2026a
# 最大似然估计
mle 函数用于计算由其名称指定的分布以及由其概率密度函数 (pdf)、对数 pdf 或负对数似然函数指定的自定义分布的最大似然估计 (MLE)。
对于某些分布,MLE 可以用闭式形式直接给出并计算。对于其他分布,则必须进行最大似然搜索。可以使用 statset 函数创建的 options 输入参数来控制搜索。为了实现高效搜索,选择合理的分布模型并设置适当的收敛容差非常重要。
MLE 可能存在偏差,尤其是样本较小时。然而,随着样本量的增加,MLE 会成为无偏最小方差估计器,且近似服从正态分布。这可用于计算估计值的置信界限。
例如,考虑从指数分布重复随机抽样得到的均值分布如下:
using TyPlot
using TyStatistics
using TyMath
mu = 1; #Population parameter
n = convert(Int, 1e3); #Sample size
ns = convert(Int, 1e4); #Number of samples
rng = MT19937ar(5489) #For reproducibility
samples = exprnd(rng,mu,n,ns); #Population samples
means = mean(samples,1);
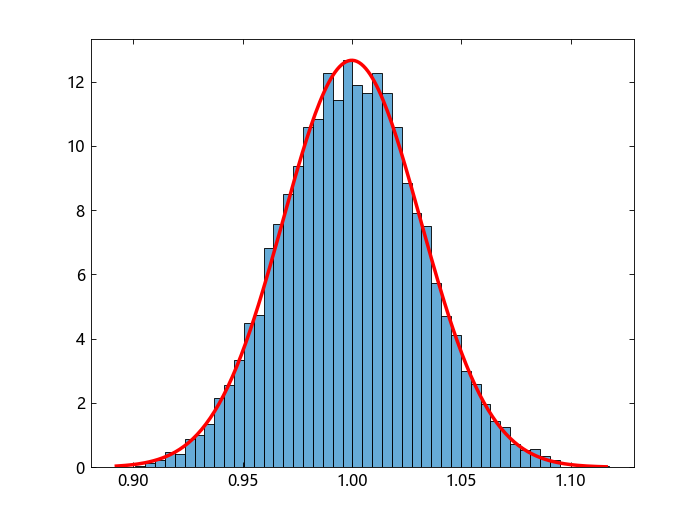
中心极限定理指出,无论样本数据的分布如何,样本均值将近似服从正态分布。可以使用 mle 函数来找到最适合这些均值的正态分布:
phat,pci = mle(means)
phat =
2-element Vector{Float64}:
0.9999824266987857
0.031497118395843314
pci =
2×2 Matrix{Float64}:
0.999365 0.0310681
1.0006 0.0319414
phat(1) 和 phat(2) 是均值和标准差的最大似然估计(MLE)。pci(:,1) 和 pci(:,2) 是相应的 95% 置信区间。
将样本均值的分布与拟合的正态分布一起可视化。
numbins = 50;
histogram(means,numbins,normalization = "pdf")
hold("on")
x = range(minimum(means),maximum(means),step = 0.001);
y = normpdf(x,phat[1],phat[2]);
plot(x,y,color = "r",linewidth = 2)