2026a
# 数据的探索性分析
此示例说明了如何使用描述性统计来探索数据的分布。
# 生成示例数据
生成一个包含随机生成样本数据的向量。
using TyMath
using TyPlot
using TyRandom
using TyStatistics
rng = MT19937ar(5489)
x = vcat(normrnd(rng,4,1,100),normrnd(rng,6,0.5,200))
# 绘制直方图
绘制样本数据的直方图,并拟合正态密度。这可以直观地比较样本数据与拟合到数据的正态分布。
histfit(x)
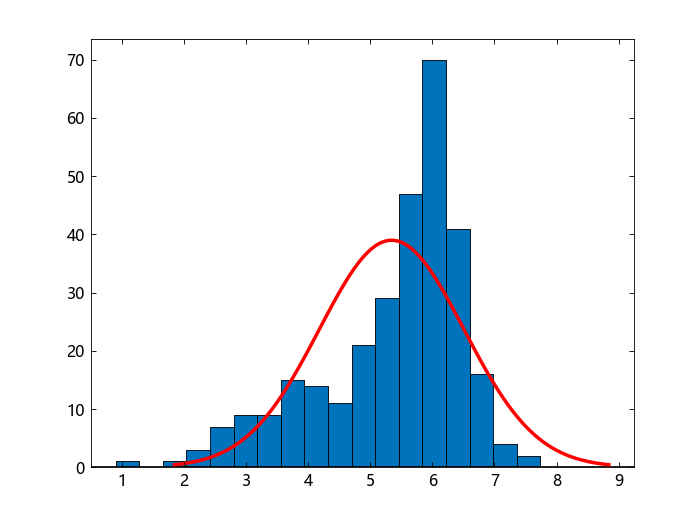
数据的分布似乎是左偏的。正态分布似乎并不适合这组样本数据。
# 获取正态概率图
获取一个正态概率图。该图提供了一种额外的方法,用于直观评估样本数据与拟合到数据的正态分布之间的比较。
figure();
normplot(x)
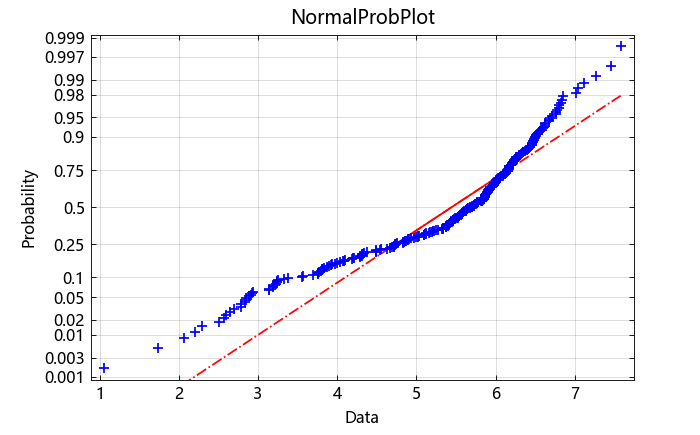
概率图还显示了数据偏离正态分布的情况。
# 创建箱线图
创建一个箱线图来可视化统计数据。
boxplot(x)
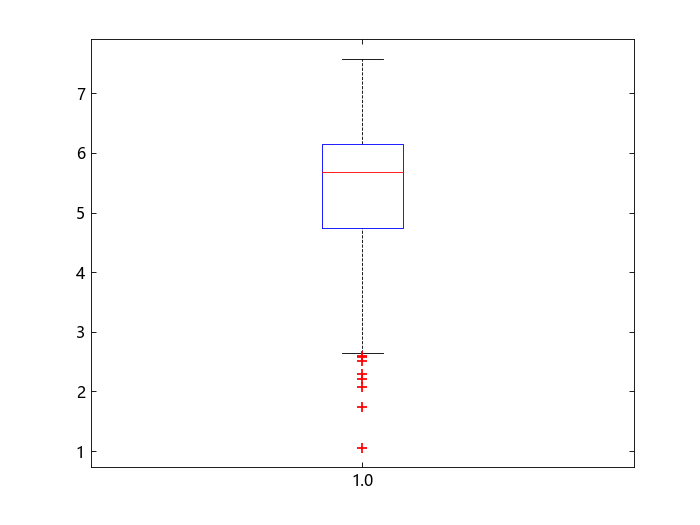
箱线图显示了 0.25、0.5 和 0.75 分位数。长的下尾和加号显示了样本数据值的不对称性。
# 计算描述性统计
计算数据的平均值和中位数。
y = [mean(x),median(x)]
2-element Vector{Float64}:
5.343782652113257
5.6871914253171285
均值和中位数似乎彼此接近,但均值小于中位数通常表明数据呈左偏。计算数据的偏度和峰度。
y = [skewness(x),kurtosis(x)[1]]
2-element Vector{Float64}:
-1.0416739871489953
3.589496772170759
负偏度值意味着数据呈左偏。由于峰度值大于 3,数据的尖峰程度比正态分布更高。
# 计算 z 分数
通过计算 z 分数并找出大于 3 或小于 -3 的值来识别可能的异常值。
Z = zscore(x)[1]
findall(abs.(Z) .> 3)
2-element Vector{Int64}:
3
35
根据 z 分数,第 3 和第 35 个观测值可能是异常值。