# 同步语言元素
这一章节定义了适用于控制系统实现的同步行为。该同步行为依赖于另一种离散时间变量和方程,以及另一种 when 子句。同步行为的好处在于,它允许模型以安全的方式定义大型采样数据系统,以便在建模错误的情况下,翻译器能提供良好的诊断。
以下小例子展示了最重要的元素:一个连续工厂与一个采样数据控制器通过采样保持(零阶)元件相连接:
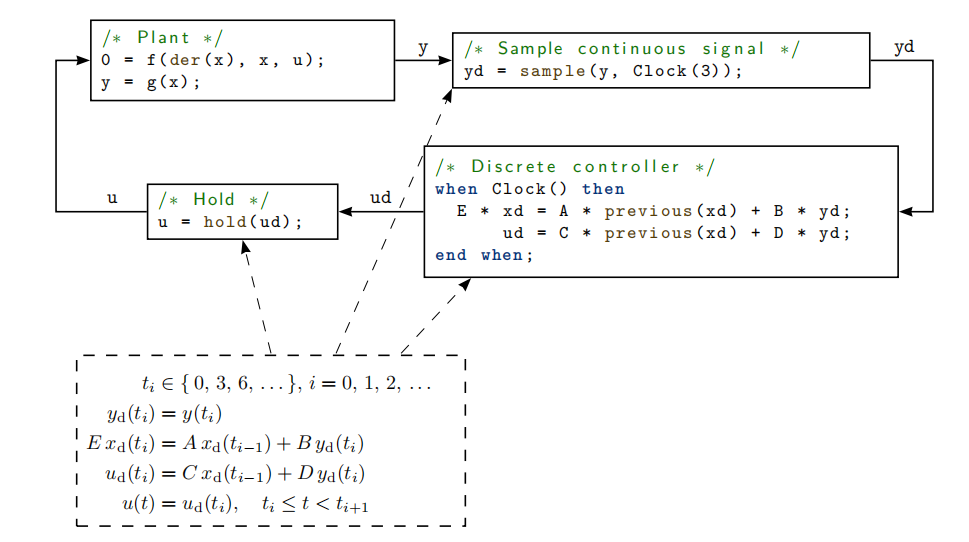
- 通过 Clock(3) 定义了一个周期时钟。Clock 的参数定义了采样间隔。
- 时钟变量(如 yd, xd, ud)与一个时钟唯一关联,只有当关联的时钟激活时才能直接访问。由于时钟方程中的所有变量必须属于同一个时钟,时钟错误可以在编译时被检测到。如果需要在方程中使用来自不同时钟的变量,必须使用显式类型转换操作符,例如 sample 用于从连续时间转换为时钟离散时间,或 hold 用于从时钟离散时间转换为连续时间。
- 连续时间变量在时钟脉冲时用 sample 进行采样。该操作符在时钟激活时返回连续时间变量的值。
- 当未为 Clock 定义参数时,时钟由时钟推断得出。
- 对于带有关联时钟的 when 子句,当子句内的所有方程都与给定时钟同步。所有与关联时钟关联的方程都一视同仁,无论它们是否在 when 子句内。这意味着当子句内的变量不适用自动采样和保持(需要显式采样和保持),并且在这种 when 子句中可以使用一般方程(对于需要在方程左侧引用变量的布尔条件的 when 子句,这是不允许的)。
- 控制器中的 when 子句也可以移除,控制器可以直接通过以下方程定义:
/* Discrete controller */
E * xd = A * previous(xd) + B * yd;
ud = C * previous(xd) + D * yd;
- previous(xd) 返回上一个时钟脉冲时 xd 的值。在第一次采样时刻,返回 xd 的初始值。
- 用 hold 将离散时间信号(如 ud)转换为连续时间信号。
- 如果一个变量属于特定的时钟,那么使用这个变量的所有其他方程,除了作为某些特殊操作符的参数外,也属于这个时钟,以及在这些方程中使用的所有变量。这个属性用于时钟推断,并允许只在少数地方定义关联时钟(只在采样器中,而在离散控制器和保持中,采样周期是推断的)。
- 本章的方法基于 Colaço 和 Pouzet(2003 年)提出的时钟演算和推断系统,并在 Lucid Synchrone 版本 2 和 3 中实现(Pouzet 2006 年)。然而,Modelica 方法还使用了 Forget, Boniol, Lesens, 和 Pagetti(2008 年)引入的基于有理算术的多速率周期时钟,作为 Lucid Synchrone 语义的扩展。这些方法属于同步语言类别(Benveniste, Caspi, Edwards, Halbwachs, Le Guernic, 和 Simone 2003年)。
# 时钟语义的基本原理
周期采样控制系统也可以用标准的 when 子句来定义,参见 When - 方程,以及采样操作符,参见函数形式的与事件有关的操作符。例如:
when sample (0 , 3) then
xd = A * pre ( xd ) + B * y ;
u = C * pre( xd ) + D * y ;
end when ;
带有布尔条件的 when 子句中的方程具有以下特性:(a)当 when 条件为真时,等号左边的变量被赋值,否则保持其值不变;(b)在 when 子句中未被赋值的变量可以直接访问(= 自动采样语义);(c)在 when 子句中赋值的变量可以在 when 子句外直接访问(= 自动保持语义)。
对于单个简单的采样块,使用标准的 when 子句效果很好,但使用时钟和时钟方程的同步方法提供了以下好处(尤其是对于大型采样系统):
- 可以检测到不一致的采样率,因为时钟分区替代了自动采样和保持语义。例如:
- 如果不同块中的 when 子句应属于同一控制器部分,但不同的 when 条件被给定,那么这将被接受(不会检测到错误)。
- 如果使用了像 Modelica_LinearSystems2.Controller 库这样的采样数据库,在每个块中都必须将块的采样定义为基础采样率的整数倍。如果几个块应属于同一控制器部分,并且给定了不同的整数倍,则翻译器必须接受这一点(不会检测到错误)。
- 需要较少的初始条件,因为只有一部分时钟变量需要初始条件 - 时钟状态变量。对于标准的 when 子句,所有在 when 子句中赋值的变量必须有初始值,因为在它们第一次被赋值之前,它们可能会被使用。因此,所有这些变量都是“离散时间状态”,尽管实际上只有它们的一个子集需要初始值。
- 可以使用更通用的方程,与需要一种限制形式的方程的标准 when 子句相比,其中左边必须是一个变量,以识别在 when 子句中被赋值的变量。这个限制可以被标准的 when 子句绕过,但对于时钟方程来说,这个限制是不存在的,这使得定义非线性控制算法更加方便。
- 时钟方程允许时钟推断,这意味着对于一个子系统,采样只需给定一次。对于标准的 when 子句,条件(采样)必须显式地传播到所有块,这对于大型系统来说是繁琐和容易出错的。
- 可以在同步模型中使用一般的连续时间模型(例如,一些高级控制器在控制器的前馈路径中使用了植物的逆模型,参见 Thümmel, Looye, Kurze, Otter, 和 Bals(2005))。这个强大的特性允许 Modelica 在控制器中使用非线性植物模型,这需要将带有嵌入式集成方法的连续时间模型导出,然后在定义控制器其余部分的环境中导入它。有了时钟方程,可以直接在 Modelica 中定义带有连续时间模型的时钟控制器。
- 时钟方程很容易优化,因为它们在每个事件时刻都被精确地评估一次。相比之下,一个标准的带有采样概念的 when 子句在概念上需要多次评估模型(在某些情况下,工具可以优化这一点,以避免不必要的评估)。标准 when 子句的问题是,在 v 被改变后,应该更新 pre(v) 并重新评估模型,因为方程可能依赖于 pre(v)。对于时钟方程,这个迭代可以省略,因为 previous(v) 只能出现在只在第一个事件迭代中运行的时钟方程中。
- 使用算术块的时钟子系统易于优化。当一个标准数学块(例如,加法)是时钟子系统的一部分时,它会自动被时钟化,仅在时钟方程触发时进行评估。对于标准的 when 子句,要么需要为每个操作提供一个单独的采样数学块,要么它会在概念上一直被评估。然而,工具可能会对标准的 when 子句执行类似的优化,这仅在大型采样系统中才有关系。
综上所述,时钟方程和时钟语义为实现控制系统,特别是大型采样数据系统,提供了一种安全的方式,使得翻译器在建模错误的情况下能够提供良好的诊断。通过这种方法,能够检测到不一致的采样率,减少了所需的初始条件,允许使用更通用的方程,简化了大型系统的时钟推断,使得在同步模型中使用一般的连续时间模型成为可能,还便于优化时钟方程和时钟子系统。
至于之前的段落,我们可以看到 Modelica 语言的同步行为通过引入额外的离散时间变量和方程,以及额外类型的 when 子句来定义。这使得模型能够以安全的方式定义大型采样数据系统,同时在建模错误的情况下,翻译器能提供有效的诊断。例如,通过定义周期时钟(如 Clock(3) 中的时钟),与时钟相关联的变量(如 yd、xd、ud 等)只能在相关联的时钟处于活动状态时直接访问,这有助于在编译时检测时钟错误。
总之,Modelica 的这种方法结合了 Colaço 和 Pouzet(2003)提出的时钟演算和推断系统,以及 Forget, Boniol, Lesens 和 Pagetti(2008)引入的基于有理算术的多速率周期时钟,作为 Lucid Synchrone 语义的扩展。这些方法属于同步语言的一类,提供了一种强大的工具,用于实现和优化复杂的控制系统模型。
# 定义
在本节中,将定义各种术语。
# 时钟和时钟变量
在离散时间表达式中定义了“离散时间 Modelica 表达式”这一术语,而在连续时间表达式和和非离散时间表达式中定义了“连续时间 Modelica 表达式”。在本章中,定义了两种与时钟相关联的离散时间表达式 / 变量,因此称为时钟离散时间表达式。以下定义了 Modelica 中不同类型的离散时间变量。
Definition 16.1. Piecewise-constant variable
基类型为 Real、Integer、Boolean、enumeration 和 String 的变量
Definition 16.2. Clock variable
时钟变量

示例:时钟变量:
Clock c1 = Clock (. . .);
Clock c2 = c1 ;
Clock c3 = subSample (c2 , 4);
Definition 16.3. Clocked variable
时钟变量
注意
此列表中没有包括时钟变量。这意味着时钟变量不能在需要时钟变量的地方使用。
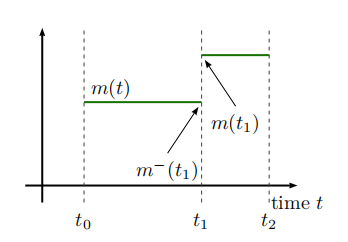
在关联时钟未激活的时刻,可以使用显式转换操作符查询时钟变量的值。在这种情况下,使用保持语义,换句话说,使用上一个事件瞬间的时钟变量的值。参见下图:一个时钟变量。用绿色虚线表示最后一次事件时刻值的保持外推:
# 基时钟和子时钟分区
时钟分区有两种:
Definition 16.4. Base-clock partition
基时钟分区标识一组必须一起在一个任务中执行的方程和变量集合。不同的基时钟分区可以关联到单独的任务以进行异步执行。
Definition 16.5. Sub-clock partition
子时钟分区标识基时钟分区的方程和变量的一个子集,与同一基时钟分区的其他子时钟分区部分同步,即在各自时钟的触发同时同步。
# 参数限制(组件表达式)
在以下各节中定义的内置操作符(具有函数调用语法)在输入参数上部分存在限制,这在 Modelica 函数中是不存在的。为了定义这些限制,使用了以下术语。
Definition 16.6. Component expression
组件表达式是一个有效的表达式的组件引用,即,不引用带有方程的模型或块。具体而言,它是(a)基类型、(b)派生类型、(c)记录、(d)这样一个实例(a-c)的数组、(e)由参数表达式(见下文)定义的这样一个数组(d)的一个或多个元素,或(f)记录的一个元素的实例。
本质特征是,一个或多个值与实例关联,这些值可以定义初始值,并且没有方程与实例关联。组件表达式可以是常数,也可以随时间变化。
在以下各节中,当定义具有函数调用语法的操作符时,用于输入参数(操作数)的一些常见限制。为了强调没有这样的限制,输入参数可能只是表达式。
限制输入参数为组件表达式的原因是,输入参数的初始值在输入参数的时钟的第一次触发之前返回,这对于一般表达式是不可能的。
限制输入参数为参数表达式的原因是,输入参数的值需要在翻译期间进行评估,以便在翻译期间进行时钟分析。
示例:previous 的输入参数被限制为组件表达式:
Real u1;
Real u2[4];
Complex c;
Resistor R;
...
y1 = previous(u1); // fine
y2 = previous(u2); // fine
y3 = previous(u2[2]);// fine
y4 = previous(c.im); // fine
y5 = previous(2 * u); // error (general expression, not component expression)
y6 = previous(R); // error (component, not component expression)
示例:子样本的命名参数因子被限制为参数表达式:
Real u ;
parameter Real p =3;
...
y1 = subSample(u, factor = 3); // fine (literal)
y2 = subSample(u, factor = 2 * p - 3); // fine (parameter expression)
y3 = subSample(u, factor = 3 * u); // error (general expression)
本章定义的运算符均不具备向量化功能,但部分运算符可直接对数组变量进行操作(包括时钟型数组变量,但不适用于时钟数组变量)。这些运算符不可在函数中调用。
# Clock 构造函数
下表中列出的重载构造函数可用于生成 clocks,可以用指定的命名参数或位置参数(根据表后的详细信息中显示的顺序)来调用它们。
| Expression | Description | Details |
|---|---|---|
| Clock() | Inferred clock | Operator 16.1 |
| Clock(intervalCounter, resolution) | Rational interval clock | Operator 16.2 |
| Clock(interval) | Real interval clock | Operator 16.3 |
| Clock(condition, startInterval) | Event clock | Operator 16.4 |
| Clock(c, solverMethod) | Solver clock | Operator 16.5 |
Operator 16.1 Clock
Clock ()
推断时钟。该操作符返回一个被推断的 clock。示例:
when Clock() then // equations are on the same clock
x = A * previous(x) + B * u;
Modelica.Utilities.Streams.print
("clock ticks at = " + String(sample(time)));
end when;
注意
在大多数情况下,不需要该操作符,方程可以在没有 when 子句的情况下编写。这种风格对于模型开发者来说很有用,如果他们希望明确标记必须属于一个 clock 的方程。
Operator 16.2 Clock
Clock (intervalCounter =intervalCounter , resolution =resolution)
有理数间隔 clock。第一个输入参数,intervalCounter,是一个时钟组件表达式或一个类型为 Integer、min=0 的参数表达式。第二个可选参数 resolution(默认为 1)是一个类型为 Integer、min=1 且单位为 "Hz" 的参数表达式。如果 intervalCounter 是值为零的参数表达式,则 clock 的周期由 clock 推断导出。如果 intervalCounte r是一个大于零的参数表达式,clock 定义了一个周期 clock。如果 intervalCounter 是一个时钟组件表达式,它必须大于零。结果是基本类型 Clock,在时间变为 tstart, tstart + interval 1, tstart + interval 1 + interval 2, … 时发生触发。clock 在模拟开始时的 tstart 或当控制器开启时开始。在模拟开始时,previous(intervalCounter)=intervalCounter.start,clock 首次触发。在第一次 clock 触发时,必须计算 intervalCounter,然后在 interval 1=intervalCounter/resolution 触发第二次 clock 触发。在时间 tstart + interval 1 的第二次 clock 触发时,必须计算新的 intervalCounter 值,然后安排下一个 clock 触发在 interval 2=intervalCounter/resolution,依此类推。
通过在返回的 clock 上使用 subSample, superSample, shiftSample 和 backSample 操作符,可以修改给定的间隔和时间偏移。
示例:
// first clock tick: previous(nextInterval) = 2
Integer nextInterval(start = 2);
Real y1(start = 0);
Real y2(start = 0);
equation
when Clock(2, 1000) then
// periodic clock that ticks at 0, 0.002, 0.004, ...
y1 = previous(y1) + 1;
end when;
when Clock(nextInterval, 1000) then
// interval clock that ticks at 0, 0.003, 0.007, 0.012, ...
nextInterval = previous(nextInterval) + 1;
y2 = previous(y2) + 1;
end when;
注意
Clock c = Clock(nextInterval, resolution) 的操作符 interval(c) 返回:previous(intervalCounter)/resolution(以秒为单位)。
Operator 16.3 Clock
Clock (interval =interval)
实数间隔 clock。输入参数 interval,是一个 clocked 组件表达式或一个参数表达式。interval 必须是严格正数(interval>0),类型为 Real,单位为 "s"。结果是基本类型 Clock,在时间变为 tstart, tstart + interval 1, tstart + interval 1 + interval 2, … 时触发。clock 在模拟开始时的 tstart 或当控制器开启时开始。这里下一个 clock 触发计划在 interval 1=previous(interval)=interval.start。在时间 tstart + interval 1 的第二个 clock 触发,下一个 clock 触发计划在 interval 2=previous(interval),以此类推。如果 interval 是参数表达式,clock 定义了一个周期 clock。
注意
lock 是用 previous(interval) 定义的。因此,对于排序,输入参数被视为已知的。通过在返回的 clock 上使用 subSample, superSample, shiftSample 和 backSample 操作符,可以修改给定的间隔和时间偏移。
Operator 16.4 Clock
Clock(condition=condition, startInterval=startInterval)
事件 clock。第一个输入参数 condition,是一个类型为 Boolean 的连续时间表达式。可选的 startInterval 参数(默认为 0)是 clock 的第一次触发时 interval() 返回的值。结果是基本类型 Clock,当 edge(condition) 变为真时触发。
这个 clock 用于由状态事件触发一个时钟分区,即连续时间分区中的 Real 变量的零交叉,或由硬件中断触发,该硬件中断在模拟模型中被建模为 Boolean。
示例:
Clock c = Clock(angle > 0, 0.1); // before first tick of c:
// interval(c) = 0.1
通过在返回的 clock 上使用 subSample, superSample, shiftSample 和 backSample 操作符,可以修改隐式给定的间隔和时间偏移,前提是基本间隔不小于隐式给定的间隔。
Operator 16.5 Clock
Clock(c=c, solverMethod=solverMethod)
求解器 clock。第一个输入参数 c,是一个 clock,操作符返回这个 clock。返回的 clock 与第二个输入参数 solverMethod 相关联,solverMethod 的类型为 String。如果 solverMethod 是空 String,那么这个 Clock 构造不会将积分器与返回的 clock 相关联。 示例:
Clock c1 = Clock(1, 10); // 100 ms, no solver
Clock c2 = Clock(c1, "ImplicitTrapezoid"); // 100 ms, ImplicitTrapezoid solver
Clock c3 = Clock(c2, ""); // 100 ms, no solver
除了推断 clock 和求解器 clock 外,在一个基本分区中可能有以下互斥的 clock 关联之一:
- 一个或多个有理数间隔 clock,前提是它们彼此一致。
(示例:假设 y=subSample(u),且 Clock(1,10) 与 u 相关联,Clock(2,10) 与 y 相关联,那么这是正确的,但如果 y 与 Clock(1,3) 相关联,那么这将是一个错误。) - 严格一个实数间隔 clock。
(示例:假设 Clock c = Clock(2.5),那么在同一个基本分区中的变量可以与 c 关联多次,但不能与 Clock(2.5) 关联多次。) - 严格一个事件 clock。
- 如果一个基础分区既没有关联实数间隔,也没有关联有理数间隔,也没有关联事件时钟,则会有一个默认时钟。在这种情况下,默认时钟会关联到最快的子时钟分区。
通常,工具会使用 Clock(1.0) 作为默认时钟,并会发出警告,表明它选择了一个默认时钟。
Clock 变量可以用于表达式的一种受限形式。通常,每个在 Clock 变量之间切换的表达式必须具有 parameter 变量性(以便在转换模型时可以进行时钟分析)。因此,Clock 变量上的下标和在 Clock 变量之间进行 if-then-else 切换的条件必须是 parameter 表达式,并且对于子时钟转换操作符有类似的限制。除此之外,允许以下表达式:
- 声明时钟数组。 (示例:Clock c1[3] = {Clock(1), Clock(2), Clock(3)}。)
- 时钟的数组构造器:{},[],cat。
- 时钟的数组访问。 (示例:sample(u, c1[2])。)
- 时钟的等式。(示例:c1 = c2。)
- 方程中时钟的 if 表达式。
示例:
Clock c2 =
if f > 0 then
sub Sample(c1,f)
elseif f < 0 then
superSample (c1 ,f)
else
c1;
- Clock 变量可以在 models、blocks、connectors 和 records 中声明。一个 Clock 变量可以用前缀 input、output、inner、outer 来声明,但不能用前缀 flow、stream、discrete、parameter 或 constant 来声明。
示例:
connector ClockInput = input Clock ;
# 时钟状态变量
Definition 16.7. Clocked state variable
个不是参数的组件表达式,previous 已被应用于此表达式。
时钟变量的前一个值可以通过下面列出的 previous 操作符来访问。
| Expression | Description | Details |
|---|---|---|
| previous(u) | Previous value of clocked variable | Operator 16.6 |
Operator 16.6 previous
previous (u)
输入参数 u 是一个组件表达式。如果 u 是一个参数,它的值会被返回。否则:输入和返回参数位于同一时钟上。在 u 的时钟的第一个触发或重置转换后,u 的初始值会被返回。在 u 的时钟的后续激活中,将返回 u 在前一个时钟激活中的值。
在时钟触发时,只需要时钟状态变量的(previous)值来计算该时钟上所有时钟变量的新值。这大致对应于连续时间中的状态变量。
# 划分操作符
一组时钟转换操作符共同作为不同时钟划分之间的边界。
# 基时钟转换操作符
下列操作符在连续时间表示和时钟时间表示之间进行转换,反之亦然。
| Expression | Description | Details |
|---|---|---|
| sample(u, clock) | Sample continuous-time expression | Operator 16.7 |
| hold(u) | Zeroth order hold of clocked-time variable | Operator 16.8 |
Operator 16.7 sample
sample(u, clock)
输入参数 u 是根据连续时间表达式和和非离散时间表达式的一个连续时间表达式。可选输入参数 clock 是 Clock 类型,可以在调用时作为命名参数(名称为 clock)或位置参数给出。该操作符返回一个与 clock 关联的时钟变量,当 clock 激活时,它的值是 u 的左极限(即 c 的事件触发前 u 的值)。如果没有提供 clock,它将被推断。
由于操作符返回 u 的左极限,它在连续时间划分和时钟划分之间引入了一个无穷小的延迟。这对应于现实,其中一个采样数据系统不能无限快地行动,即使对于非常理想化的模拟,也存在无穷小的延迟。排序的后果在下面讨论。
输入参数 u 可以是一个一般表达式,因为参数是连续时间的,因此总是有一个值。
它也可以是一个常数,参数或分段常数表达式。注意,sample 是一个重载函数:如果 sample 有两个位置输入参数,且第二个参数是 Real 类型,它是来自函数形式的与事件有关的操作符的操作符。如果 sample 有一个输入参数,或者它有两个输入参数且第二个参数是 Clock 类型,它是来自本节的基时钟转换操作符。
Operator 16.8 hold
hold(u)
输入参数 u 是一个时钟组件表达式(定义 16.3)(定义 16.6)或一个参数表达式。该操作符返回与 u 类型相同的分段常数信号。当 u 的时钟触发时,操作符返回 u,否则返回 u 在上一次时钟激活时的值。在 u 的第一次时钟激活前,操作符返回 u 的初始值。
由于输入参数在 u 的时钟的第一次触发前未定义,存在限制,它必须是组件表达式(或参数表达式),以便在这种情况下可以使用 u 的初始值。
示例:假设存在以下模型:
Real y(start = 1), yc;
equation
der(y) + y = 2;
yc = sample(y, Clock(0.1));
initial equation
der(y) = 0;
在第一次时钟触发时,yc 的值是 yc = 2(而不是 yc = 1)。原因是连续时间模型 der(y) + y = 2 首先被初始化,初始化后 y 的值是 2。在时间 = 0 时的第一次时钟触发时,y 的左极限是 2,因此 yc = 2。
# 模拟模型的排序
由于 sample(u) 返回 u 的左极限,左极限的 u 是一个已知值,基时钟划分的所有输入在排序过程中都被视为已知。由于周期和间隔时钟在一个时间点最多只能触发一次,且由于变量的左极限在事件迭代期间不会改变(即,重新评估与条件时钟相关联的基时钟划分总是得到相同的结果,因为 sample(u) 输入不改变,因此不需要重新评估),所有基时钟划分,不需要相互排序。相反,在一个事件瞬间,可以首先(并且一次)以任何顺序评估活动的基时钟划分。之后,评估连续时间划分。事件迭代只在连续时间划分上发生。在这种情况下,在 sample(u) 中访问 u 的左极限只是在进入划分时选择 u 的最新可用值,将其存储在划分的局部变量中,并在评估该划分中的方程时仅使用这个局部副本。
# 子时钟转换操作符
以下操作符可在同步时钟之间进行转换:
| Expression | Description | Details |
|---|---|---|
| subSample(u, factor) | Clock that is slower by a factor | Operator 16.9 |
| superSample(u, factor) | Clock that is faster by a factor | Operator 16.10 |
| shiftSample(u, shiftCounter, resolution) | Clock with time-shifted ticks | Operator 16.11 |
| backSample(u, backCounter, resolution) | Inverse of shiftSample | Operator 16.12 |
| noClock(u) | Clock that is always inferred | Operator 16.13 |
这些运算符具有以下特性:
- 输入参数 u 是一个被时钟控制的表达式或者类型为 Clock 的表达式。(操作符可以操作所有类型的时钟。)如果 u 是一个被时钟控制的表达式,操作符返回一个与表达式类型相同的被时钟控制的变量。如果 u 是类型为 Clock 的表达式,操作符返回一个 Clock - 除了 noClock,在此情况下会报错。
- 可选输入参数 factor(默认为 0,min = 0),以及 resolution(默认为 1,min = 1)是类型为 Integer 的参数表达式。
- 操作符的调用可以使用给定名称的命名参数(即,不是用于 u)或位置参数。
- 输入参数 shiftCounter 和 backCounter 是最小值为 0 的类型为 Integer 的参数表达式。
Operator 16.9 subSample
subSample(u, factor=factor)
时钟 y = subSample(u, factor) 是 u 的时钟的 factor 倍慢。在 u 的时钟的每个 factor 触发,操作符返回 u 的值。y 的时钟的第一次激活与 u 的时钟的第一次激活一致,然后 y 的时钟的每次激活都与 u 的时钟的每个 factorth 激活一致。如果没有提供 factor 或 factor 等于零,将会推断 factor。
Operator 16.10 superSample
superSample(u, factor=factor)
y = superSample(u, factor) 的时钟速度是 u 时钟的 factor 倍。每当 y 的时钟触发时,该算子会返回 u 时钟上一次触发时的 u 值。y 时钟的首次激活与 u 时钟的首次激活同步,随后 u 时钟各次激活之间的间隔被均分为 factor 次激活,使得 y 的第 1 + k · factor 次激活与 u 的第 1 + k 次激活保持同步。
因此,subSample(superSample(u, factor), factor) = u。
如果没有提供 factor 或 factor 等于零,将会推断 factor。如果事件时钟与基础时钟分区关联,则所有子时钟分区必须具有与该基础时钟有整数倍关系的结果时钟。
示例:
Clock u = Clock(x > 0);
Clock y1 = subSample(u, 4);
Clock y2 = superSample(y1, 2); // fine; y2 = subSample(u, 2)
Clock y3 = superSample(u, 2); // error
Clock y4 = superSample(y1, 5); // error
Operator 16.11 shiftSample
shiftSample(u, shiftCounter=k, resolution=resolution)
操作符 c = shiftSample(u, k, resolution) 将 u 的触发 s 之间的间隔分割成 resolution 等间隔的间隔 i。然后时钟 c 在 u 的每个触发后的 k 个间隔 i 后触发。
它导致:
shiftSample(u, k, resolution) =
subSample(shiftSample(superSample(u, resolution), k), resolution)
注意
由于 superSample 对事件时钟的限制,shiftSample 只能移动事件时钟的触发 s 数量,但不能引入新的触发 s。
示例:
// Rational interval clock
Clock u = Clock(3, 10); // ticks: 0, 3/10, 6/10, ...
Clock y1 = shiftSample(u, 1, 3); // ticks: 1/10, 4/10, ...
// Event clock
Integer revolutions = integer(time);
Clock u = Clock(change(revolutions), startInterval = 0.0);
// ticks: 0.0, 1.0, 2.0, 3.0, ...
Clock y1 = shiftSample(u, 2); // ticks: 2.0, 3.0, ...
Clock y2 = shiftSample(u, 2, 3); // error (resolution must be 1)
补充示例展示完整形式:
Integer intervalCnt(start=2);
Integer cnt(start=0);
Clock u = Clock(intervalCnt,1);
Clock s1 = shiftSample(u, 3, 2);
equation
when u then
cnt = previous(cnt) + 1;
intervalCnt = if (cnt>=2) then 1 else previous(intervalCnt);
end when;
这里 u 在 0, 2, 3, 4, 5, 6 处触发。首先,您通过 superSample 将每个采样间隔分割成两个等大小的部分,导致触发 s 为 0.0, 1.0, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5, 5.0, 5.5, 6.0。然后,简单的 shiftSample 移除前三个触发 s,得到 2.5, 3.0, 3.5, 4.0, 4.5, 5.0, 5.5, 6.0。最后,通过 subSample 移除每个点,s1 在 2.5, 3.5, 4.5, 5.5 处触发。
Operator 16.12 backSample
backSample(u, backCounter=cnt, resolution=res)
输入参数 u 是组件表达式(定义 16.6)或类型为 Clock 的表达式。这是 shiftSample 的反操作,这样 Clock y = backSample(u, cnt, res) 隐式定义了一个时钟 y,使得 shiftSample(y, cnt, res) 与 u 在相同的时间激活。如果 y 的时钟在 u 的基础时钟之前开始,则会报错。
在 y 的时钟的每个触发,操作符返回 u 在 u 的时钟的上一个触发的值。如果 u 是一个被时钟控制的组件表达式,在 u 的时钟的第一次触发之前,操作符返回 u 的初始值。
示例:
// Rational interval clock 1
Clock u = Clock(3, 10); // ticks: 0, 3/10, 6/10, ...
Clock y1 = shiftSample(u, 3); // ticks: 9/10, 12/10, ...
Clock y2 = backSample(y1, 2); // ticks: 3/10, 6/10, ...
Clock y3 = backSample(y1, 4); // error (ticks before u)
Clock y4 = shiftSample(u, 2, 3); // ticks: 2/10, 5/10, ...
Clock y5 = backSample(y4, 1, 3); // ticks: 1/10, 4/10, ...
// Event clock
Integer revolutions = integer(time);
Clock u = Clock(change(revolutions), startInterval = xx)
// ticks: 0, 1.0, 2.0, 3.0, ...
Clock y1 = shiftSample(u, 3); // ticks: 3.0, 4.0, ...
Clock y2 = backSample(y1, 2); // ticks: 1.0, 2.0, ...
Operator 16.13 noClock
noClock(u)
y 的时钟 = noClock(u) 总是被推断出来的,u 必须与 y 属于同一个基础时钟。在 y 的时钟的每个触发,操作符返回 u 在 u 的时钟的上一个触发的值。如果在 u 的时钟的第一次触发之前调用了 noClock(u),则返回 u 的初始值。
backSample 的澄清:
设a和b为正整数,且a < b:
yb = backSample(u, a, b)
ys = shiftSample(u, b-a, b)
那么当 ys 存在时,yb 也存在且 ys = yb。
变量 yb 在上述参数化中 a < b 存在,其时钟触发比 u 的时钟早一个触发。因此,backSample 基本上是具有不同参数化的 shiftSample,且 backSample.y 的时钟在 u 的时钟之前触发。在 u 的时钟触发之前,yb = u.start。
请注意,noClock(u) 并不等同于 sample(hold(u))。考虑以下模型:
model NoClockVsSampleHold
Clock clkl = Clock(0.1);
Clock clk2 = subSample(clkl, 2);
Real x(start = 0), y(start = 0), z(start = 0);
equation
when clkl then
x = previous(x) + 0.1;
end when;
when clk2 then
y = noClock(x); // most recent value of x
z = sample(hold(x)); // left limit of x (infinitesimally delayed)!
end when;
end NoClockVsSampleHold;
由于 sample 的无穷小延迟,当 clk2 触发时,z 将不会显示 x 的当前值,而是会显示其之前的值(左极限)。然而,y 会显示当前值,因为它没有无穷小延迟。
注意
计算 sample,subSample,superSample,backSample,shiftSample 和 noClock 操作符的导数是不合法的。
# 时钟 When 子句
除了先前讨论的 when 方程(参见 When - 方程),还引入了一个时钟控制的 when 子句:
when clockExpression then
<clocked equations>
...
end when;
时钟 when 子句不能嵌套,并且没有任何 elsewhen 部分。它不能在算法内部使用。时钟 when 子句中允许使用一般方程式。
对于时钟 when 子句,when 子句内的所有方程式都将由 clockExpression 给出的相同时钟进行时钟同步。
# 时钟划分
本节定义了如何推断时钟分区和与方程相关联的时钟。
通常,在对方程进行排序之前会进行时钟划分。这样的好处是时钟和符号转换错误是分开的。
每个时钟变量都与恰好一个时钟唯一关联。
在模型扁平化后,方程组中的每个方程、每个表达式和每个算法段要么是连续时间的,要么与恰好一个时钟唯一关联。在后一种情况下,它们分别被称为时钟方程、时钟表达式或时钟算法段。相关联的时钟要么通过 when 子句明确定义,要么通过以下要求隐式定义:时钟方程、时钟表达式和时钟算法段必须与其中使用的变量具有相同的时钟,转换操作符的第一参数的表达式除外。时钟推断意味着如果时钟没有明确定义,并且是从前两段中的所需属性推断出来的,那么推断变量、方程、表达式或算法段的时钟。
不含时钟转换运算符的表达式中,所有变量必须具有相同时钟,以便推断每个变量和表达式的时钟。时钟推断在数据流上既可前向也可后向进行,并能处理代数环路。该时钟推断方法利用方程组的变量关联集,即每个方程中出现的变量集合。
由于时钟分区完全由方程决定,两个不同的时钟分区可以由相同的表达式定义时钟。这是一个实现质量问题,这样的分区是同步执行的,例如,在实时仿真环境中将它们放在同一个任务中。
# 模型平坦化
时钟分区在概念上是在模型扁平化之后执行的,即重声明已经详细阐述、模型组件数组扩展为标量模型组件且重载解析完成之后进行的。此外,对内联函数的函数调用也已完成内联展开。
这被称为概念上的处理方式,因为只要最终结果与完全展开处理相同,工具可能会采用更高效的不同实现方式。例如,数组、矩阵方程和记录若具有相同时钟信号,则无需进行展开运算。
此外,每个作为时钟转换运算符(hold 和 backSample 除外)首个参数出现的非平凡表达式(非字面量、非常量、非参数、非变量)expr i,都会被递归替换为一个唯一变量 vi,并将方程 vi = expr i 添加至方程集合中。
# 方程和变量图的连通分量
考虑扁平化模型中的方程组 E 和未知变量集 V(非常量与参数),即 M=⟨E, V⟩。该划分通过无向图 ⟨N, F⟩ 来描述,其中节点 N 代表方程组与变量的集合,N=E∪V。对于 E 中的方程 e,其关联集 incidence(e) 是 V 的子集,通常指在 e 中词法层面出现的未知量。当变量 v 属于方程 e 的关联集(即 v∈incidence(e))时,图中方程 e 与变量 v 之间存在一条边 F:
一组时钟分区是该图的连通分量(维基百科,连通分量),其中对关联算子进行了适当的定义。
一个特殊情况是内置变量 time(参见内置变量 time)。在该分析中,每次使用 time 在概念上都被视为独立变量 timei,其导数 der(timei) = 1。
这意味着时间可以在不同分区中不受限制地使用。此外,这也意味着每个直接引用时间的分区都包含一个对导数的调用。
# 基时钟划分
目标是识别所有应该在同一任务中一起执行的时钟方程和变量,以及识别连续时间分区。
base-clock 分区是通过使用以下 incidence 定义进行 base-clock 推断来执行的:
incidence(e) = 在 e 中词法出现的未知变量,以及变量 x 在 der(x),pre(x) 和 previous(x) 中,除了作为 base-clock 转换操作符的第一个参数:sample 和 hold 以及 Clock(condition=...,startInterval=...)。
由此产生的一组连接组件,是根据 base-clocks 和连续时间分区对方程和变量的分区,Bi =⟨Ei,Vi⟩。
base-clock 分区根据以下属性被识别为时钟分区或连续时间分区:
在 sample(u) 中的变量u,在 y = hold(ud) 中的变量 y,以及在 Clock(b,startInterval=...) 中的变量 b,其中 Boolean b 位于连续时间分区。
相应地,变量 u 和 y 在 y = sample(uc),y = subSample(u),y = superSample(u),y = shiftSample(u),y = backSample(u),y = previous(u) 中,位于时钟分区。在时钟 when 子句中的方程也位于时钟分区。其他没有与上述任何操作符关联的变量的分区具有未指定的分区类型,并被视为连续时间分区。
所有连续时间分区都汇集在一起,形成连续时间分区。
示例:
// Controller 1
ud1 = sample(y,c1);
0 = f1(yd1, ud1, previous(yd1));
// Controller 2
ud2 = superSample(yd1,2);
0 = f2(yd2, ud2);
// Continuous-time system
u = hold(yd2);
0 = f3(der(x1), x1, u);
0 = f4(der(x2), x2, x1);
0 = f5(der(x3), x3);
0 = f6(y, x1, u);
在完成基准时钟分区后,识别出以下分区:
// Base partition 1 — clocked partition
ud1 = sample(y, c1); // incidence(e) = {ud1}
0 = f1(yd1, ud1, previous(ud1)); // incidence(e) = {yd1, ud1}
ud2 = superSample(yd1, 2); // incidence(e) = {ud2, yd1}
0 = f2(yd2, ud2); // incidence(e) = {yd2, ud2}
// Base partition 2 — continuous-time partition
u = hold(yd2); // incidence(e) = {u}
0 = f3(der(x1), x1, u); // incidence(e) = {x1, u}
0 = f4(der(x2), x2, x1); // incidence(e) = {x2, x1}
0 = f6(y, x1, u); // incidence(e) = {y, x1, u}
// Identified as separate partition, but belonging to partition 2
0 = f5(der(x3), x3); // incidence(e) = {x3}
# 子时钟划分
对于每个时钟分区 Bi,子时钟分区是通过使用以下 incidence 定义进行子时钟推断来执行的:
incidence(e) = 在 e 中词法出现的未知变量,以及变量 x 在 der(x),pre(x) 和 previous(x) 中,除了作为 sub-clock 转换操作符的第一个参数:subSample、superSample、shiftSample、backSample、noClock,以及第一个参数为 Boolean 类型的 Clock。
由此产生的一组连接组件,是根据子时钟对方程和变量的分区,Sij =⟨Eij,Vij⟩。
所得的方程和变量的集合应该能够分开解决,这意味着方程系统不能涉及不同的子时钟。
可以注意到:
示例:对之前的示例进行子时钟分区后,识别出以下分区:
// Base partition 1 (clocked partition)
// Sub-clock partition 1.1
ud1 = sample(y, c1); // incidence(e) = {ud1}
0 = f1(yd1, ud1, previous(yd1)); // incidence(e) = {yd1,ud1}
// Sub-Clock partition 1.2
ud2 = superSample(yd1, 2); // incidence(e) = {ud2}
0 = f2(yd2, ud2); // incidence(e) = {yd2,ud2}
// Base partition 2 (no sub-clock partitioning, since continuous-time)
u = hold(yd2);
0 = f3(der(x1), x1, u);
0 = f4(der(x2), x2, x1);
0 = f5(der(x3), x3);
0 = f6(y, x1, u);
# 子时钟推导
对于每个基时钟分区,需要确定基间隔,以及对于每个子时钟分区,需要确定子采样因子和偏移量。子时钟分区间隔受到 subSample 和 superSample 因子的约束,这些因子可能是已知的(或参数表达式)或未指定,以及由 shiftSample、shiftCounter 和 resolution,或 backSample、backCounter 和 resolution 所约束。这个约束集用于求解所有子时钟分区的间隔、子采样因子和偏移量。如果不存在解,则模型是错误的。
(在编译时必须能够确定约束集是有效的。然而,在某些情况下,可以推迟到运行时提供实际数字。)
需要能够处理在 1 到
(可以使用带符号的分子和分母的 64 位内部表示法,这提供了最小分辨率为
# 时钟离散化分区
目标是使每个连续时间 Modelica 模型都能在采样数据控制系统中使用。这是通过在时钟触发之间用定义的积分方法求解连续时间方程来实现的。有了这个特性,例如,可以反转植物的非线性动态模型,参见 Thümmel, Looye, Kurze, Otter 和 Bals(2005),并将其用于与时钟相关联的先进控制系统的前馈路径。
该特性还允许定义多速率系统:连续时间模型的不同部分与不同的时钟相关联,并在时钟触发之间用不同的积分方法求解,例如,一个非常快的子系统使用具有小步长的隐式求解器,而一个慢的子系统使用具有大步长的显式求解器。
借助本节中定义的语言元素,连续时间方程可用于时钟分区。在此,连续时间方程在时钟触发之间使用定义的积分方法进行求解。
从连续时间分区的视角来看,时钟触发不被解释为事件,而是被视为积分器必须精确命中的步长。因此,在时钟触发时不会触发事件处理(前提是模型在此时刻没有触发显式事件)。
时钟触发的解释与手动离散化控制器的解释相同,例如 z 变换。
尚未定义如何处理在求解连续时间分区时触发的事件。例如,工具可以像对待通常模拟一样处理事件—但只在与时钟触发相关联的时间检查它们。另外,可能会字面上解释关系,以便不再触发事件(为了积分步骤的时间总是相同的,这是硬实时要求所必需的)。然而,即使关系不生成事件,when 子句和操作符 edge 和 change 应该表现正常。
从时钟分区的视角来看,连续时间分区是离散化的,离散化的连续时间变量在时钟触发时只有一个值。因此,这样的分区与任何其他时钟分区一样进行处理。特别是,必须使用 sample、hold、subSample 等操作符来传递离散化连续时间分区与其他分区的信号。在此,离散化的连续时间分区被视为一个时钟分区。
# 时钟离散时间和离散化连续时间
本节定义了一个正交概念时钟变异性。除非另有明确说明,否则具有连续时间或离散时间之类的变异性的表达式意味着该表达式位于一个未与时钟关联的分区内。如果表达式存在于一个非连续时间分区中,则它是一个有时钟变异性的表达式。
在子时钟推断之后,每个与时钟关联的分区都必须被归类为时钟离散时间分区或时钟离散化连续时间分区。
如果时钟分区不包含操作符 der、delay、spatialDistribution、函数形式的与事件有关的操作符的任何与事件相关的操作符(noEvent 和 smooth 除外),以及不包含具有布尔条件的 when 子句,那么它是一个时钟离散时间分区。
(也就是说,时钟离散时间分区是由差分方程描述的标准采样数据系统。)
如果时钟分区不是时钟离散时间分区,那么它是一个时钟离散化连续时间分区。当在连续时间状态变量 x 上使用 previous(x) 时,那么 previous(x) 将使用 x 的初始值作为第一个时钟触发的值。
在时钟分区中使用函数形式的与事件有关的操作符的操作符 sample 是有问题的。建议进行诊断,特别是如果操作符旨在以比时钟触发更快的速度生成事件,否则采样应理想地调整到时钟触发。
(允许在时钟分区中使用 sample 的原因是为了使任何连续时间 Modelica 模型都能够包含在采样数据控制系统中。请注意,即使采样比时钟触发慢(甚至相同速率),它仍然引入了可能的不均匀采样问题。)
在时钟离散时间分区中,所有生成事件的机制都不再适用。特别是,事件触发数学函数的关系和任何内置操作符(触发事件的数学函数)都不会触发事件。
# 求解器方法
与时钟离散化连续时间分区关联的积分方法由字符串定义。预定义类型 ModelicaServices.Types.SolverMethod 使用 choices 注解定义了相应工具支持的方法。
(ModelicaServices 包含特定于工具的定义。由于不同的工具可能具有不同的值,因此使用字符串而不是枚举,这样枚举的整数映射可能会产生误导,因为相同的值可能表示不同的积分器。)
下面是一些标准化的求解器方法名称:
type SolverMethod = String annotation(choices(
choice="External" "Solver specified externally",
choice="ExplicitEuler" "Explicit Euler method (order 1)",
choice="ExplicitMidPoint2" "Explicit mid point rule (order 2)",
choice="ExplicitRungeKutta4" "Explicit Runge-Kutta method (order 4)",
choice="ImplicitEuler" "Implicit Euler method (order 1)",
choice="ImplicitTrapezoid" "Implicit trapezoid rule (order 2)"
)) "Type of integration method to solve differential equations in a clocked " +
"discretized continuous-time partition."
如果工具支持 SolverMethod 中的某个积分器,它必须使用上述的求解器方法名称。
(工具还可以支持其他积分器。通常,一个工具至少支持“External”和“ExplicitEuler”方法。如果工具不支持模型中定义的积分方法,通常会打印一条警告消息,并将方法更改为“External”。)
如果求解器方法是“External”,那么与该方法关联的分区将由模拟环境使用模拟环境中定义的解决方案方法在 interval() 长度的间隔内进行积分。
(这样的解决方案方法的一个例子可能是拥有与离散化连续时间分区关联的时钟的表,并且每个时钟有一个方法选择。在这种情况下,解决方案方法可能是一个具有步长控制的变步长求解器,在两个时钟触发之间进行积分。模拟环境也可能结合所有与“External”方法关联的分区,以及所有连续时间分区,并将它们与模拟环境选择的求解器一起积分。)
如果求解器方法不是“External”,那么该分区将使用给定方法和步长 interval() 进行积分。
求解器相对于可以至少在概念上转换为状态空间形式的基础普通微分方程进行定义,其中 x(t) 是状态的连续时间实向量,y(t) 是代数和 / 或输出变量的连续时间或离散时间实 / 整数 / 布尔 / 字符串向量:
求解器方法应用于子时钟分区。这样的分区具有由 sample(u)、subSample(u)、superSample(u)、shiftSample(u) 和 / 或 backSample(u) 标记的显式输入 u。此外,这样分区的输出 y 由 hold(y)、subSample(y)、superSample(y)、shiftSample(y) 和 / 或 backSample(y) 标记。这些操作符的参数分别在上述概念普通微分方程中和下面的离散化公式中用作输入信号 u 和输出信号 y。
求解器方法(“External”除外)通过从时钟触发
| SolverMethod | Solution method |
|---|---|
| "ExplicitEuler" | |
| "ExplicitMidPoint2" | |
| "ExplicitRungeKutta4" | |
| "ImplicitEuler" | Equation system with unknowns: |
| "ImplicitTrapezoid" | Equation system with unknowns: |
初始条件将在时钟的第一个触发处使用,第一个积分步骤将从时钟的第一个触发到第二个触发。
示例:假设微分方程:
input Real u;
Real x(start = 1, fixed = true);
equation
der(x) = -x + u;
将被转换为使用“ExplicitEuler”方法的时钟离散化连续时间分区。下面的模型是手动实现:
input Real u;
parameter Real x_start = 1;
Real x(start = x_start); // previous(x) = x_start at first clock tick
Real der_x(start = 0); // previous(der_x) = 0 at first clock tick
protected
Boolean first(start = true);
equation
when Clock() then
first = false;
if previous(first) then
// first clock tick (initialize system)
x = previous (x);
else
// second and further clock tick
x = previous(x) + interval() * previous(der_x);
end if;
der_x = -x + u;
end when;
对于隐式积分方法,通过在方程的符号转换期间利用离散化公式,可以提高效率。例如,线性微分方程然后被映射到线性而非非线性代数方程组,同时还可以利用方程的结构。有关详细信息,请参阅 Elmqvist、Otter 和 Cellier(1995)。对于隐式积分方法,可能需要关联额外的数据,例如,解决非线性代数方程组的相对容差,或者在硬实时要求的情况下的最大迭代次数。这些数据是特定于工具的,通常要么用厂商注解定义,要么在模拟环境中给出。
# 将求解器关联到分区
求解器方法(SolverMethod)可以通过重载的 Clock 构造函数 Clock(c, solverMethod = ...) 与时钟关联。如果时钟与时钟分区关联,并且求解器方法与此时钟关联,则该分区会与之一同进行积分。
示例:
// Continuous PI controller in a clocked partition
vd = sample(x2, Clock(Clock(1, 10), solverMethod="ImplicitEuler"));
e = ref - vd;
der(xd) = e / Ti;
u = k * (e + xd);
// Physical model
f = hold(u);
der(x1) = x2;
m * der(x2) = f;
# 求解器方法的推断
如果求解器方法没有显式地与分区关联,它将通过与子时钟推断相似的机制进行推断。
首先,为每个子时钟分区构造一个集合,只包含这个子时钟分区。然后按照以下方式合并这些集合:对于每个没有指定求解器方法的集合,该集合会与与其连接的集合(这些集合可能包含求解器方法)合并,这一过程重复进行,直到无法合并更多集合为止。以这种方式连接的集合应该是相同基时钟分区的一部分,并且通过子时钟转换操作符(subSample,superSample,shiftSample,backSample 或 noClock)连接。
- 如果这个集合包含多个不同的求解器方法值,那么它是一个错误。
- 如果集合包含连续时间方程:
- 如果这个集合不包含求解器方法,那么它是一个错误。
- 否则,使用指定的求解器方法。
- 如果集合不包含连续时间方程,那么不需要求解器方法。
示例:
model InferenceTest
Real x(start = 3) "Explicitly using ExplicitEuler";
Real y "Explicitly using ImplicitEuler method";
Real z "Inferred to use ExplicitEuler";
equation
der(x) = -x + sample(1, Clock(Clock(1, 10), solverMethod="ExplicitEuler"));
der(y) = subSample(x, 2) +
sample(1, Clock(Clock(2, 10), solverMethod="ImplicitEuler"));
der(z) = subSample(x, 2) + 1;
end InferenceTest;
model IllegalInference
Real x(start = 3) "Explicitly using ExplicitEuler";
Real y "Explicitly using ImplicitEuler method";
Real z;
equation
der(x) = -x + sample(1, Clock(Clock(1, 10), solverMethod="ExplicitEuler"));
der(y) = subSample(x, 2) +
sample(1, Clock(Clock(2, 10), solverMethod="ImplicitEuler"));
der(z) = subSample(x, 4) + 1 + subSample(y);
end IllegalInference;
这里,z 是一个连续时间方程,直接连接到具有不同求解器方法的 x 和 y 分区。
# 时钟分区的初始化
Modelica 模型的标准初始化方案不适用于时钟离散时间分区。相反,初始化以以下方式进行:
- 时钟离散时间变量不能在 initial equation 或 initial algorithm 部分中使用。
- 属性 fixed 不能应用于时钟离散时间变量。对于应用了 previous 的变量,属性 fixed 为 true,否则为 false。
# 其他操作符
下面列出了一些额外的实用操作符:
| Expression | Description | Details |
|---|---|---|
firstTick(u) | Test for first clock tick | Operator 16.14 |
interval(u) | Interval between previous and present tick | Operator 16.15 |
这些操作符在连续时间分区中被调用时是错误的。
Operator 16.14 firstTick
firstTick(u)
此操作符在表达式的时钟的第一次触发时返回 true,在时钟的所有后续触发时返回 false。可选参数 u 仅用于时钟推断。
Operator 16.15 interval
interval(u)
此操作符返回表达式的时钟的上一次触发和当前触发之间的间隔。可选参数 u 仅用于时钟推断。在时钟的第一次触发,将返回以下内容:
- 如果指定的时钟间隔是参数表达式,则返回该值。
- 否则,返回指定间隔的变量的初始值。
- 对于事件时钟,返回事件时钟构造函数的额外 startInterval 参数。
interval 的返回值是一个标量实数。
示例:一个离散 PI 控制器使用连续 PI 控制器的参数进行参数化,以便该离散块对采样周期的变化具有鲁棒性。这是通过离散化一个连续 PI 控制器实现的(这里使用了一个隐式欧拉方法):
block ClockedPI
parameter Real T "Time constant of continuous PI controller";
parameter Real k "Gain of continuous PI controller";
input Real u;
output Real y;
Real x(start = 0);
protected
Real Ts = interval(u);
equation
/* Continuous PI equations: der(x) = u / T; y = k * (x + u);
* Discretization equation: der(x) = (x - previous (x)) / Ts;
*/
when Clock() then
x = previous (x) + Ts / T * u;
y = k * (x + u);
end when;
end ClockedPI;
一个连续时间模型被反转、离散化并用作 PI 控制器的前馈控制器(在同一个分区中使用 der、previous、interval):
block MixedController
parameter Real T "Time constant of continuous PI controller";
parameter Real k "Gain of continuous PI controller";
input Real y_ref, y_meas;
Real y;
output Real yc;
Real z(start = 0);
Real xc(start = 1, fixed = true);
Clock c = Clock(Clock(0.1), solverMethod="ImplicitEuler");
protected
Real uc;
Real Ts = interval(uc);
equation
/* Continuous-time, inverse model */
uc = sample(y_ref, c);
der(xc) = uc;
/* PI controller */
z = if firstTick() then 0 else
previous(z) + Ts / T * (uc - y_meas);
y = xc + k * (xc + uc);
yc = hold(y);
end MixedController;
# 语义
子分区的执行需要精确的时间管理以实现适当的同步。这意味着,测试一个 Real-valued 时间变量以确定采样时刻是不可能的。一种可能的方法是使用计数器来处理子采样调度,
Clock_i_j_ticks =
if pre(Clock_i_j_ticks) < subSamplingFactor_i_j then
1 + pre(Clock_i_j_ticks)
else
1;
并测试计数器以确定子时钟何时开始计时:
Clock_i_j_activated =
BaseClock_i_activated and Clock_i_j_ticks >= subSamplingFactor_i_j;
Clock_i_j_activated 标志被用作子分区方程的防护条件。
考虑以下示例:
model ClockTicks
Integer second = sample(1, Clock(1));
Integer seconds(start = -1) = mod(previous(seconds) + second, 60);
Integer milliSeconds(start = -1) =
mod(previous(milliSeconds) + superSample(second, 1000), 1000);
Integer minutes(start = -1) =
mod(previous(minutes) + subSample(second, 60), 60);
end ClockTicks;
一个可能的实现模型如下所示,采用 Modelica 3.2 语义。基础时钟被确定为 0.001 秒,子采样因子分别为 1000 和 60000:
model ClockTicksWithModelica32
Integer second;
Integer seconds(start = -1);
Integer milliSeconds(start = -1);
Integer minutes(start = -1);
Boolean BaseClock_1_activated;
Integer Clock_1_1_ticks(start = 59999);
Integer Clock_1_2_ticks(start = 0);
Integer Clock_1_3_ticks(start = 999);
Boolean Clock_1_1_activated;
Boolean Clock_1_2_activated;
Boolean Clock_1_3_activated;
equation
// Prepare clock tick
BaseClock_1_activated = sample(0, 0.001);
when BaseClock_1_activated then
Clock_1_1_ticks = if pre(Clock_1_1_ticks) < 60000 then 1 + pre(Clock_1_1_ticks) else 1;
Clock_1_2_ticks = if pre(Clock_1_2_ticks) < 1 then 1 + pre(Clock_1_2_ticks) else 1;
Clock_1_3_ticks = if pre(Clock_1_3_ticks) < 1000 then 1 + pre(Clock_1_3_ticks) else 1;
end when;
Clock_1_1_activated = BaseClock_1_activated and Clock_1_1_ticks >= 60000;
Clock_1_2_activated = BaseClock_1_activated and Clock_1_2_ticks >= 1;
Clock_1_3_activated = BaseClock_1_activated and Clock_1_3_ticks >= 1000;
// Sub partition execution
when {Clock_1_3_activated} then
second = 1;
end when;
when {Clock_1_1_activated} then
minutes = mod(pre(minutes) + second, 60);
end when;
when {Clock_1_2_activated} then
milliSeconds = mod(pre(milliSeconds) + second, 1000);
end when;
when {Clock_1_3_activated} then
seconds = mod(pre(seconds) + second, 60);
end when;
end ClockTicksWithModelica32;