# 并行计算工具箱
# 高性能计算
在科学计算或系统建模仿真领域存在两类典型的使用场景:建模场景与部署场景。 Julia 语言的设计目标是同时满足这两类场景的需求,这也是 Syslab 选择 Julia 作为首选编程语言的原因。
| 场景 | 说明 | 需求 |
|---|---|---|
| 建模场景 | 对模型进行验证、调整的快速迭代阶段 | 交互式编程、低延迟、易于调试 |
| 部署场景 | 对模型进行长时间的计算,以便于得到最终的结果 | 高性能、高吞吐量、高可靠性 |
在大众编程世界中,大多数对高性能计算没有经验的用户或开发者往往对于性能优化会产生一些偏见。 例如:“算法的选择比编程语言的选择更重要”、“编译器会自动优化代码”、“使用多线程就能提升性能”、等等。 这些观点本身并没有错,但是它们都存在一些前提条件,而这些前提条件往往被忽略了。 本文档的目的除了介绍 Julia 语言的高性能计算特性之外,还希望能够帮助读者建立正确的性能优化观念, 从而避免一些常见的性能优化误区。
在实际生产实践中,实现高性能计算的常见手段主要有:
- 对于普适性强的高价值算法,通过专用芯片的方式给出固化实现。 手机摄像头中包含的图像处理芯片就属于这一类,但由于这类芯片的研发周期和制造成本非常高昂,只有特定的少数算法才有硬件优化的必要性和价值。
- 对于一般性算法,通过优化算法、数据结构以及代码实现,来获得单核 CPU 上的优化实现。大部分的基础算法属于这一类。
- 对于可并行化的算法,通过多线程、多进程甚至专用并行芯片的方式,尽可能多地调度更多的计算资源。大规模仿真、AI深度学习往往属于这一类。
本文档将介绍最后这种手段的相关内容。更具体地说,本文档将覆盖以下四个主要板块:
- 异步计算
- 多线程计算
- 多进程计算
- GPU及异构计算
# 什么是并行计算
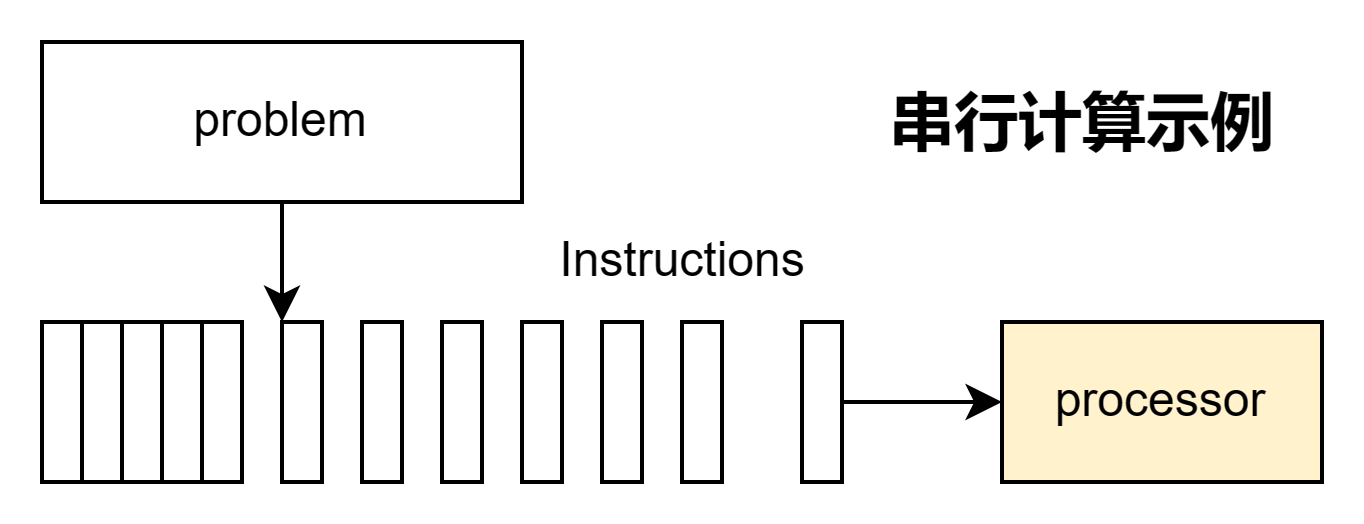
传统上,软件是围绕串行计算逻辑编写的,它的特点在于:
- 问题被分解为一系列离散的指令
- 指令按顺序一个接一个地执行
- 在单个处理器上执行
- 任何时候只能执行一条指令
不同于串行计算逻辑,并行计算假设多个计算资源的存在。 当存在多个计算资源的时候,任务就可以同时进行:
- 问题被分解为可以同时解决的离散部分
- 每个部分被进一步分解为一系列指令
- 每个部分的指令在不同的处理器上同时执行
- 采用总体上的控制/协调机制来同步与更新执行结果
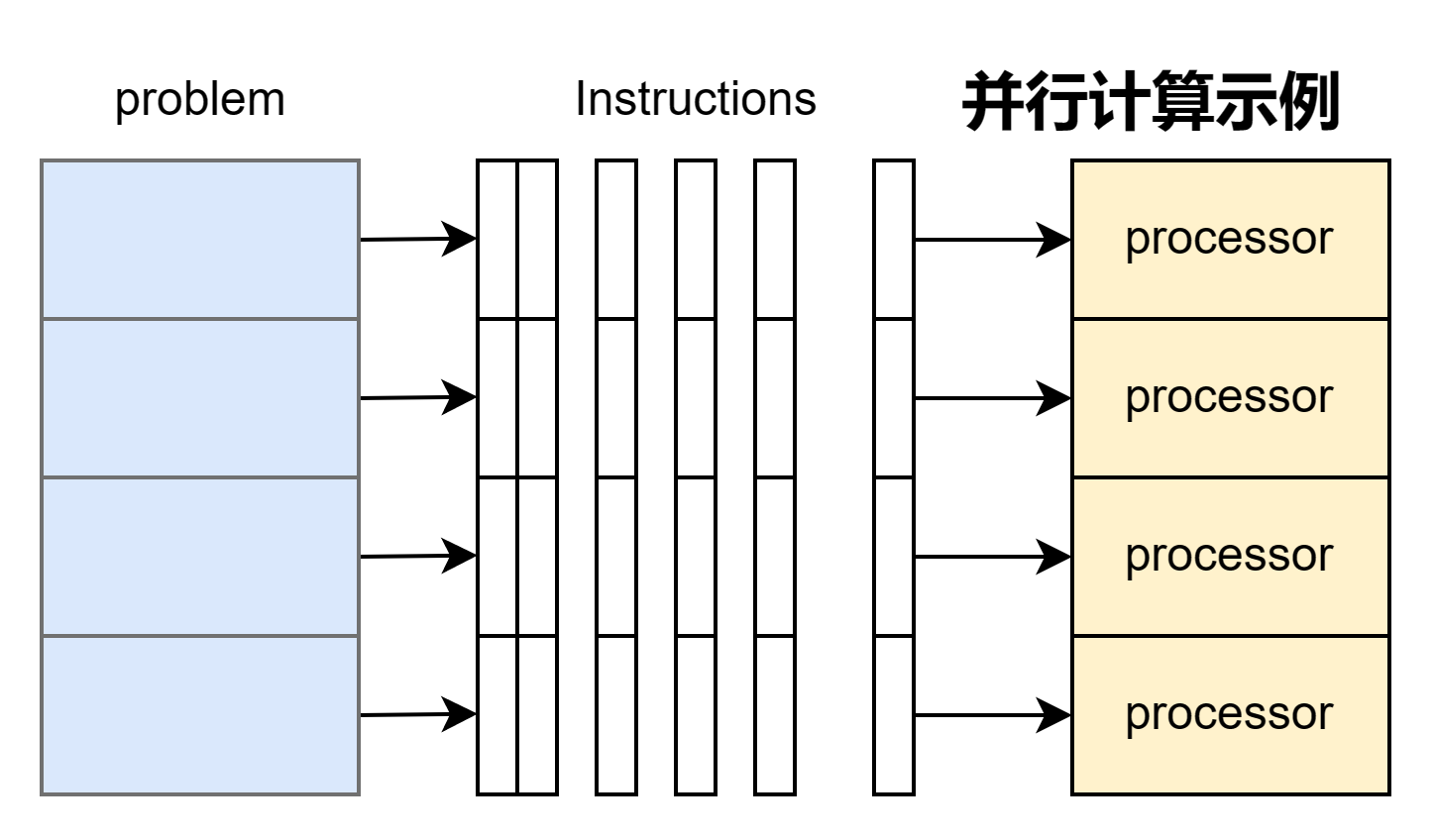
人们一般将“将问题拆分为可以同时解决的离散部分”这一环节称之为任务分解, 而将“任务在不同的处理器上同时执行”这件事情称之为并行计算。
# 并行计算资源
从计算机的角度来看,计算机的发展历史就是一部并行计算的历史。如下图所示,从硬件角度来看,当今几乎所有的独立计算机都是并行的:
- 多功能单元: CPU、GPU、磁盘、网络等
- 多个执行单元/核心: 多CPU、多GPU
- 多个硬件线程: 多核、超线程
- 集群: 通过网络或者高速总线连接的多个独立计算机

作为高性能计算的手段,并行计算有两个核心目标:调度更多的计算资源,以及提高计算资源的利用率。 不同的任务分解以及不同的处理器的组合,不同组合策略之间的权衡,构成了并行计算的绝大部分内容。 例如:单机多线程、单机多进程、多机多进程、分布式计算、GPU计算属于典型的应用场景,但实际中它们往往会互相交织在一起。
# 选择并行计算解决方案
下表列举了常见的基本并行策略以及特点,在您开始使用并行计算工具之前,可以参考该表来选择合适的并行策略或者组合策略。
| 并行策略 | 说明 | 加速比 | 调度开销 | 优点 | 缺点 |
|---|---|---|---|---|---|
| CPU 指令级并行 | 调用硬件级别的指令级并行指令 | 1-8 倍 | 1-5ns | 开销极低,可以获得近乎免费的加速,可以在底层代码中直接使用 | 依赖硬件支持,不可移植;对数据布局及运算有要求 |
| 异步流水线 | 通过将完整的任务拆分为逻辑独立的小任务,以流水线的方式执行 | 0.9-5 倍 | 0.5-1μs | 降低不同计算设备的等待时间,提高计算资源的利用率 | 编程模式与常见的顺序编程的方式并不相同,需要学习与训练 |
| 单机多线程 | 通过多线程的方式调度多个CPU核心 | 0.9-N 倍 | 2-10μs | 可以调度全部的 CPU 资源 | 存在不算大的开销,在数据竞争与共享问题上需要特殊处理 |
| 单机多进程 | 通过多进程的方式调度多个CPU核心 | 0.8-N 倍 | 50-300μs | 可以调度全部的 CPU 资源;数据隔离 | 进程创建存在较大开销,进程间通信也存在一定开销 |
| GPU异构计算 | 对于特定任务调度专用的计算设备来获得比 CPU 更高的性能 | 10-10000 倍 | 5-20μs | GPU是为并行计算设计的设备,在大规模并行中可以以更低成本获得远高于CPU的加速比 | 需要特殊的设备;需要特殊的编程模式和专用的编程工具;与CPU 主内存并不共享,数据传输开销需要特别处理 |
| 分布式计算 | 调度更多的计算机 | 0.5-N 倍 | 0.1-2s | 可以调度更多的计算设备 | 分布式计算的编程范式复杂;需要维护集群环境;需要考虑稳定性与停机问题 |
加速比与调度开销
上表中的加速比与调度开销是一个经验性的结论。加速比中 N 是指计算资源越多,加速比越高,它并不一定意味着1024个节点可以得到1024倍加速比,更有可能是 200-800 之间 —— 这完全取决于具体算法和并行策略。 加速比中的 0.9、0.5 这些小于1的数字的意思是:不加思考地盲目使用并行计算,很可能会得到比串行计算更差的结果。
多线程与多进程
从编程的角度来说,多进程对于代码实现的要求会更低一些:一个即使写的不那么好的代码也可以尝试使用多进程来调度更多的计算资源从而加速代码。 相比而言,多线程则需要仔细考虑数据竞争与共享问题,需要更多的编程经验,但也可以因此获得更高的性能和更低的内存开销。