# 模型分析结果信息解读
介绍模型翻译后输出的模型统计信息,以及如何基于相关信息优化原模型。
# 概述
Modelica是一种陈述式建模语言,其相较过程式编程语言的主要优势在于,以陈述式方程为基础的非因果建模方式极大地降低了复杂系统的描述难度,建模者无需推导模型变量的求解逻辑,可以更专注于系统模型的功能定义与实现。此外,基于Modelica描述的系统模型与所选用的仿真工具以及求解算法完全解耦,更有利于模型的复用与传递。对于Modelica编译工具而言,其工作内容是将原始的层次化物理模型约简为可供求解器算法解算的数学模型,实现非因果系统模型自动规划成可序列执行的过程式求解代码。在这个知识自动化过程中,编译工具采用符号处理相关技术对原模型进行分析与优化,如DAE降指标、移除冗余方程、约简线性与非线性方程系统等。实际上,建模者可以通过参与到上述分析优化过程,控制最终形成的求解数学模型,从而提高仿真质量与求解效率。为实现这一目标,建模者需要了解模型分析结束后输出的各项信息含义,以及这些信息如何帮助建模者优化原模型。在此背景下,本文详细介绍MWORKS.Sysplorer 2024a在模型翻译后输出的模型统计信息,并介绍如何基于相关信息优化原模型。
# 模型统计信息
模型统计信息是指模型翻译结束后在输出窗口记录的模型变量和方程相关数据,包含3大块内容,后续章节将按照各字段排列顺序进行详细说明:
1)原始模型
2)约简后模型
3)初值系统

# 原始模型
原始模型是指当前翻译的层次化模型,更具体的是将层次化模型平坦后得到的模型,在仿真设置页面的模型翻译选项卡中勾选“生成平坦化Modelica代码到.mof文件”选项,模型检查结束后将在仿真工作目录下生成平坦化模型文件。
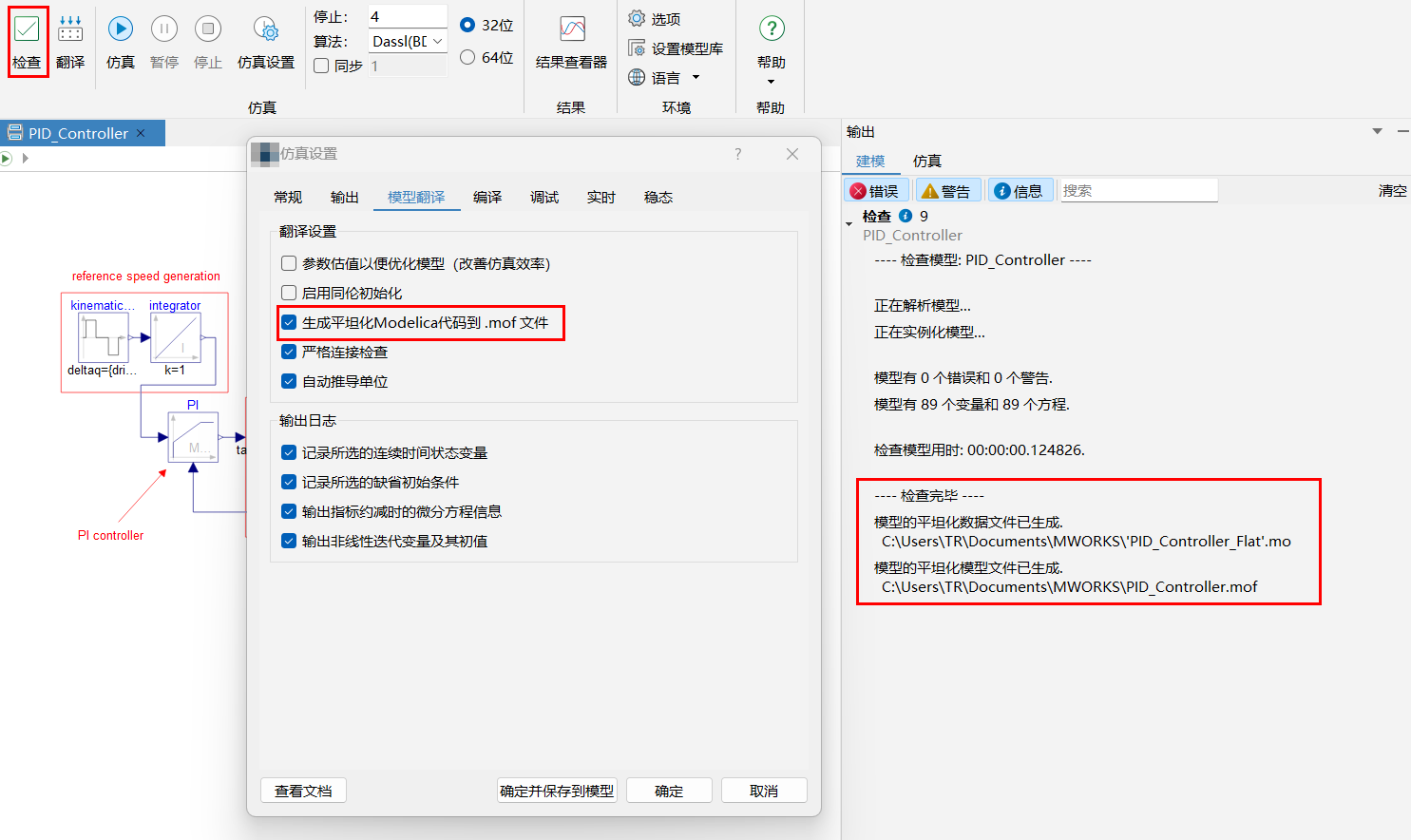
# 常量
常量是指平坦化模型中变量声明时带有constant关键字前缀的模型变量。
# 参量
参量是指平坦化模型中变量声明时带有parameter关键字前缀的模型变量。
# 输入变量
输入变量是指平坦化模型中变量声明时带有input关键字前缀的模型变量。注意,对于未平坦的层次化模型,只有顶层模型(即当前翻译的模型)中声明的input变量、input连接器才属于输入变量。
# 输出变量
输出变量是指平坦化模型中变量声明时带有output关键字前缀的模型变量。注意,对于未平坦的层次化模型,只有顶层模型(即当前翻译的模型)中声明的output变量、output连接器才属于输出变量。
# 变量
变量是指平坦化模型中除常量、参量以及输入变量之外的其它变量(包括模型输出变量以及内部变量,类比于FMI规范中因果性为output和local的变量)。注意,自定义函数中声明的局部变量不属于模型变量。
# 微分变量
微分变量是模型变量的一个子集,通常包括平坦化模型中包含在der()运算符中的模型变量以及stateSelect属性为always的模型变量。
# 方程
方程表示平坦化模型中变量的约束,包含equation和algorithm中的内容,方程数等于变量数是模型恰定的必要条件,否则模型翻译时将报错缺方程或方程冗余。
model Case1_1
record R
constant Real c = 1; // 常量
parameter Real p = 1; // 参量
Real x; // 变量
end R;
constant Real c1 = 1; // 常量
parameter Real p1 = 1; // 参量
R ra;
input Real u; // 输入变量
output Real y; // 输出变量
Real x1, x2; // 变量(微分变量)
equation
der(x1) = time;
der(x2) = x2;
ra.x = time;
y = x1 + x2;
end Case1_1;
model 'Case1_1_Flat' “平坦化模型”
constant Real 'c1'=1;
parameter Real 'p1'=1;
constant Real 'ra.c'=1;
parameter Real 'ra.p'=1;
Real 'ra.x'(unit="s");
input Real 'u'(start=0.0);
output Real 'y'(unit="s");
Real 'x1'(unit="s");
Real 'x2'(unit="s");
equation
der('x1') = time;
der('x2') = 'x2';
'ra.x' = time;
'y' = 'x1'+'x2';
end 'Case1_1_Flat';
# 约简后模型
原始模型是由陈述式方程系统描述的物理模型。模型翻译过程中,内核分析程序基于符号处理等分析手段将原始物理模型约简为可供求解器算法解算的数学模型。不同的Modelica平台或不同版本内核约简后的模型存在一定差异,影响着模型求解质量与效率。因此,了解约简所使用的技术手段以及约简后的模型信息,有助于优化原模型,提升模型求解质量与效率。
# 常量
约简后的模型常量包括两部分:
1)原模型中声明为 constant 的变量(声明可变性即为常量);
2)经分析后确定其实际可变性为常量的时不变量。
常量的特点是模型经翻译后其数值不可变,因此在模型翻译后将原模型中的实际可变性为常量的变量归纳到常量集合中,如估值后的参量(通过勾选模型翻译选项卡中的参数估值选项,或参量声明时通过annotation添加估值注解Evaluate=true等)、绑定方程(声明方程、元素变型)等式右侧为非字面值常量表达式的参量、声明方程的等式右侧为常量表达式的变量、不依赖于任何可变量的变量等等。
由于常量为时不变量,其数值通过一次计算即确定,后续仿真过程中不存在重复计算,因此一定程度降低了模型整体计算量。
model Case1_2
model A
constant Real c = 1; // 常量
parameter Real p1 = c; // 声明方程右端项为非字面值常量表达式
parameter Real p2;
Real x;
equation
x = p1 * p2 * sin(time);
end A;
constant Real c1 = 1; // 常量
parameter Real p1 = 1; // 因p2估值而间接估值后成为常量
parameter Real p2 = p1 + c1 annotation(Evaluate=true); // 添加估值注解的参量
A a(p2 = c1); // 参量变型的等式右端项为非字面值常量表达式
Real x = c1 + 0.5; // 声明方程右端项为常量表达式
Real y(start = 0);
equation
y ^ 2 - 2 * y + 1 = 0; // 不依赖任何可变量的时不变量
end Case1_2;
# 参量
约简后的模型参量依据其因果性(数值的计算方式)被划分为自由参量和依赖参量。
自由参量
原模型中如果参量的绑定方程不依赖于其它常参量(仅为字面常数),且属性
fixed=true(默认属性值),则该参量为自由参量。自由参量是一类独立可调的参量,其数值可由建模者设定。模型翻译后,在仿真页面的仿真浏览器中自由参量的数值显示在输入框中,在启动仿真前可对其进行修改,也可通过开启仿真调试模式,执行仿真过程中的在线调参。参数估值可提升模型分析和求解效率:
模型分析过程中自由参量将在符号简化时得以保留,所以会出现在最终形成的数学方程中,如
,使用仿真设置/模型翻译选项卡提供的参数估值功能可以将模型中所有的自由参量替换为数值常数。参数估值后可有效降低模型中表达式的复杂度,提升模型分析效率。同时,参数估值影响模型分析后的数学方程形式,比如减小线性和非线性方程组撕裂后的环路大小,从而提升求解效率。为了利用参数估值的效用,建议在建模时为无需在线调参的参量添加估值注解,或在模型翻译选项卡中勾选参数估值选项。 model Case1_3 parameter Real p1 = 2.5 annotation(Evaluate=true); parameter Real p2 = 1.2 annotation(Evaluate=true); parameter Real p3 = 3.0 annotation(Evaluate=true); Real x1; Real x2; Real x3; equation p1 * x1 + p2 * x2 - p3 * x3 = 0.5 * time; p2 * x1 - p3 * x2 = -time; p3 * x1 - p1 * x2 - p2 * x3 = 0; end Case1_3;
依赖参量
依赖参量的数值非独立可调,而是依赖于其它变量计算得来。依赖参量包括具有 fixed=false 属性的参量、绑定方程依赖于其它模型参量的参量、绑定方程或约束方程为参量表达式的变量等等。
model Case1_4 parameter Real p1 = 1; // 自由参量 parameter Real p2(fixed=false); // 依赖参量 parameter Real p3 = p1 + 0.5; // 依赖参量 Real x(start = 0); Real y = p1 + 1; // 依赖参量 Real z; // 依赖参量 initial equation p2 = x + 5; equation der(x) = x - 1; z ^ 2 = p3; end Case1_4;
# 时变变量
时变变量是指其值可随时间发生变化的未知变量,需要在仿真过程中动态求解。时变变量是原模型变量集合排除掉上述成为“常量”、“参量”以及下述别名变量后的变量子集。时变变量的数量反映出待求解数学模型的规模。
状态变量
- 状态变量与微分变量不等价
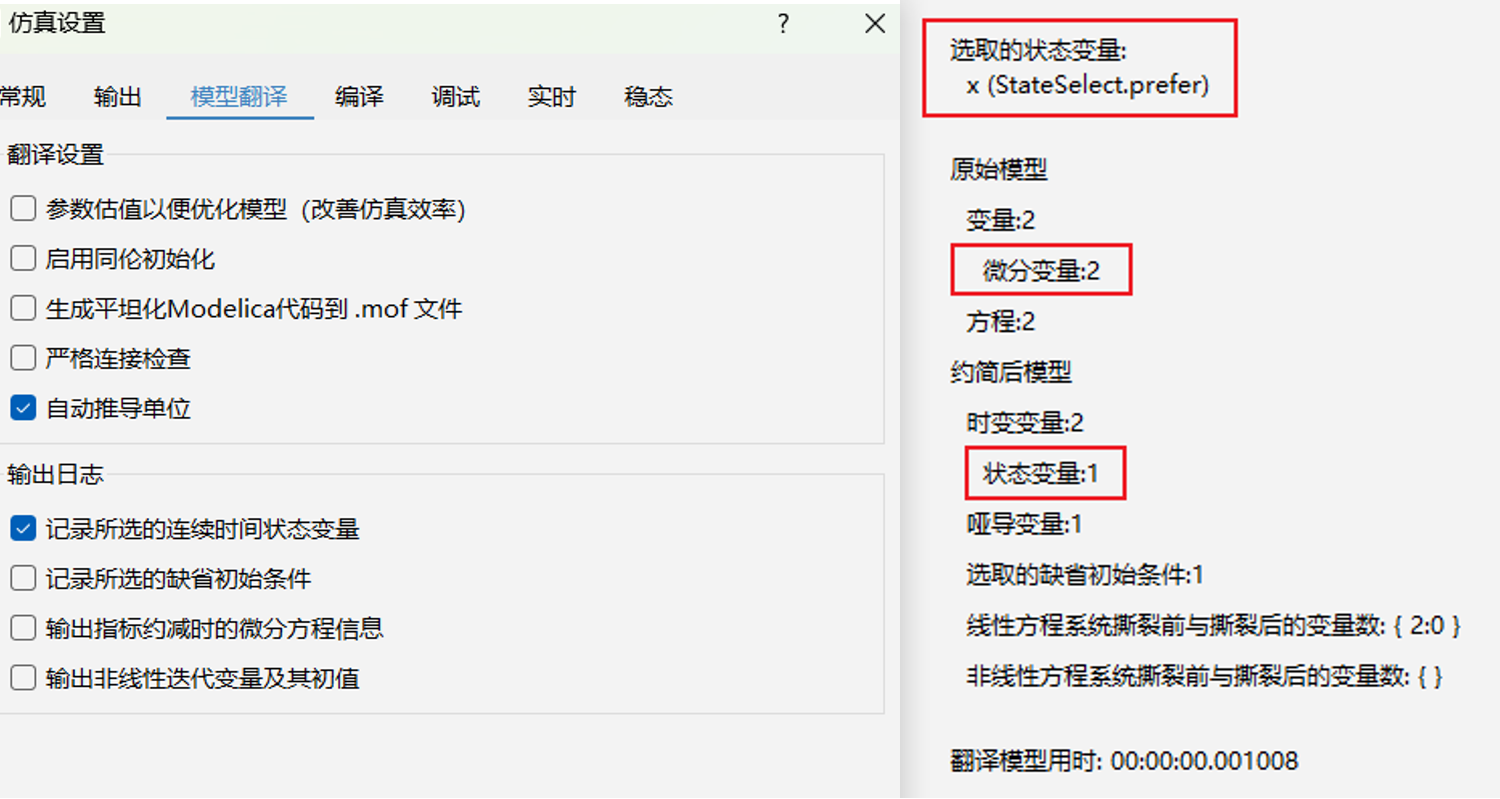
状态变量是时变变量的一个子集,更进一步地,状态变量通常是微分变量的一个子集,通过数值积分计算。状态变量的个数是模型的固有属性,并不一定等于模型中的微分变量个数,如当原模型中的微分变量之间存在约束时,状态变量的个数将小于微分变量,如下例所示。模型翻译时,分析程序将根据微分变量的 stateSelect 属性选择状态变量。因此,建模时设置微分变量的 stateSelect 属性可控制最终选取的状态变量,详见下一小节内容。若待选取的微分变量具有相同的stateSelect枚举值,分析程序将依据默认策略选取,这可能导致不同的Modelica平台或不同版本内核最终确定的状态变量存在差异。模型翻译后选取的状态变量可通过勾选模型翻译选项卡中输出日志选项“记录所选的连续时间状态变量”打印至输出面板。状态变量是影响模型求解结果和求解效率的关键因素,同一模型的两组不同状态变量集合可能产生差异明显的计算结果或计算效率,当求解表现不符合预期时,建模者应检查是否为状态变量选取差异性所导致。
model Case1_5
Real x(start = 1, stateSelect = StateSelect.prefer); // 状态变量的选取将导致求解结果的差异性
Real y(start = 0, stateSelect = StateSelect.default); // 尝试改变stateSelect属性对比计算结果
equation
der(x) + der(y) = time;
x - y = 0.5 * time; // 微分变量之间存在约束,两者并不独立,故只从两者中选择其一为状态变量
end Case1_5;
- 状态变量选取
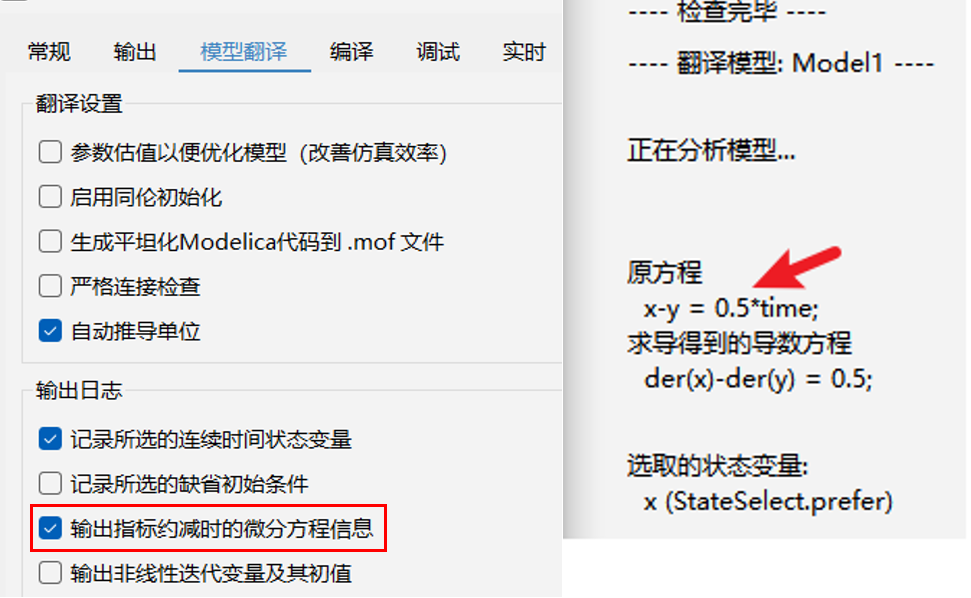
模型中微分变量之间存在约束是较为常见的情况,如上例中的 DAE)。模型翻译时,分析程序将采用“降指标”技术将微分代数方程转化为常微分方程(ODE),具体地,降指标过程中分析程序将会对微分变量的约束方程进行求导,使得该方程中能出现导数项,通过勾选模型翻译选项卡中“输出指标约减时的微分方程信息”可以将相关约束方程及其求导得到的微分方程打印到输出面板。由于状态变量是通过数值积分计算所得,而数值积分误差会导致原微分变量之间的约束关系不再满足,称这种现象为约束违约。因此,原约束方程中的微分变量不能同时成为状态变量,必须将其中之一选取为代数变量,通过原约束关系进行解算,这就是降指标过程中存在状态变量选取的缘故。原约束方程中出现的微分变量属于候选的状态变量,如前所述分析程序将基于微分变量的stateSelect属性进行选择,因此建模者可通过调整约束方程中各微分变量的stateSelect枚举值大小控制最终选取的状态变量,如上例 StateSelect.prefer大于 StateSelect.default,最终选取
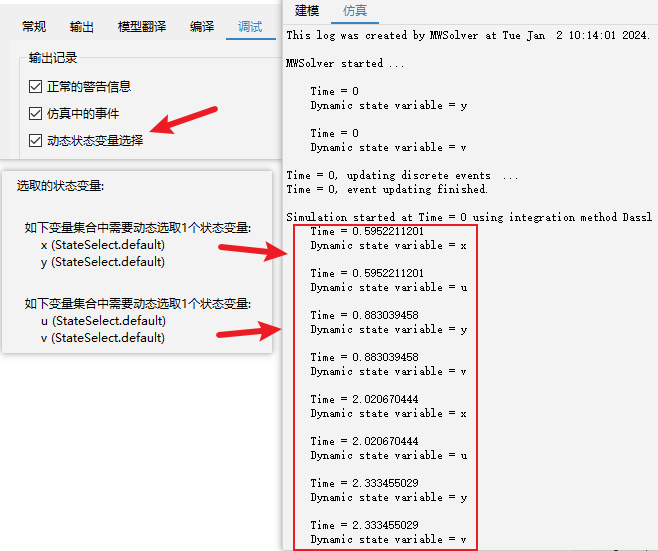
通常情况下,模型翻译结束后状态变量也就确定了,称其为静态选取的状态变量。有些情况下,在分析阶段无法直接确定约束方程中哪个微分变量成为状态变量更合适,分析程序则会引入动态状态及其候选变量集合。动态状态可以是候选集合中的任意变量,且随时可切换。模型求解过程中,求解器将动态检测候选集合中谁更适合成为状态变量。在仿真设置页面的调试选项卡中勾选“动态状态变量选择”,则仿真过程中输出面板将记录动态状态切换相关信息,如下例所示。
model Case1_6
// 动态状态选择案例-单摆模型
Real x(start = 0.8); // 单摆端点x坐标
Real y; // 单摆端点y坐标
Real v; // 单摆端点垂直速度分量
Real u(start = 0); // 单摆端点水平速度分量
Real F; // 单摆铰接点受力
parameter Real m = 1;
parameter Real l = 1; // 摆长
equation
der(x) = u;
der(y) = v;
m * der(v) = -m * 9.81 - F * y / l;
m * der(u) = -F * x / l;
x * x + y * y = l ^ 2; // 微分变量存在非线性代数约束方程
end Case1_6;
注意
状态变量动态切换会导致模型求解效率下降,建模时应尽量避免,如在建模方法的选取上,应使用引入微分变量更少的方法(如下例的单摆模型仅 2 个微分变量),同时应尽量避免微分变量直接或间接产生时变或非线性代数约束关系。
model Case1_7
// 无动态状态案例-单摆模型
Real x(start = 0.8, fixed=true); // 单摆端点x坐标
Real y; // 单摆端点y坐标
Real v; // 单摆端点垂直速度分量
Real u(start = 0, fixed=true); // 单摆端点水平速度分量
Real F; // 单摆铰接点受力
Real theta; // 单摆摆角
Real w; // 单摆角速度
Real a; // 单摆角加速度
parameter Real m = 1;
parameter Real l = 1; // 摆长
equation
w = der(theta);
a = der(w);
x = l * sin(theta);
y = l * cos(theta);
u = l * cos(theta) * w;
v = -l * sin(theta) * w;
m * l * a * cos(theta) = F * sin(theta);
m * l * a * sin(theta) = -F * cos(theta) + m * 9.81;
end Case1_7;
- 代数变量求导
上述讨论的重点是微分变量之间存在约束关系时,致使有些微分变量无法成为状态变量,因此存在状态变量选择的过程。另一种情况是微分变量仅与普通变量存在代数约束关系,此时该微分变量也可能不是状态变量。从计算关系的角度理解,状态变量是通过数值积分计算的,如果通过依赖推导发现模型的某个微分变量由其它变量计算可得,那么该微分变量必不能成为状态变量。上述情况的一种使用场景是,建模者希望得到某一个关注变量的变化率,因此引入一个额外的变量使其等于关注变量的导数,即代数变量求导,如下例所示。由于模型中出现了该微分变量的微分项如der(y),为了计算该微分项,分析程序将通过符号求导的方式递归地对微分变量的代数约束方程求导,直到构造出一组相容的计算式。需要了解的是,上述符号求导可能会失败,如微分变量的计算式中存在一些复杂的自定义或外部函数。对代数变量求导不仅会增加分析阶段的工作量,还会增加许多不必要的求解计算代码,因此不建议使用这种方式。如果仅是期望观察该变量的变化率,采用仿真结果后处理中的曲线运算-微分能达到相同效果。
model Case1_8
Real x;
Real y(start = 0);
Real z;
equation
x = 0.5 * time;
y = 2 * x + 1; // 分析计算依赖可知,微分变量y由代数变量x计算可得,因此y不能成为状态变量
der(y) = z; // 引入变量z获取变量y的变化率,执行代数变量求导
end Case1_8;

- 状态变量的连续性
状态变量是通过数值积分计算的,而数值积分算法通常要求状态变量足够连续,如要求其高阶导数连续,否则会导致积分过程困难甚至失败。状态变量及其导数可以是分段连续,但跳变位置处应触发具体的事件,使得连续积分过程能够正常中止与重启,如经典的跳球模型(BouncingBall)使用reinit重置速度状态量。如果在模型中错误使用noEvent屏蔽事件而造成了状态导数的不连续,这极有可能造成积分过程缓慢甚至失败等情况。
- 状态变量的规模影响积分效率
大型系统模型的状态变量可能达到成千上万的规模,成为影响模型求解效率的重要因素。未使用任何模型解耦方式所构建的大型系统模型,其状态变量以向量形式同时积分计算,这使得模型整体积分推进过程由系统中变化率最剧烈的部分主导。从变步长算法的角度理解,系统模型中变化缓慢的部分积分一个大时间步长仍能保证精度,而变换剧烈的部分只能积分一个小时间步长,由于状态变量以向量形式同时积分计算,限制了当前步只能采用一个小时间步长。这种情况下,在整个积分区间,频繁计算模型的平缓变化部分是无意义的。此外,当选用的积分算法为隐式方法时(如Dassl、Radau5、ImplicitEuler等),单步积分过程涉及非线性方程组求解,其中非线性迭代变量为所有的状态变量。非线性方程组求解耗时具有不确定性,是模型求解耗时不随状态变量增加而线性增长的主要因素。如果仿真效率不尽人意,可以考虑在建模时采用合适的解耦手段处理大系统模型,避免统一模型翻译后计算代码耦合带来的计算效率问题。目前2024a支持的解耦手段包括使用Co-Simulation FMU封装子系统、利用同步时钟分隔子系统。
- nominal 的效用
Modelica 规范为实型变量定义了nominal属性,nominal称为名义值或标称值,表示该物理量的基准值或额定值,如电路模型中定义电机功率的名义值为额定功率、液压模型中定义腔体压强变量的名义值为设计工作压强等。实型变量的名义值将用于尺度缩放、容差设置等数值计算的多个方面,有助于提升问题收敛速度。通常,对于模型中的非线性迭代变量和状态变量,建模时应尽量提供其名义值。

# 别名变量
对于模型中存在等式关系的变量,如 A = B、A + C = 0,模型分析时仅会保留其一如保留 A,而将模型中的变量 B 全部替换为 A,变量 C 全部替换为 -A,以此提升后续分析及求解效率,变量 B/C 则称为变量 A 的正/负别名变量。别名关系具有传递性,如存在多个等式约束 A = B;B = C;C = D;若 A 得以保留,则变量 B、C、D 均为变量 A 的别名变量。
# 选取的缺省初始条件
模型的初始状态以及部分离散时间变量的初值都是自由的,需要额外引入初始约束条件进行限定才能保证模型的确定性,详见后续初值系统内容。注意,只有确定的模型才能保证在不同Modelica平台或不同版本内核中得到一致的仿真结果。Modelica规范定义了initial equation、initial algorithm以及when initial等添加初始条件的方式。如果建模时未通过上述方式添加必要的初始约束条件,则原模型初值系统处于欠约束状态,分析程序将自动补充缺省初始条件。缺省初始条件一般是将变量赋值为其 start 值,即 x=x.start,若该变量无显式给定的 start 值,则使用该类型的默认值,如实型和整型变量为 0,布尔类型变量为 false。输出面板中会记录选取的缺省初始条件个数,通过勾选模型翻译选项卡中的“记录所选的缺省初始条件”,则可将补充的初始条件打印到输出面板。
model Case1_9
Real x1; // 状态变量,无start值
Real x2(start = 1); // 状态变量,显式给出start值
Real y(start = 1); // 离散时间变量
// 缺省初始条件与下述注释内容等价
// initial equation
// x1 = 0;
// x2 = 1;
// y = 1;
equation
when sample(0, 1) then
y = pre(y) + 1;
end when;
der(x1) = time;
der(x2) = time;
end Case1_9;
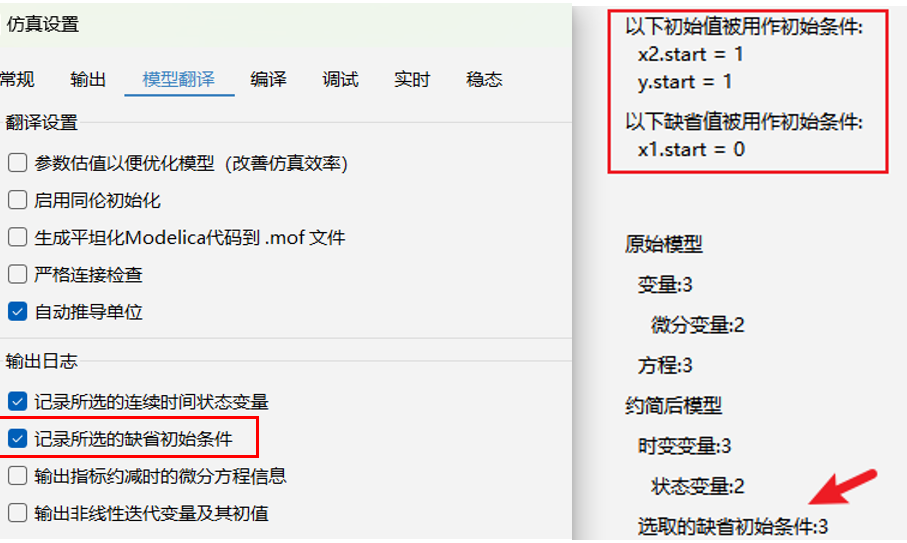
模型的初始条件影响模型初始状态的计算方式与结果,继而影响后续动态仿真的效率与质量。确定模型的初始条件是建模阶段的重要环节,建模者应认真对待。如何确定模型中需要的初始条件个数?粗略的测算方式为状态变量个数 + when 中赋值变量 + 具有 pre 变量的离散时间变量个数。建模者可通过将模型中initial equation/initial algorithm等处的内容都注释,然后翻译模型查看分析报表中选取的缺省初始条件个数,此方式可得到准确的初始条件个数,同时也可得到需要提供初始值的离散事件变量。
上述测算方式中有一项为状态变量个数,这是因为在模型初始化阶段,状态变量及其导数变量均为未知数,而状态方程 n个约束条件,故还需额外提供n个初始条件用于唯一确定x及der(x),且这n个初始条件应直接或间接与状态变量x或导数变量der(x)产生约束关系。实际应用中,模型翻译时这部分初始条件存在如下三种情况:
- 全为缺省补充的初始条件
这种情况下,模型中initial equation/initial algorithm的初始约束条件并未对状态变量及其导数产生作用,因此无法用于确定初始状态。分析程序将为每个状态变量补充缺省初始条件,若状态变量具有显式给定的start值,则x=x.start;若该状态变量无显式给定的start值,则使用实型变量默认值x=0。模型的初始状态应由建模者控制,请尽量避免由仿真工具自动补充默认 0 值的状态变量。
- 无缺省补充的初始条件
这种情况下,模型中initial equation/initial algorithm提供了充足且相容的初始约束条件用于确定初始状态。
- 存在部分缺省补充的初始条件
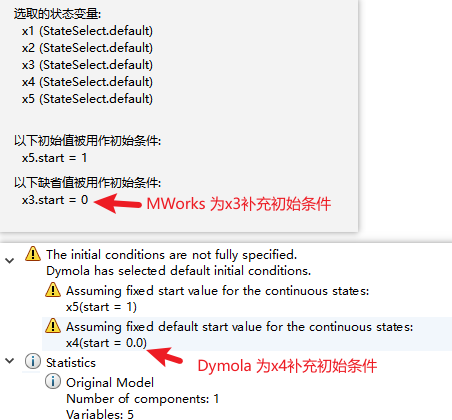
这种情况下,模型中initial equation/initial algorithm只提供了部分初始约束条件,分析程序还需补充一部分,由于不同Modelica平台或不同版本内核的补充策略不同,导致最终形成的初值系统存在差异,继而造成仿真结果的差异。目前在工程模型中这种建模缺陷普遍存在。如下例所示,初始方程区仅给定3个初始约束方程,其中方程一、二、四、五可唯一确定x1、x2及其导数变量。方程三、六、七无法唯一确定变量x3、x4及其导数变量,故分析程序需补充一个初始条件,此时可选择为x3或x4提供缺省值,这导致了不确定性。状态变量x5欠约束,故提供缺省条件x5=1。
model Case1_10
Real x1,x2; // x1与x2的初始值可唯一确定
Real x3,x4; // x3与x4缺乏初始约束,不同工具提供的缺省初始条件可能不同
Real x5(start = 1); // x5缺乏初始约束,故提供缺省初始条件x5 = 1
initial equation
x1 + 2*x2 = 1; // 方程一
der(x2) = 0; // 方程二
x3 - x4 = 1; // 方程三
equation
der(x1) = time; // 方程四
der(x2) = x2; // 方程五
der(x3) = 1; // 方程六
der(x4) = x4; // 方程七
der(x5) = 1; // 方程八
end Case1_10;
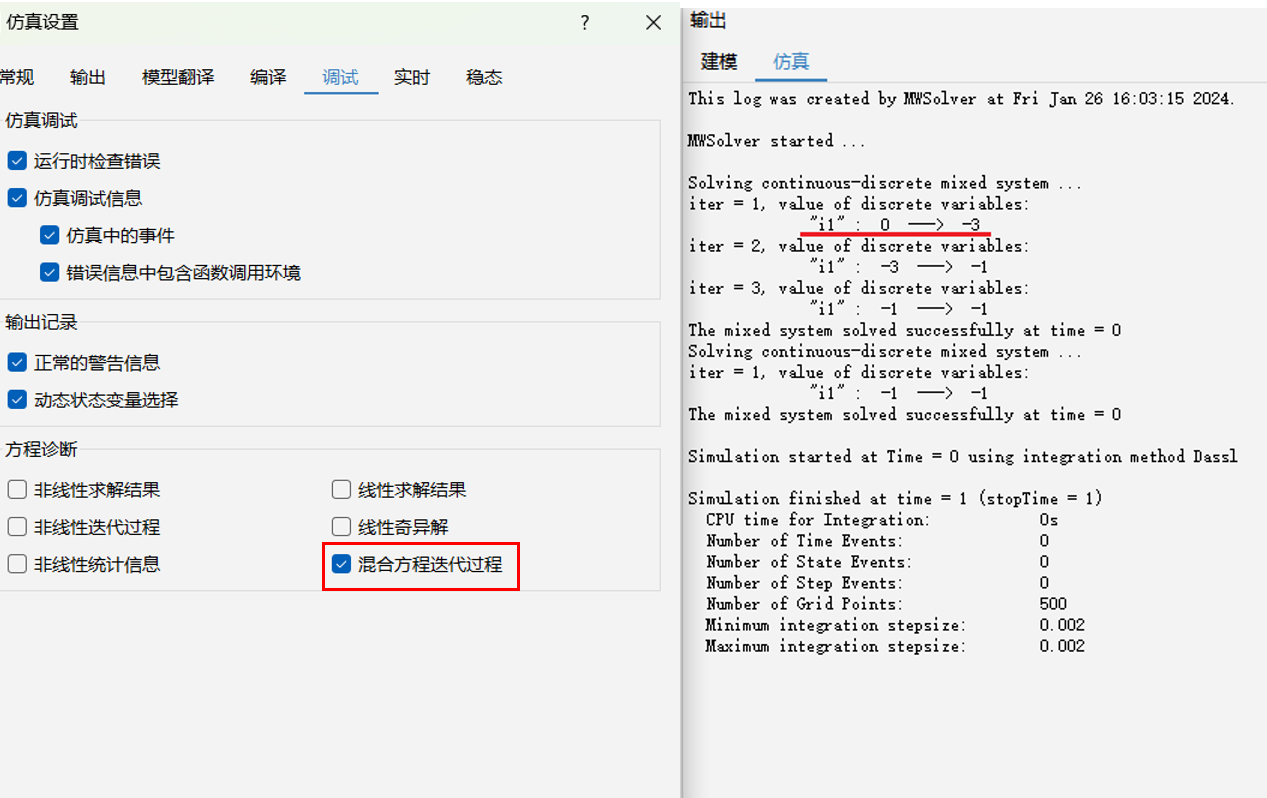
# 实型和非实型混合方程
如果实型变量和非实型变量产生了循环依赖,则包含这两类未知量的方程系统称为实型与非实型混合方程或连续离散混合方程。
model Case1_11
Real r1,r2;
Integer i1(start = 0);
equation
r1 * i1 = r2 + 0.8;
r1 - 3 * r2 = 0.4;
i1 = integer(r1 + r2);
end Case1_11;
混合方程需通过迭代方式求解,因此变量的迭代初值对求解结果与效率影响很大。为提升模型求解效率,请尽量为混合方程中每个非实型变量提供合理的 start 值。混合方程中的非实型变量可通过勾选仿真设置/调试选项卡中的“混合方程迭代过程”打印至输出面板。
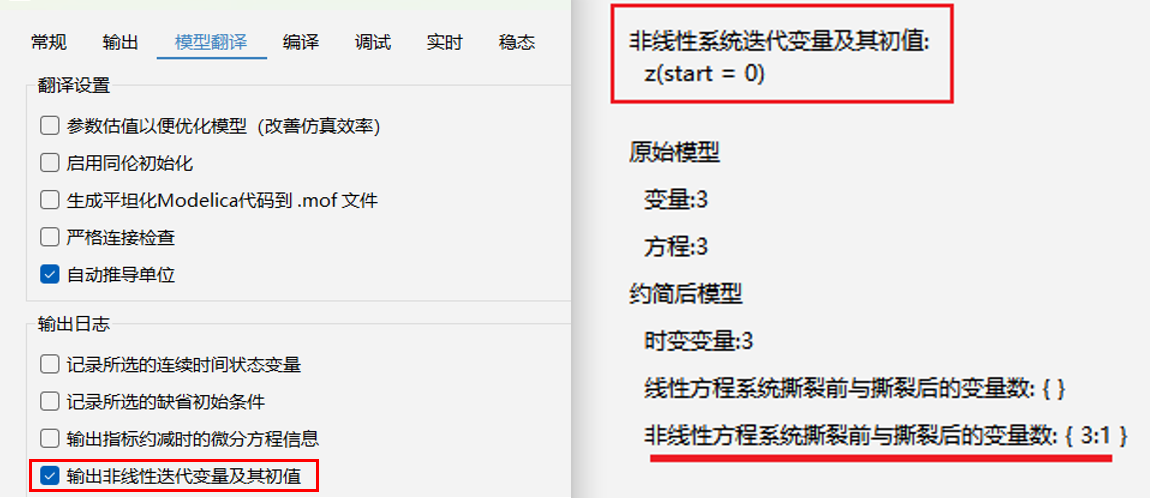
# 线性方程系统撕裂前与撕裂后的变量数
线性方程系统即线性方程组可表示成如下形式:
其中未知量
从数学意义上解释,对上述系数矩阵A做初等行列变换得到如下形式:
其中
将
进一步令
则原线性方程组就转换为计算如下
线性方程系统撕裂前与撕裂后的变量数则分别为
- 线性奇异
当系数矩阵
# 非线性方程系统撕裂前与撕裂后的变量数
非线性方程系统即非线性方程组可表示成如下形式:
其中未知量
其中
1)计算雅可比矩阵
2)估值残差函数
3)计算线性方程组;因此方程组的规模即 n 的大小直接影响模型求解效率。
与线性方程组的降阶类似,内核分析程序采用撕裂技术手段减小非线性迭代变量的规模。具体地,从向量
则原非线性方程转换为上述
撕裂后的非线性迭代过程表示如下:
非线性方程系统撕裂前与撕裂后的变量数则分别为
model Case1_12
Real y1;
Real y2;
Real z(start=0);
equation
z ^ 2 + y1 = 1;
y1 ^ 2 + y2 = 1;
y2 + z ^ 2 = 2 * sin(time) ^ 2;
end Case1_12;
- 选择非线性迭代变量
与前述DAE降指标过程中存在状态变量选取问题一样,非线性方程撕裂过程中也存在非线性迭代变量选取的情况,如下例所示:
model Case1_13
Real x;
Real y;
Real z;
equation
x = y * z + sin(time) - 2*cos(time);
x * sin(time) + y * cos(time) = 1;
z = 2 * (x^2 + y^2);
end Case1_13;
上例中,变量
同样,变量
同一组非线性方程,撕裂后选取的非线性迭代变量对非线性迭代的收敛速度有较大影响。建模者如何控制非线性迭代变量选取?为实现这项需求,2024a版本内核引入了start属性变型层级:非线性迭代初值理应是建模者根据经验提供的大致值,而不是类型默认值 0,因此那些提供了 start 值的变量则更应该被选取为非线性迭代变量。针对原始非线性方程中的变量均提供了start值的情况,进一步根据变量的 start 变型层级设置优先级,越靠近顶层的start变型优先级越高,越可能被选作为非线性迭代变量,如下例所示。
model Case1_14
// 顶层模型
model MidModel
// 中间层模型
model lowerModel
// 底层模型
Real x(start = 0); // 底层提供x的start值
Real y;
Real z;
equation
x = y * z + sin(time) - 2*cos(time);
x * sin(time) + y * cos(time) = 1;
z = 2 * (x^2 + y^2);
end lowerModel;
lowerModel LM(z(start = 1)); // 中间层提供变量z的start变型
end MidModel;
MidModel MM(LM(x(start=0))); // 顶层模型中提供x的start变型,因此x的优先级更高
// MidModel MM; // 删除顶层模型中x的start变型,变量z将被选为非线性迭代变量
// MidModel MM(LM(x(start=0),z(start=1))); // 尽管在顶层提供start,但无法同时选成x和z
end Case1_14;
建模时,可通过在顶层模型中添加变量的start变型控制最终选取的非线性迭代变量。注意,受限于符号处理能力,并不是提供了顶层start变型的变量就一定会成为非线性迭代变量,如上例中无法同时将变量 rmf文件可以获取撕裂方程中其它候选的非线性迭代变量。具体做法为:在模型翻译前,在命令窗口中设置翻译选项“MwAppOptions.SetKernelBoolOption("MWorks.Analyzer.GenerateReductionModelFile",True)”,模型翻译后可在本机设置的仿真结果目录下的临时文件夹中找到“trmodel.rmf”。
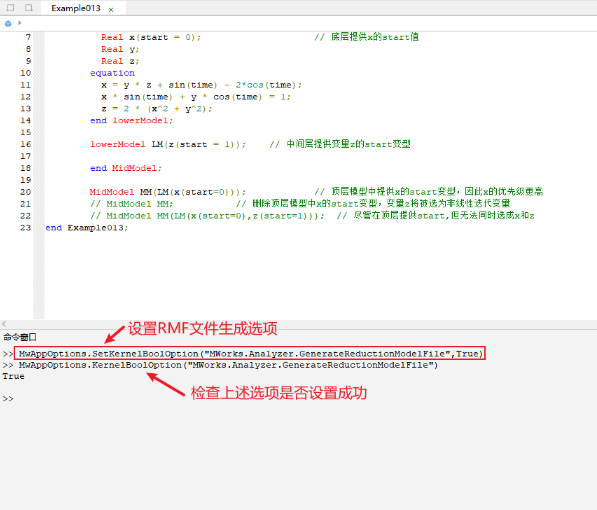
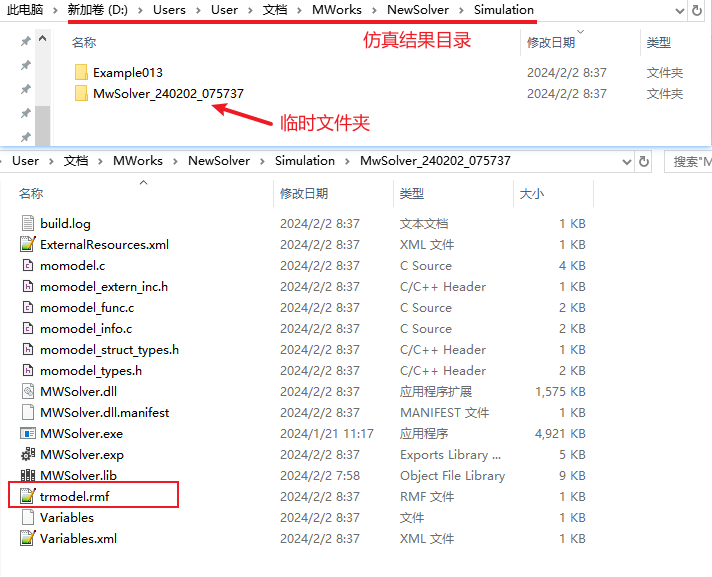
使用文本编辑器打开“trmodel.rmf”,搜索并找到目标非线性方程,在撕裂方程标签下赋值方程等式左侧变量即为候选的非线性迭代变量。
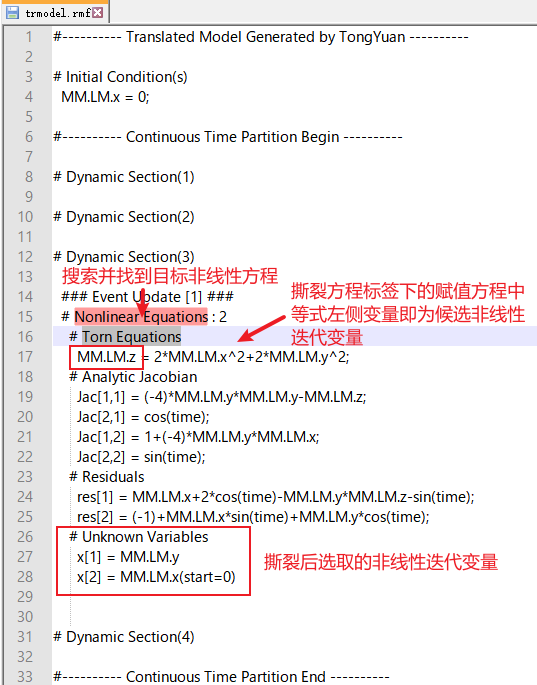
# 数值雅可比矩阵
由上一节内容可知,非线性迭代过程中需要计算雅可比矩阵
在模型分析过程中,内核分析程序采用符号求导(自动微分)技术构建非线性方程组的解析雅可比。然而,当非线性方程中存在自定义函数、外部函数或其它无法求导的复杂表达式时,符号求导会失败。这种情况下,求解器在非线性迭代时将采用数值差分的方式计算雅可比矩阵,计算精度与计算效率相比解析雅可比大幅降低。建模者应关注模型分析统计信息中数值雅可比矩阵的个数,并尝试优化原模型中不可求导的表达式,使得解析雅可比能正常生成。比较常见的不可求导的表达式,如Modelica规范中内置运算符div、mod、rem、ceil、floor等、自定义函数、外部函数等。针对非线性方程中涉及的自定义函数、外部函数等内容,一种优化方式是在函数定义时提供smoothOrder注解,使得分析工具自动推导出导函数;另一种方式是自行定义导函数,相关内容请参考Modelica规范“Declaring Derivatives of Functions”12.7 章节。
- smoothOrder
model Case1_15
function f1
input Real u1;
input Real u2;
output Real y;
algorithm
y := u1 ^ 2;
y := y + u2 ^ 2;
annotation(smoothOrder = 1); // 添加smoothOrder注解后分析工具自动生成导函数,此方式不一定可行且不适用于外部函数
end f1;
Real x(start = 0);
Real y(start = 1);
equation
f1(x, y) = 1;
x * y = sin(time) * cos(time);
end Case1_15;
- 提供自定义函数的导函数
model Case1_16
function f1
input Real u1;
input Real u2;
output Real y;
algorithm
y := u1 ^ 2;
y := y + u2 ^ 2;
annotation(derivative=f1_der); // 添加derivative注解并提供导函数
end f1;
function f1_der
input Real u1;
input Real u2;
input Real der_u1;
input Real der_u2;
output Real dy;
algorithm
dy := 2 * u1 * der_u1;
dy := dy + 2 * u2 * der_u2;
end f1_der;
Real x(start = 0);
Real y(start = 1);
equation
f1(x, y) = 1;
x * y = sin(time) * cos(time);
end Case1_16;
# 初值系统
内核分析工具将原始的连续离散混合DAE模型约减为一系列赋值方程、代数方程以及常微分方程表示的模型约束方程,可简单表示为如下多输出函数形式:
其中 initial equation/initial algorithm/when initial等方式引入约束条件,否则内核分析工具将补充缺省初始条件)。因此,通过分析initial equation/initial algorithm/when initial等处提供的初始约束条件以及上述模型约束方程而形成的用于解算上述
通常情况下,fixed属性设为false,则表示该参量需要在初始化经由其它已知量确定,如下例所示:
model Case1_17
// 通过单摆初始位置确定摆长值
Real x; // 单摆端点x坐标
Real y; // 单摆端点y坐标
Real v; // 单摆端点垂直速度分量
Real u(start = 0); // 单摆端点水平速度分量
Real F; // 单摆铰接点受力
parameter Real m = 1;
parameter Real l(fixed=false); // 未知参量摆长
initial equation
x = 0.8; // 提供单摆初始位置条件
y = 0.6;
equation
der(x) = u;
der(y) = v;
m * der(v) = -m * 9.81 - F * y / l;
m * der(u) = -F * x / l;
x * x + y * y = l ^ 2; // 结合此模型约束方程可确定摆长l
end Case1_17;
如果通过start值或initial equation等方式直接给出上述
model Case1_18
Real x;
Real y;
initial equation
der(x) = 1; // 此初始约束条件导致初值系统中存在非线性方程组,增加了初始化解算难度
der(y) = 0;
equation
der(x) = x^2 + y^2;
der(y) = x * y;
end Case1_18;
# 小结
本文对MWORKS.Sysporer翻译Modelica模型后得到的模型统计信息进行了较为详细的介绍,通过了解上述模型信息的由来与含义,有助于工程建模人员进一步优化模型组件与系统。如果对本文中所提到的分析技术或数值求解感兴趣,可进一步参考如下文献资料:
[1] 周凡利. 工程系统多领域统一模型编译映射与仿真求解研究[D]
[2] 丁建完. 陈述式仿真模型相容性分析与约简方法研究[D]
[3] Cellier F, Kofman E. Continuous system simulation[M]
[4] Mattsson S E. Index reduction in differential-algebraic equation using dummy derivatives[J]
[5] Gene H G. 矩阵计算[M] (袁亚湘译)
[6] MJD Powell. A Fortran subroutine for solving systems of nonlinear algebraic equations[J]
[7] E. Hairer, G.Wanner Solving Ordinary Differential Equations I Nonstiff Problems[M]
[8] KE Brenan, LR Petzold. Numerical solution of initial-value problems in differential-algebraic equations[M]