# 使用软聚类对高斯混合数据进行聚类
这个示例展示了如何在来自高斯分布混合的模拟数据上实现软聚类。
cluster 估计聚类成员的后验概率,然后将每个点分配到对应最大后验概率的聚类中。软聚类是一种替代的聚类方法,它允许某些数据点属于多个聚类。实现软聚类的方法如下:
- 为每个数据点分配一个簇成员评分,用于描述每个点与每个簇原型的相似程度。对于高斯分布的混合,每个簇的原型对应于相应的组件均值,该组件可以是估计的簇成员后验概率。
- 根据聚类成员得分对点进行排序。
- 检查分数并确定聚类成员资格。
对于使用后验概率作为评分的算法,一个数据点属于与最大后验概率对应的簇。然而,如果存在其他簇的后验概率接近最大值,那么该数据点也可以属于这些簇。在聚类之前,最好先确定产生多个簇成员资格的评分阈值,这是一种良好的做法。
这个示例源自 使用硬聚类对高斯混合数据进行聚类。
从两个二维高斯分布的混合中模拟数据。
using TyStatistics
using TyMath
using TyPlot
using TyBase
rng = MT19937ar(5489)
mu1 = [1 2]
sigma1 = [3 0.2; 0.2 2]
mu2 = [-1 -2]
sigma2 = [2 0; 0 1]
X = [mvnrnd(rng, mu1, sigma1, 200)[1]; mvnrnd(rng, mu2, sigma2, 100)[1]]
拟合一个两组件高斯混合模型 (GMM)。由于有两个组件,假设任何后验概率在 [0.4,0.6] 区间内的聚类成员的数据点可以同时属于两个聚类。
gm = fitgmdist(X, 2; randseed=rng)
threshold = [0.4 0.6]
使用拟合的高斯混合模型(GMM)gm 估计所有数据点的成分成员后验概率。这些表示簇成员得分。
P, = posterior(gm, X)
对于每个簇,对所有数据点的隶属度得分进行排名。对于每个簇,绘制每个数据点的隶属度得分,并相对于所有其他数据点的排名显示。
n = size(X, 1)
_, order = ty_sort(P[:, 1]; nargout=2)
figure()
plot(1:n, P[order, 1], "r-", 1:n, P[order, 2], "b-")
legend(["Cluster 1", "Cluster 2"])
ylabel("Cluster Membership Score")
xlabel("Point Ranking")
title("GMM with Full Unshared Covariances")
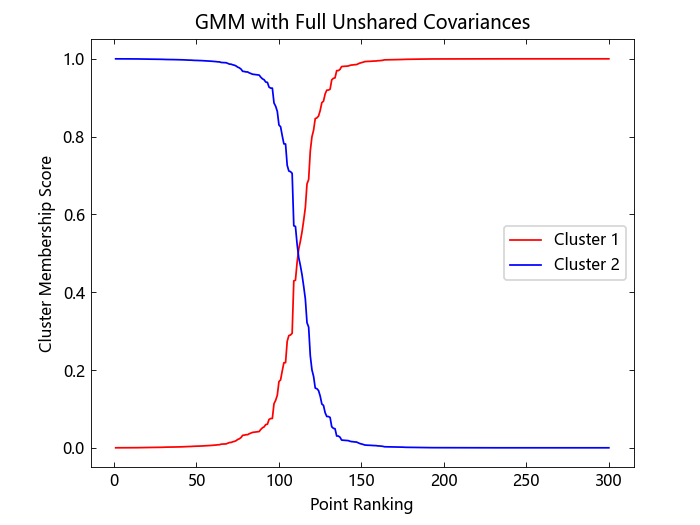
虽然在数据的散点图中很难看出明显的分离,但绘制隶属度分数表明,拟合的分布在将数据分组时做得很好。
绘制数据并按最大后验概率分配簇。识别可能属于任一簇的点。
idx, = cluster(gm, X)
idxBoth = find((P[:, 1] .>= threshold[1]) .& (P[:, 1] .<= threshold[2]))
numInBoth = length(idxBoth)
numInBoth =
7
figure()
gscatter(X[:, 1], X[:, 2], idx, "rb", "+o", 5)
hold("on")
plot(X[idxBoth, 1], X[idxBoth, 2], "ko"; markersize=10)
legend(["Cluster 1", "Cluster 2", "Both Clusters"]; loc="southeast")
title("Scatter Plot - GMM with Full Unshared Covariances")
hold("off")
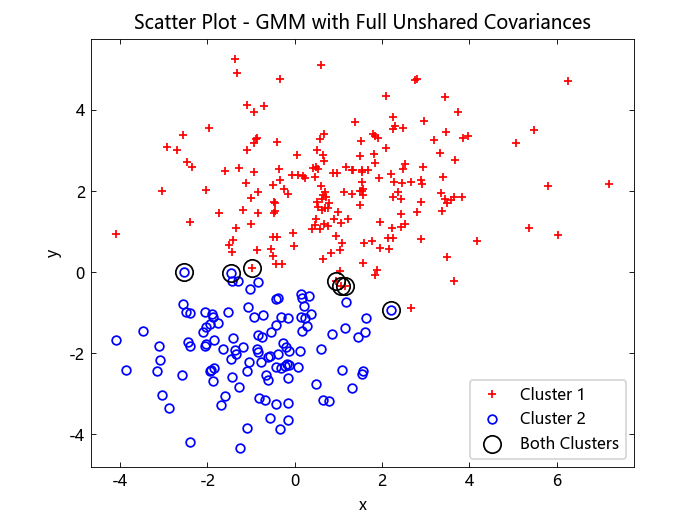 使用分数阈值区间,七个数据点可以在任一簇中。
使用分数阈值区间,七个数据点可以在任一簇中。
使用高斯混合模型(GMM)进行软聚类类似于模糊 k 均值聚类,后者也为每个点分配一个属于各个簇的隶属度分数。模糊 k 均值算法假设簇大致呈球形,并且大小大致相等。这可类比于具有单一协方差矩阵的高斯混合分布,该协方差矩阵在所有成分中共享,并且是单位矩阵的倍数。相比之下,gmdistribution 允许你指定不同的协方差结构。默认情况下,为每个成分估计一个独立的、无约束的协方差矩阵。一种更受限制的选项,更接近 k 均值,是估计一个共享的对角协方差矩阵。
将高斯混合模型 (GMM) 拟合到数据,但指定各分量共享相同的对角协方差矩阵。这种指定方式类似于实现模糊 k 均值聚类,但通过允许不同变量具有不等方差提供了更多的灵活性。
gmSharedDiag = fitgmdist(X, 2; covariancetype="Diagonal", sharedcovariance=true)
使用拟合的 GMM gmSharedDiag 估计所有数据点的组件成员后验概率。估计软聚类分配。
idxSharedDiag, _, PSharedDiag = cluster(gmSharedDiag, X)
idxBothSharedDiag = find(
(PSharedDiag[:, 1] .>= threshold[1]) .& (PSharedDiag[:, 1] .<= threshold[2])
)
numInBoth = length(idxBothSharedDiag)
numInBoth =
5
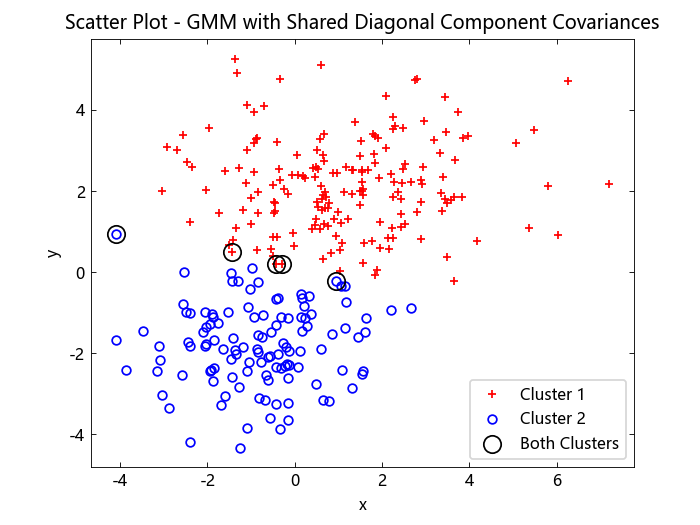
假设各成分之间具有共享的对角协方差,五个数据点可以属于任一簇。
对于每个集群:
- 对所有数据点的隶属度分数进行排序。
- 绘制每个数据点的隶属度分数,相对于所有其他数据点的排名。
_, orderSharedDiag = ty_sort(PSharedDiag[:, 1]; nargout=2)
figure()
plot(1:n, PSharedDiag[orderSharedDiag, 1], "r-", 1:n, PSharedDiag[orderSharedDiag, 2], "b-")
legend(["Cluster 1" "Cluster 2"]; loc="northeast")
ylabel("Cluster Membership Score")
xlabel("Point Ranking")
title("GMM with Shared Diagonal Component Covariances")
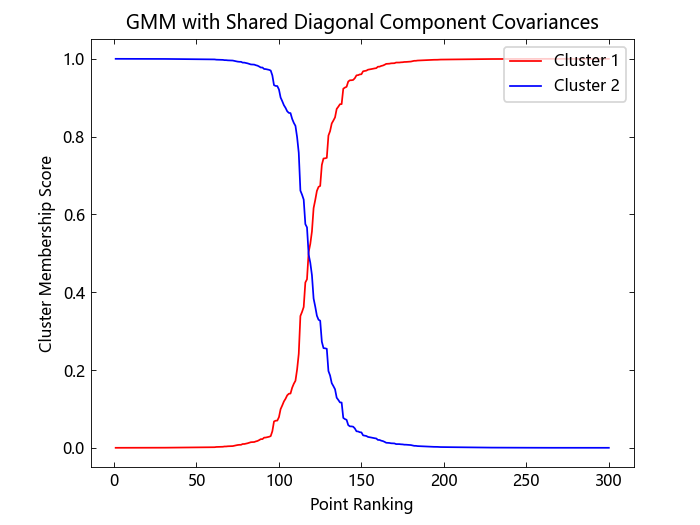
绘制数据,并根据假设各成分具有共享的对角协方差的高斯混合模型 (GMM) 分析,识别硬聚类分配。同时,确定那些可能属于任意一个簇的数据点。
figure()
gscatter(X[:, 1], X[:, 2], idxSharedDiag, "rb", "+o", 5)
hold("on")
plot(X[idxBothSharedDiag, 1], X[idxBothSharedDiag, 2], "ko"; markersize=10)
legend(["Cluster 1", "Cluster 2", "Both Clusters"]; loc="southeast")
title("Scatter Plot - GMM with Shared Diagonal Component Covariances")
hold("off")
# 另请参阅
fitgmist | gmdistribution | cluster