# 并行概述
并行计算工具箱的目标是为了帮助用户快速的实现并行计算,提高计算效率。
# 简介
并行计算工具箱目前包含了四种并行计算的典型模式,分别是异步、多线程、多进程和 GPU 计算。 对于每一种典型模式,工具箱都提供了一个快速入门的教程,帮助用户快速的了解并行计算的基本概念和使用方法。 这些快速入门教程针对的是初学并行计算的用户,因此不需要用户有任何并行计算的经验,只需要有一定的编程基础即可。 尽管如此,那些有其他语言并行计算经验的用户也可以从中获得一些有用的信息。
提示
我们推荐用户首先阅读异步快速入门教程, 因为异步是并行计算的基础,而且异步的编程模式也是并行计算工具箱的核心。 然后可以根据自己的需求选择多线程快速入门或多进程快速入门教程。
如果用户需要在 GPU 上进行并行计算,那么可以直接阅读 GPU 计算快速入门教程:它在一定程度上与异步、多线程和多进程是独立的。
| 类别 | 简介 |
|---|---|
| 异步快速入门 | 任务创建和异步调用执行以及任务间通信机制 |
| 多线程快速入门 | 多线程环境创建,并行 for 循环和并行任务之性能 |
| 多进程快速入门 | 包括多进程环境创建,使用多进程计算 |
| GPU 计算快速入门 | 包括 GPU 计算环境创建,GPU 设备识别和选择,GPU 向量化加速 |
# 示例
这里列举了一些与并行计算有关的一些实际应用的示例,用于帮助读者理解并行计算的概念并在实际应用中使用。这些示例被按照两种方式组织:
- 经典的并行计算范式和算法: 这些算法在各种并行设备上都可以很容易地给出一个较为简单的实现,因此可以作为学习并行计算的入门示例;
- 进阶示例:这些示例的目的是为了介绍不同并行模式的特性,以及如何在这些设备上实现并行计算。
对于初次了解并行计算的用户,推荐将经典示例作为学习的入门示例;而对于已经有一定并行计算经验的用户,可以直接阅读感兴趣的示例。
# 经典范式
| 示例 | 多线程实现 | 多进程实现 | GPU 计算实现 |
|---|---|---|---|
| 矩阵加法 | 矩阵加法的多线程计算实现 | 矩阵加法的多进程计算实现 | 矩阵加法的 GPU 计算实现 |
| Global-Sum 求和 | Global-Sum 求和的多线程计算实现 | Global-Sum 求和的多进程计算实现 | Global-Sum 求和的 GPU 计算实现 |
| Collatz 猜想 | Collatz 猜想的多线程计算实现 | Collatz 猜想的多进程计算实现 | Collatz 猜想的 GPU 计算实现 |
| 蒙特卡洛方法计算 π | 蒙特卡洛方法计算 π 的多线程计算实现 | 蒙特卡洛方法计算 π 的多进程计算实现 | 蒙特卡洛方法计算 π 的 GPU 计算实现 |
| Prefix-Sum 求和 | Prefix-Sum 求和的多线程计算实现 | Prefix-Sum 求和的多进程计算实现 | Prefix-Sum 求和的 GPU 计算实现 |
# 更多示例
这一部分示例属于进阶内容:它用于演示特定并行模式的特性与典型用法。每个示例本身是相对独立的因此可以按照任意顺序阅读。
| 示例 | 类型 |
|---|---|
| 异步生产者消费者示例 | 异步 |
| GPU 多方法计算 MandelBrot 集 | GPU 计算 |
| 异步 UDP 通信 | 异步 + 多线程 |
| GPU 上 FFT 模拟衍射 | GPU 计算 |
# 进阶话题
这些话题是为那些已经熟悉初步了解了 Julia 并行计算的用户所准备的:通过阅读这些话题可以更深入地了解并行计算的原理与高阶用法。
| 示例 | 分类 | 说明 |
|---|---|---|
| SIMD | SIMD | 关于使用 SIMD 进行加速 |
| 多线程数据竞争 | 线程并行 | 关于多线程下的数据竞争问题 |
| GPU 标量迭代 | GPU 计算 | 关于 GPU 下避免标量迭代 |
| 指定线程数执行 | 多线程计算 | 关于指定数量线程数执行 |
| 基于 SSH 的分布式计算 | 分布式计算 | 基于 SSH 的分布式计算 |
# 并行计算环境配置
# 多线程环境
注意
在 Julia 已经开启的情况下,无法动态调整线程数。此时必须重启 Julia 才能设置线程。
在 Syslab 中, 用户可以通过首选项设置来指定 Julia 进程启动时的线程数。
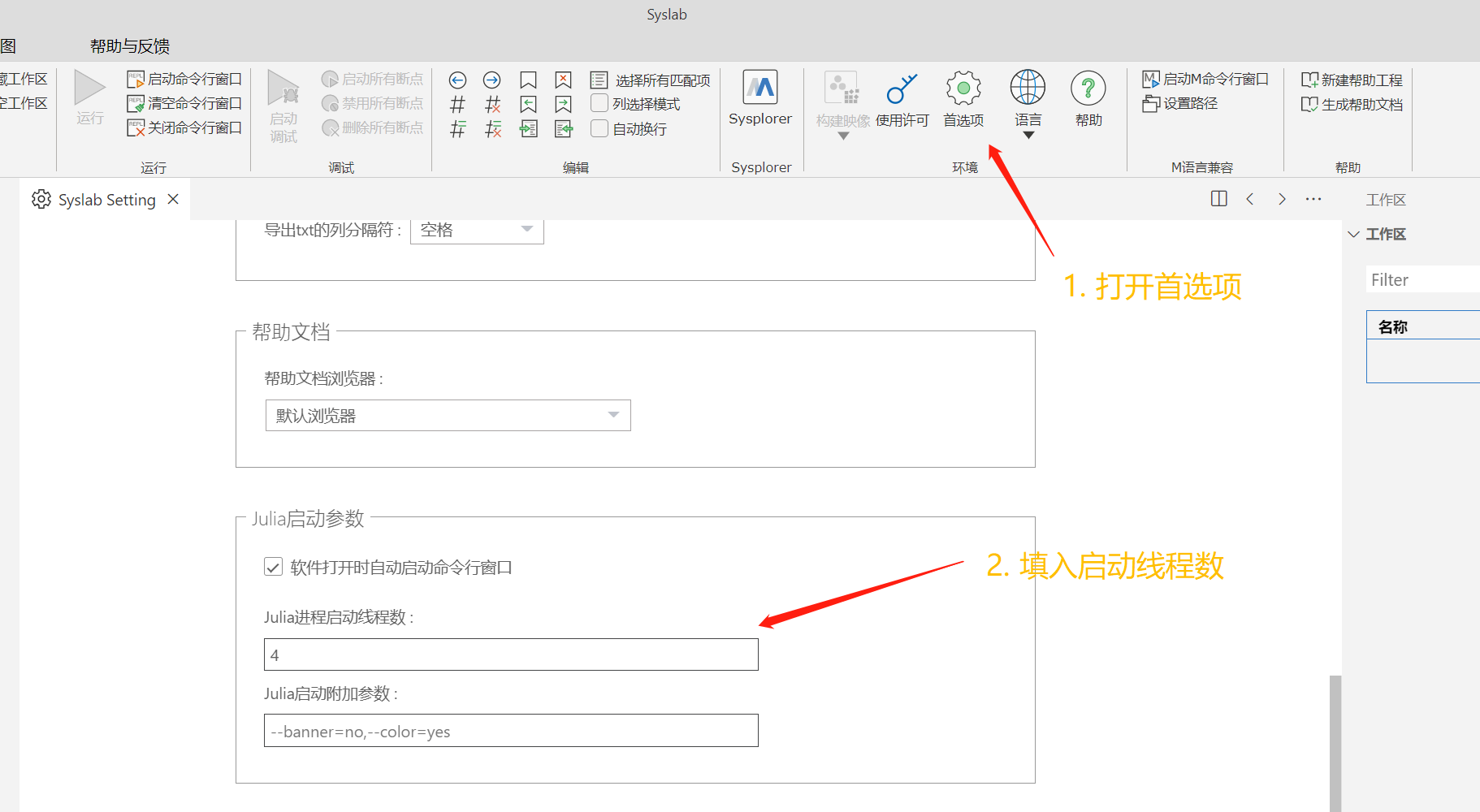
然后在 Julia 进程中通过 using Base.Threads 加载多线程模块。
这背后实际上是调用了 julia -t 4 来启动 Julia 进程,其中 -t 4 指定了线程数为 4。
提示
Julia 的 -t 参数允许设置整数作为线程数,但是这个参数只能在 Julia 启动时设置。
可以设置的线程数并不一定是 CPU 实际的核心数,例如:用户完全可以在一台 4 核心的 CPU 上启动 32 个 Julia 线程。
除此之外,也可以通过 julia -t auto 来自动设置线程数,这样 Julia 会自动设置线程数为 CPU 的核心数。
除此之外,用户也可以设置环境变量 JULIA_NUM_THREADS 来指定 Julia 进程的线程数。 它与使用 -t 参数的效果是一致的。
# 多进程环境
不同于多线程,在 Syslab 中可以通过 addprocs 动态添加进程数目:
using Distributed
# 新增 4 个工作进程
addprocs(4)
通过 workers 函数查看当前 Julia 进程的工作进程:
workers()
4-element Vector{Int64}:
2
3
4
5
这样就在 Julia 进程中新增了 4 个工作进程。
若要减少工作进程,可以使用 rmprocs 函数:
rmprocs(3)
这样就移除了 3 号工作进程:
workers()
3-element Vector{Int64}:
2
4
5
除此之外,也可以像多线程一样,通过 -p 参数来指定 Julia 启动时的工作进程数,如在终端中通过 julia -p 4 启动 Julia
即可得到:
using Distributed
workers()
4-element Vector{Int64}:
2
3
4
5
# GPU 计算环境
提示
目前 GPU 计算需要以下支持 Nvidia GPU 硬件支持,如果无 Nvidia GPU 暂时不支持 GPU 计算。 关于 Nvidia 硬件的支持情况可以查阅 Nvidia 官方指南 CUDA GPUs (opens new window) 获得更多信息。 为了更好的计算体验,推荐使用支持计算能力版本(Compute Capability) 7.5 及以上的 GPU 设备,如 GTX 3000 系列。
CUDA.jl 是 Julia 社区提供的工具箱,它支持将 Julia 代码编译到 NVIDIA GPU 设备上,从而实现高性能 GPU 计算。由于体积原因,目前 Syslab 安装程序不包含 CUDA 相关资源,你需要手动安装 CUDA.jl 包。
在 Julia 进程中运行:
using Pkg
Pkg.add(PackageSpec(name="CUDA", version="3"))
安装完毕后,在 Julia 进程中通过 CUDA.functional 判断 GPU 计算是否可以正常运行:
CUDA.functional(true)
如果 GPU 环境正确安装且有可用的 NVIDIA 显卡,会返回:
true
以及通过 CUDA.versioninfo 查看 CUDA 版本信息。
提示
首次使用 CUDA.jl 时还会自动下载 NVIDIA CUDA 运行时。请确保有一个良好的网络环境。
对于离线环境,或者希望能够使用本地安装的 CUDA,可以进一步阅读离线环境配置 NVIDIA GPU 计算的相关说明。