcounts(X,binmethod="integers"; nargout=2) 使用以整数为中心的 bin。
binwidth - bin 的宽度标量
bin 宽度,指定为标量。指定 binwidth 时,hiscounts 最多可以使用 65,536 个 bin(即 2^16)。如果指定的 bin 宽度需要多个 bin,则 hiscounts 使用与最大 bin 数量对应的较大的 bin 宽度。
示例: n,edges = histcounts(X,binwidth=5; nargout=2) 使用宽度为 5 的 bin。
normalization - 归一化类型 "count" (默认) | "countdensity" | "cumcount" | "probability" | "pdf" | "cdf"
归一化类型,指定为此表中的一个值。对于每个 bin i:
- vi 是 bin 的值;
- ci 是 bin 中的元素数目;
- wi 是 bin 的宽度;
- n 是输入数据中的元素数目。此值可以大于分 bin 数据元素数,前提是数据中包含 NaN、NaT 或 undefined 值,或者某些数据位于 bin 范围外。
| 值 | bin 值 | 注释 |
|---|---|---|
| "count" (默认值) | 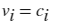 |
|
| "countdensity" | 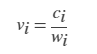 |
|
| "cumcount" | 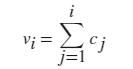 |
|
| "probability" | 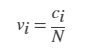 |
|
| "pdf" | 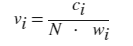 |
|
| "cdf" | 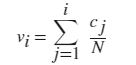 |
|
示例: n,edges = histcounts(X,normalization = "pdf"; nargout=2) 使用概率密度函数估计值对数据分 bin。
nargout - 控制输出参数Int
nargout 控制输出参数的个数。
# 输出参数
n - bin 计数数组
bin 计数,以行向量形式返回。
edges - bin 边界向量
bin 边界,以向量的形式返回。edges[1] 是第一个 bin 的左边界,edges[end)] 是最后一个 bin 的右边界。
bin - bin 索引数组
bin 索引,以大小与 X 相同的数组形式返回。bin 中的每个元素说明哪些编号的 bin 包含 X 中的对应元素。
# 版本历史记录
在 2023a 之前推出
2025b:返回值数量为一个时返回 bin 计数而不是 bin 边界
返回值数量为一个时,返回 bin 计数而不是 bin 边界。在以前的版本中,当只有一个返回值时,返回计算的 bin 边界。例如:
using TyPlot
X = [2 3 5 7 11 13 17 19 23 29];
edges = histcounts(X, 6)
7-element Vector{Float64}:
0.0
4.9
9.8
14.700000000000001
19.6
24.5
29.400000000000002
从 2025b 开始,返回值数量为一个时,返回计算的 bin 计数。例如:
using TyPlot
X = [2 3 5 7 11 13 17 19 23 29];
n = histcounts(X, 6)
1×6 Matrix{Int64}:
2 2 2 2 1 1