# 函数库开发规范
函数库的开发过程中需要遵循相应的开发规范,以确保函数库的高质量和可扩展性,并方便其在 Syslab 环境中进行集成和管理。同时为了保证 Julia 函数库的可维护性,开发函数库需要遵守 Julia 编码规范。
# 目录结构规范
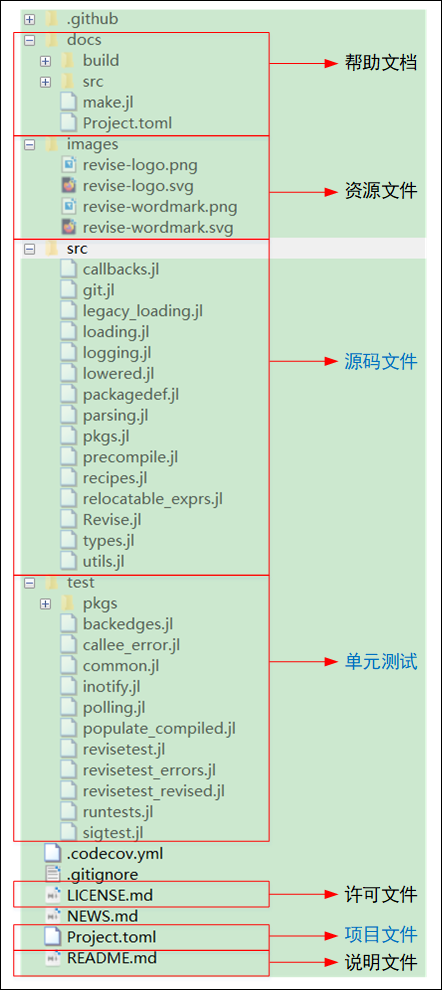
一个标准的包(如 Revise),其目录结构如下图所示:
- docs:帮助文档文件夹
- examples:可选,测例文件夹
- images:可选,资源文件夹
- src:库源码文件夹
- test:单元测试文件夹
- Project.toml:项目文件
- LICENSE.md:许可证文件
- README.md:库说明文件
- …:用户还可以添加其它文件夹
# 函数定义规范
# 导出列表
函数、类型、全局变量和常量等,可以通过 export 添加到模块的导出列表。通常,导出接口列表位于或靠近模块定义的顶部,以便轻松找到它们。
首先,可以看下典型 Julia 包的做法,如下图所示:
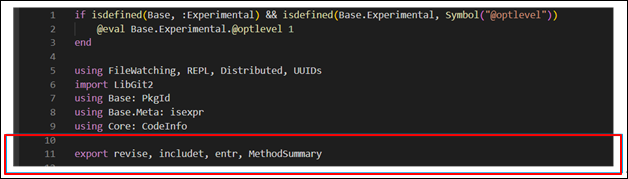
例如,MyExample 包的导出列表,定义如下:
module MyExample
export greet
greet() = print("Hello World!")
…
end # module
# 函数定义
Julia 包中最常用的就是函数,函数定义由两部分组成:一是函数注释,包括函数原型和函数功能说明;二是函数的算法实现。
首先,可以看下典型 Julia 包的做法,如下图所示:
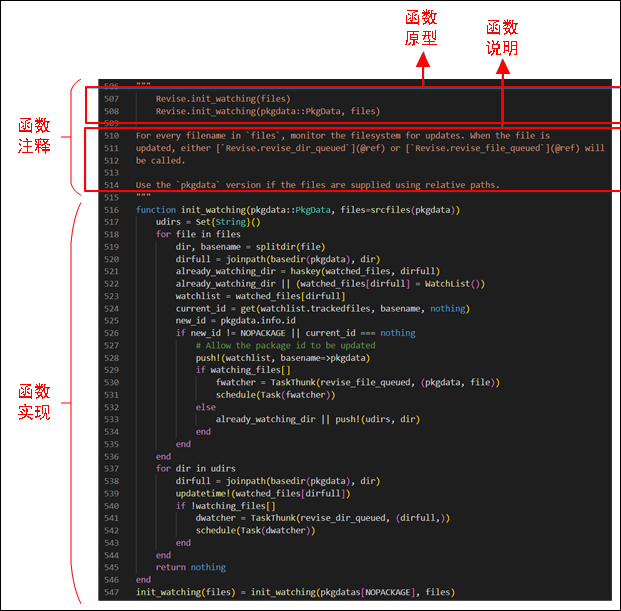
例如,为 MyExample 包添加domath和pythagoras函数,如下所示:
module MyExample
export greet, domath, pythagoras
greet() = print("Hello World!")
"""
domath(x::Number)
Return `x + 5`.
"""
domath(x::Number) = x + 5
include("math.jl")
end # module
其中,MyExample/src/math.jl中的函数定义如下:
"""
pythagoras(a,b)
勾股定理,英文名为 Pythagoras 也称为毕达哥拉斯定理。
在平面上的一个直角三角形中,两个直角边边长的平方加起来等于斜边长的平方。
如果设直角三角形的两条直角边长度分别是`a`和`b`,斜边长度是`c`,那么数学公式为:
``{\\rm{c = }}\\sqrt {{a^2} + {b^2}}``
返回斜边长`c`
"""
function pythagoras(a, b)
c = sqrt(a^2 + b^2)
end
# 工程管理规范
每个函数库包含一个项目文件project.toml,用于对函数库进行工程管理,其中包括函数的信息、函数库的依赖信息等,如下图所示:
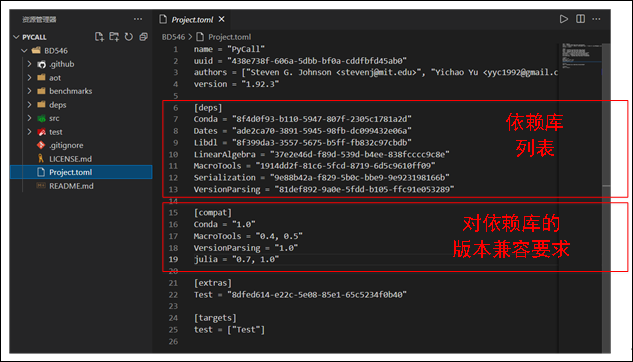
包的项目文件project.toml,内容解释如下:
- name:包的名称;
- uuid:包的唯一标识;
- authors: 包的作者,书写规则为
[NAME <EMAIL>, NAME <EMAIL>]; - version: 包的版本。必须遵守 SemVer 语义化版本,简而言之:
- 破坏性更新:主版本 major release
- 新特性:小版本 minor release
- bug 修复:补丁版本 patch release
- [deps]:该库依赖的其它函数库,书写规则为
name = uuid; - [compat]:该库对依赖库的版本兼容要求。关于 compat 字段的规则,请参考 http://pkgdocs.julialang.org/v1/compatibility/ (opens new window)。典型的写法是:
[compat] # 指 D 的所有 0.1.* 和 0.2.* 的版本都兼容 D = "0.1, 0.2" - [extras]:单元测试规定的依赖库,与
[targets]一起使用; - [targets]:单元测试规定的依赖库。
提示
extras和targets请参考 https://pkgdocs.julialang.org/v1/creating-packages/#Test-specific-dependencies-1 (opens new window)。
# 单元测试规范
# 单元测试
对于绝大多数代码开发来说, 测试是保障代码质量和可靠性的最有力的工具。在这里我们介绍测试的基本内容和手段,以单元测试为主。
Julia 的测试代码存放在<包根目录>/test文件夹内并通过pkg > test调用test/runtests.jl文件。该文件可以理解为 Julia 单元测试的 main 文件。
@test:检查表达式的结果是否为 true。如果为 true 则测试通过。
using Test @test 1 + 1 == 2 @test ones(2, 2) == [1 1; 1 1]
@testset:用于将各个测试组织在一起,例如:
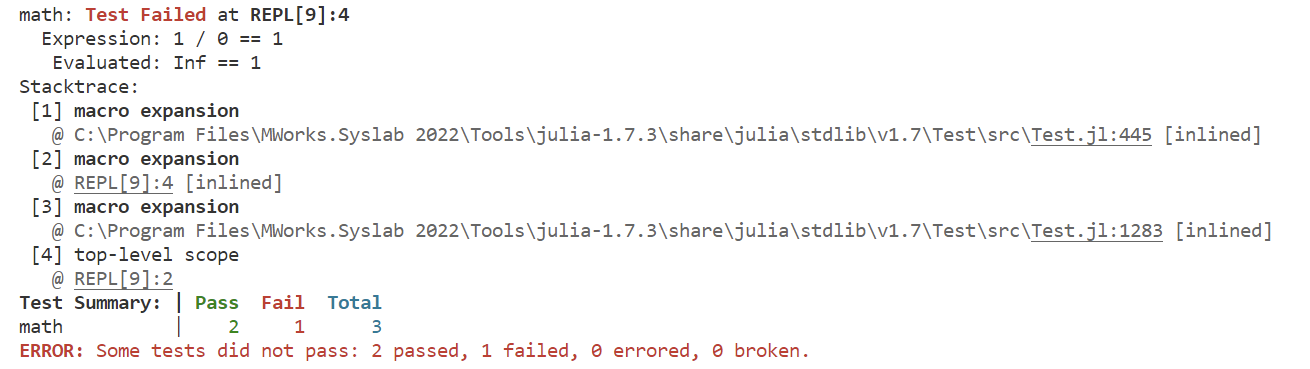
@testset "math" begin @test 1 + 1 == 2 @test 1 - 1 == 0 @test 1 / 0 == 1 end其中,不通过的测试会被标记为 Fail,此时要么是测试代码没写对,要么是对应的功能存在 bug。
# 常用工具
Julia 开发生态最常用的测试工具如下:
- Test (opens new window):为 Julia 标准库;
- ReferenceTests (opens new window):将结果与参考文件绑定做交叉对比测试,常用于图片的测试;
- Suppressor (opens new window):用于抑制或捕获 stdout/stderr 的输出结果,经常与 Test 联合使用;
- Random.seed!:用于重置随机数种子,对于某些不定的情况会有用。
# Julia 编码规范
# 语法概要
用 4 个空格缩进;
一行 92 个字符;
模块名和类型名用大骆驼命名格式;
方法名用小写字母 + 下划线的形式(注意区别于官方规则: 官方建议尽量不用下划线);
用
using引入模块,每个模块一行, 在文件的开头引入;写尽可能详细的注释;
合理利用空格增加代码可读性;
行尾不要空格;
避免括号后追加空格:
Int64(value)好过Int64( value )。
# 详细规则
# 代码规范
模块引入
每次引入一个;
根据模块名字字母排列;
引入的函数按照字母或者实际意义顺序排列;
引入内容很长时,可以按照合理规则分组;
推荐用
using而不是用import。二者唯一的区别是,
using引入的module,调用其内部函数时需要加module名,而import引入的则不需要:# Yes: using Example Example.hello(x::Monster) = "Aargh! It's a Monster!" Base.isreal(x::Ghost) = false # No: import Base: isreal import Example: hello hello(x::Monster) = "Aargh! It's a Monster!" isreal(x::Ghost) = false
函数输出
函数输出语句需要放在模块的头部,在引入依赖以后;
不要对一个
export语句换行,要么一行一个,要么按需分组。# Yes: export foo export bar export qux # Yes: export get_foo, get_bar export solve_foo, solve_bar # No: export foo, bar, qux
全局变量
- 尽量避免使用全局变量;
- 如果需要使用,加前缀 const,命名规则为全部大写;
- 全局变量在文件的头部位置定义,紧跟在 imports 和 exports 之后。
函数命名
- 函数名需要能表示函数的属性或者功能,不需要体现参数类型:
submit_bid(bid)应该改成submit(bid::Bid); - 函数名尽量控制在一到两个单词内,小写加下划线分隔;
- 函数越简单约好,尽量把复杂函数拆分;
- 只用于内部使用的函数,用下划线开头。
- 函数名需要能表示函数的属性或者功能,不需要体现参数类型:
方法定义
只有在函数非常短的时候,才用短函数定义方式:
# Yes: foo(x::Int64) = abs(x) + 3 # No: foobar(array_data::AbstractArray{T}, item::T) where {T<:Int64} = T[ abs(x) * abs(item) + 3 for x in array_data ]用长函数定义的语法时,用
return显式返回,且显式声明返回值:# Yes: function Foo(x, y) # code ... return nothing end参数列尽量不要换行,除非特别长,如果要换行,就要每个参数一行,或者按照位置参数和关键字参数分组换行,不要随意地到长度限制再换行:
# Yes: function foobar( df::DataFrame, id::Symbol, variable::Symbol, value::AbstractString, prefix::AbstractString="", ) # code end # Ok: function foobar(df::DataFrame, id::Symbol, variable::Symbol, value::AbstractString, prefix::AbstractString="") # code end # No: Don't put any args on the same line as the open parenthesis if they won't all fit. function foobar(df::DataFrame, id::Symbol, variable::Symbol, value::AbstractString, prefix::AbstractString="") # code end关键字参数需要用
;和位置参数区分开。
空格
紧跟着各种括号内部不要空格:
foo(ham[1],[eggs])好过foo( ham[ 1 ], [ eggs ] );逗号和分号前面不要加空格;
比较和赋值等二元操作符两端要加空格,
=,+=,==, ->等;一些数值相关的二元操作符两侧不加空格,
^, //, -1;在
Range定义中,:两侧不要加空格,复杂的Range定义用括号括起来,避免歧义:(1+2):(3+4);不要为了对齐引入超过一个的空格:
# Yes: x = 1 y = 2 long_variable = 3 # No: x = 1 y = 2 long_variable = 3不要引入不必要的空行,比如同一个函数的不同单行分派之间不需要换行;
如果函数调用语句中,参数过长(比如嵌套函数),则要按照如下规则换行: 函数的左右括号要在同一缩进水平,参数要多缩进一级,参数和关键字在多数情况下应该每个一行;
constraint = conic_form!( SOCElemConstraint(temp2 + temp3, temp2 - temp3, 2 * temp1), unique_conic_forms, )数组或者元组定义的时候,括号缩进规则类似:
arr = [ some_long_sub_array_A, some_long_sub_array_B, ] nestedarr = [ [ some_long_A, some_long_B ], [ another_long_A, another_long_B ] ]三引号,三反引号需要缩进:
str = """ hello world! """ cmd = ``` program --flag value parameter ```用空行分隔不同的多行代码块:
# Yes: if foo println("Hi") end for i in 1:10 println(i) end quote x = 1 y = 2 a = x + y end在控制流和返回语句之间添加空行:
function foo(bar; verbose=false) if verbose println("baz") end return bar end
数据结构和控制流
- 具名元组中的
=类似于关键字参数的用法,两端不加空格,空具名元组应该写成NamedTuple()而不是(;); - 浮点数不要省略小数点前后的
0: 0.1, 2.0而不是.1 2.; - 三元操作符
?:只能用于单行语句,如果语句超过单行,则应该用传统的if elseif else的方式; for循环中应该只用in关键词,尽量不要用=或者∈,在列表展开式中也适用。
- 具名元组中的
类型标注
类型标注需要尽可能的抽象,而不是尽可能的具体
如果需要性能,则可以用类型参数的方式:
# 类型参数 mutable struct MySubString{T<:AbstractString} <: AbstractString string::T offset::Integer endof::Integer end # 相比于传统方式: mutable struct MySubString <: AbstractString string::AbstractString offset::Int endof::Int end
提示
在类型参数的情况下,数据结构在定义的时候就确定了,在整个生命周期中数据类型是限定了的,所以会有更好的性能优化。可以在开发的时候使用下边这种抽象类型,在优化的时候再改成类型参数的模式。
版本声明
为了保持简洁和一致性,声明版本的时候不要使用脱字符
^:# Yes: DataFrames = "0.17" # No: DataFrames = "^0.17"代码注释
- 注释是用来解释(复杂的)代码的逻辑的,不要在简单代码上也过度注释;
- 注释要随着代码的更新而更新;
- 注释应该是完整的语句,首字母大写(除非首字母小写有特殊意义,比如是代码中的指示词/变量);
- 短注释的末尾句号.可以省略,块注释需要在每句结尾加上句号;
- 如果注释不能保证在与代码同行时不超过单行限制,就不要把注释写在代码同行;
- 注释与同行代码之间至少要有两个空格,
#与注释内容之间有一个空格; - 提到 Julia 的时候,通常 Julia 指代 Julia 语言,julia 指代 Julia 可执行命令。
文档
大多数模块、类型、函数都应该有规范的
docstrings(尤其是需要export的函数),但是内嵌函数或者很简单的函数不需要额外添加docstrings;给一个函数添加文档,而不是给函数的一个方法添加文档;
只有新方法与老方法有区别时,才给已有文档的函数的新方法添加文档;
文档需要用 Markdown 格式书写,同样遵守 92 chars 的规则;
复杂参数的方法建议用以下文档模板:
""" mysearch(array::MyArray{T}, val::T; verbose=true) where {T} -> Int Searches the `array` for the `val`. For some reason we don't want to use Julia's builtin search :) # Arguments - `array::MyArray{T}`: the array to search - `val::T`: the value to search for # Keywords - `verbose::Bool=true`: print out progress details # Returns - `Int`: the index where `val` is located in the `array` # Throws - `NotFoundError`: I guess we could throw an error if `val` isn't found. """ function mysearch(array::AbstractArray{T}, val::T) where T ... end
# 测试规范
测试组
Julia 中提供了测试组(test sets)来方便用户按照应用逻辑对测试代码进行分组。
runtests.jl文件最好只包含一个主测试组,其他分组可以嵌套在主分组内。比较操作
大多数测试会写成
@test x == y的形式,==不会进行类型检查,所以@test 1.0 == 1是可以通过的,所以不必要为了类型一致牺牲代码可读性:# Yes: @test value == 0 # No: @test value == 0.0
# 性能和优化
Julia 中很多性能提升都是来自于针对输入类型对实际调用函数进行优化。
尽量不要声明全局变量(会阻碍 Julia 进行代码优化),如果要声明,加上前缀
const第一次实际调用某函数时,会根据输入类型编译该函数,所以测试函数性能不应该测试其第一次执行的性能,
BenchmarkTools中的@benchmark和@btime宏可以执行多次函数,得到更客观的性能测试结果
# 其他注意事项
不推荐在函数库中提交
Manifest.toml文件Manifest.toml文件的目的是为了将整个项目的依赖完全锁定在一个具体版本, 从而可以通过pkg> instantiate来得到一个指定的运行版本。对于函数库的开发来说,当你在Project.toml中记录了足够完整的compat字段后,就不太会再需要提供Manifest.toml文件了。禁止使用不带限制的
@reexport命令Reexport.jl提供了一个非常方便的宏命令@reexport用于将其他 Julia 包所导出的名字再一次导出。但是,在使用时需要注意:禁止使用不带限制的
@reexport using SomePkg推荐使用限定符号的
@reexport using SomePkg: sym1
以上 Julia 编码规范来源于:Blue: a Style Guide for Julia (opens new window),基于这个规范翻译而来并做了修订。