# 使用等级相关性生成相关数据
此示例展示了如何使用关联函数和等级相关来从未提供逆累积分布函数的概率分布(例如皮尔逊灵活分布族)生成相关数据。
# 生成皮尔逊随机数
使用 pearsrnd 函数从两个不同的 Pearson 分布中生成 1000 个随机数。第一个分布的参数值为:均值(mu)为 0,标准差(sigma)为 1,偏度(skew)为 1,峰度(kurtosis)为 4。第二个分布的参数值为:均值(mu)为 0,标准差(sigma)为 1,偏度(skew)为 0.75,峰度(kurtosis)为 3。
using TyStatistics
using TyMath
using TyPlot
using TyBase
rng = MT19937ar(5489)
p1, = pearsrnd(rng, 0, 1, -1, 4, 1000, 1)
p2, = pearsrnd(rng, 0, 1, 0.75, 3, 1000, 1)
在这个阶段,p1 和 p2 是各自 Pearson 分布的独立样本,并且彼此不相关。
# 绘制皮尔逊随机数
创建一个散点直方图 scatterhist 以可视化 Pearson 随机数。
figure()
scatterhist(p1, p2)
xlabel("p1")
ylabel("p2")
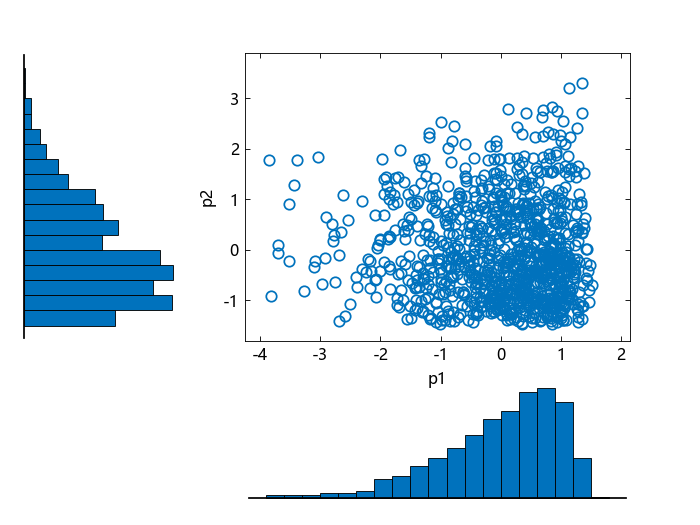
直方图显示了 p1 和 p2 的边际分布。散点图显示了 p1 和 p2 的联合分布。散点图中缺乏模式表明 p1 和 p2 是独立的。
# 使用高斯 Copula 生成随机数
使用 copularnd 生成 1000 个相关随机数,相关系数为 -0.8,采用高斯 copula。创建一个散点直方图(scatterhist)来可视化从 copula 生成的随机数。
u = copularnd(rng, "Gaussian", -0.8, 1000)
figure()
scatterhist(u[:, 1], u[:, 2])
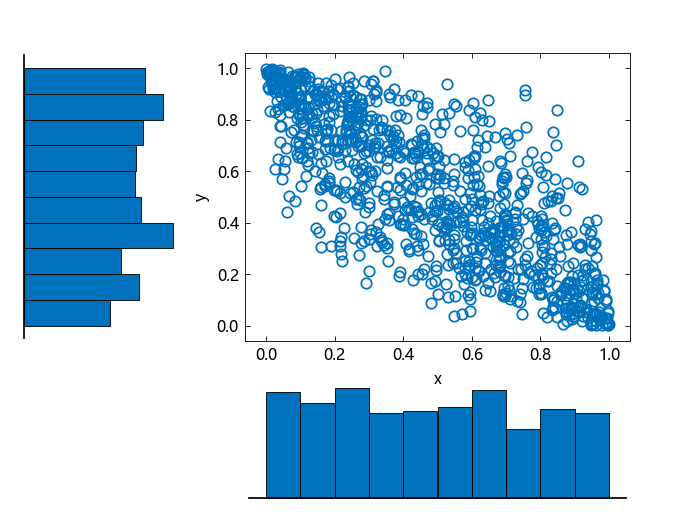
直方图显示,每一列的联合分布数据具有边际均匀分布。散点图显示,两列数据呈负相关。
# 对 copula 随机数进行排序
使用斯皮尔曼秩相关,将两个独立的皮尔逊样本转换为相关数据。使用 ty_sort 函数将 copula 随机数从小到大排序,并返回描述数字重新排列顺序的索引向量。
s1, i1 = ty_sort(u[:,1]; nargout=2)
s2, i2 = ty_sort(u[:,2]; nargout=2)
s1 和 s2 包含联合分布中第一列和第二列的数字 u,这些数字按从小到大的顺序排列。i1 和 i2 是索引向量,用于描述将元素重新排列成 s1 和 s2 的顺序。例如,如果排序后的向量 s1 的第一个值是原始未排序向量的第三个值,那么索引向量 i1 的第一个值就是 3。
# 使用Spearman秩相关转换Pearson样本
创建两个零向量 x1 和 x2,它们与已排序的 copula 向量 s1 和 s2 大小相同。将 p1 和 p2 中的值从小到大排序。按照使用 copula 随机数排序生成的索引 i1 和 i2 的顺序,将这些值放入 x1 和 x2 中。
x1 = zeros(size(s1))
x2 = zeros(size(s2))
x1[i1] = ty_sort(p1)
x2[i2] = ty_sort(p2)
# 绘制相关的皮尔逊随机数
创建一个散点直方图以可视化相关的皮尔逊数据。
figure()
scatterhist(x1, x2)
xlabel("x1")
ylabel("x2")
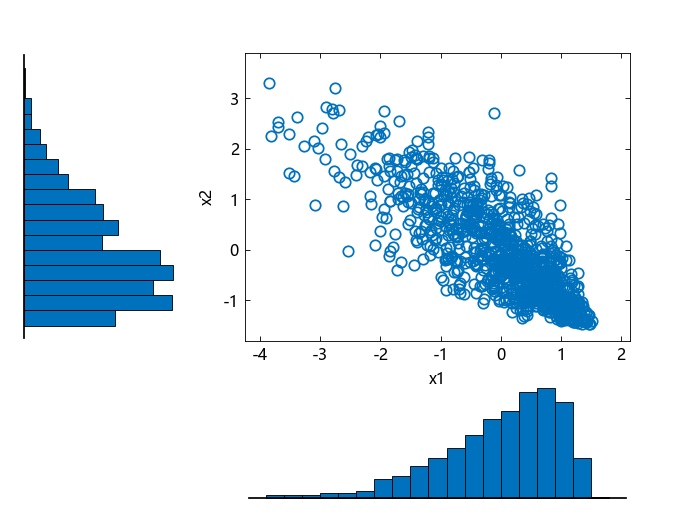
直方图显示了每列数据的边际皮尔逊分布。散点图显示了 p1 和 p2 的联合分布,并表明数据现在呈现负相关。
# 确认斯皮尔曼等级相关系数值
确认 Spearman 秩相关系数对于 copula 随机数和相关的 Pearson 随机数是相同的。
copula_corr = corr(u; Type="spearman")[1]
copula_corr =
2×2 Matrix{Float64}:
1.0 -0.785787
-0.785787 1.0
pearson_corr = corr([x1 x2]; Type="spearman")[1]
copula_corr =
2×2 Matrix{Float64}:
1.0 -0.785787
-0.785787 1.0
Spearman 等级相关系数对于 Copula 和 Pearson 随机数是相同的。