# matchFeatures
查找匹配的特征
函数库: TyImageProcessing
# 语法
indexPairs, = matchFeatures(features1,features2)
indexPairs,matchmetric = matchFeatures(features1,features2)
indexPairs,matchmetric = matchFeatures(features1,features2;Name=Value)
# 说明
indexPairs, = matchFeatures(features1,features2) 返回两个输入特征集中的匹配特征的索引。输入特征必须是 binaryFeatures 对象或矩阵。
indexPairs,matchmetric = matchFeatures(features1,features2) 还返回匹配特征之间的距离,按 indexPairs 索引。
indexPairs,matchmetric = matchFeatures(features1,features2;Name=Value) 通过一个或多个名称-值参数指定选项,除了之前语法中的任意参数组合。例如,matchFeatures(__;Method="Exhaustive") 将匹配方法设置为 Exhaustive。示例
# 示例
在一对图像之间找到对应的兴趣点
使用局部邻域和 Harris 算法查找一对图像之间的对应兴趣点。
读取立体图像。
using TyImageProcessing
using TyPlot
I1 = rgb2gray(imread("viprectification_deskLeft.png"))
I2 = rgb2gray(imread("viprectification_deskRight.png"))
找到角点。
points1 = detectHarrisFeatures(I1);
points2 = detectHarrisFeatures(I2);
提取邻域特征。
features1, valid_points1 = extractFeatures(I1, points1.Location)
features2, valid_points2 = extractFeatures(I2, points2.Location)
匹配特征。
indexPairs, = matchFeatures(features1, features2)
获取每个图像对应点的位置。
matchedPoints1 = valid_points1[indexPairs[:, 1], :]
matchedPoints2 = valid_points2[indexPairs[:, 2], :]
可视化对应点。尽管存在一些错误匹配,你可以看到两幅图像之间的位移效果。
figure();
showMatchedFeatures(I1, I2, matchedPoints1, matchedPoints2)

# 输入参数
features1 — 特征集 1binaryFeatures 对象 | M1×N 矩阵 | 点特征对象
特征集 1,指定为 binaryFeatures 对象、M1×N 矩阵,或作为点特征类型中描述的点特征对象之一。该矩阵包含 M1 个特征,N 对应于每个特征向量的长度。你可以使用 extractFeatures 函数与快速视网膜关键点 (FREAK)、方向 FAST 和旋转 BRIEF (ORB) 或二进制稳健不变可缩放关键点 (BRISK) 描述符方法获得 binaryFeatures 对象。
features2 — 特征集 2binaryFeatures 对象 | M2×N 矩阵 | 点特征对象
特征集 2,指定为 binaryFeatures 对象、M2×N 矩阵,或作为点特征类型中描述的点特征对象之一。该矩阵包含 M2 个特征,N 对应于每个特征向量的长度。你可以使用 extractFeatures 函数与快速视网膜关键点 (FREAK)、方向 FAST 和旋转 BRIEF (ORB) 或二进制稳健不变可缩放关键点 (BRISK) 描述符方法获得 binaryFeatures 对象。
# 名称-值参数
指定可选的参数对作为 Name1=Value1,...,NameN=ValueN,其中 Name 是参数名称,Value 是相应的值。名称-值参数必须出现在其他参数之后,但是对这些对的顺序不重要。
示例: Method="Exhaustive" 将匹配方法设置为穷举法。
Method — 匹配方法"Exhaustive" (默认) | "Approximate"
匹配方法,指定为 "Exhaustive" 或 "Approximate"。该方法指定了如何在 features1 和 features2 之间找到最近邻。两个特征向量匹配当它们之间的距离小于 MatchThreshold 参数设置的阈值时。
| 名称 | 值 |
|---|---|
| "Exhaustive" | 计算 features1 和 features2 中特征向量之间的成对距离。 |
| "Approximate" | 使用高效的近似最近邻搜索。对于较大的特征集,使用此方法。 |
MatchThreshold — 匹配阈值10.0 或 1.0 (默认) | 范围 (0, 100] 内的百分比值
匹配阈值,指定为范围在 (0, 100] 内的标量百分比值。默认值为二进制特征向量设置为 10.0,非二进制特征向量设置为 1.0。你可以使用匹配阈值来选择最强的匹配。该阈值表示与完美匹配之间距离的百分比。
当两个特征向量之间的距离小于 MatchThreshold 设置的阈值时,它们被视为匹配。当特征之间的距离大于 MatchThreshold 的值时,函数会拒绝该匹配。增大此值可以返回更多匹配。
通常,binaryFeatures 对象需要较大的匹配阈值。提取 FREAK、ORB 或 BRISK 描述符时,extractFeatures 函数会返回 binaryFeatures 对象。
MaxRatio — 比例阈值0.6 (默认) | 范围 (0,1] 内的比例值
比例阈值,指定为范围在 (0,1] 内的标量比例值。使用最大比例来拒绝模糊匹配。增大此值可以返回更多匹配。
Metric — 特征匹配指标"SSD" (默认) | "SAD"
特征匹配指标,指定为 "SAD" 或 "SSD"。
| 名称 | 值 |
|---|---|
| "SAD" | 绝对差之和 |
| "SSD" | 平方差之和 |
该属性适用于输入特征集 features1 和 features2 不是 binaryFeatures 对象的情况。当你将特征指定为 binaryFeatures 对象时,函数使用汉明距离(Hamming distance)来计算相似性指标。
Unique — 唯一匹配false (默认) | true
唯一匹配,指定为 false 或 true。将此值设置为 true 以仅返回 features1 和 features2 之间的唯一匹配。
当你将 Unique 设置为 false 时,函数返回 features1 和 features2 之间的所有匹配。features1 中的多个特征可以匹配到 features2 中的一个特征。
当你将 Unique 设置为 true 时,函数执行前向-后向匹配以选择唯一匹配。在将 features1 匹配到 features2 之后,它再将 features2 匹配到 features1,并保留最佳匹配。
# 输出参数
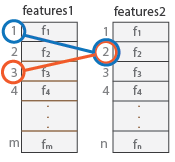
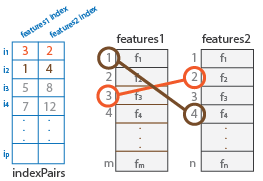
indexPairs — 对应特征的索引P×2 矩阵
输入特征集之间对应特征的索引,以 P×2 矩阵的形式返回 P 个索引对。每个索引对对应于 features1 和 features2 输入之间的匹配特征。第一个元素索引 features1 中的特征,第二个元素索引 features2 中的匹配特征。
matchmetric — 匹配特征之间的距离p×1 向量
匹配特征之间的距离以 p×1 向量的形式返回。距离的值基于所选择的度量。matchmetric 中的第 i 个元素对应于 indexPairs 输出矩阵中的第 i 行。当度量设置为 SAD 或 SSD 时,特征向量在计算之前会被归一化为单位向量。
| 度量 | 范围 | 完美匹配值 |
|---|---|---|
| SAD | [0, 2*sqrt(size(features1, 2))]. | 0 |
| SSD | [0,4] | 0 |
| Hamming | [0, features1.NumBits] | 0 |