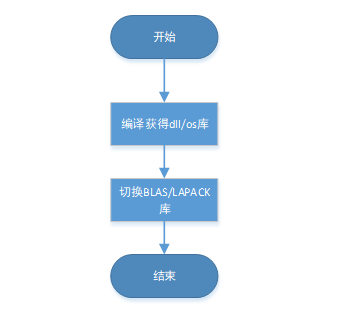
# 算法替换案例
科学计算与系统建模仿真平台基于 Julia 语言开发的高性能科学计算软件,其中默认线性代数库底层算法程序为 OpenBLAS,同时 Julia 中提供 libblastrampoline 作为"跳板"机制,可以实现外部 BLAS/LAPACK 库的识别、 替换操作。主要替换步骤如下:
 BLAS(英语:Basic Linear Algebra Subprograms,基础线性代数程序集)是一个应用程序接口(API)标准,用以规范发布基础线性代数操作的数值库(如矢量或矩阵乘法)。该程序集最初发布于 1979 年,并用于创建更大的数值程序包(如 LAPACK)。在高性能计算领域,BLAS 被广泛使用。例如,LINPACK 的运算成绩则很大程度上取决于 BLAS 中子程序 DGEMM 的表现。
BLAS(英语:Basic Linear Algebra Subprograms,基础线性代数程序集)是一个应用程序接口(API)标准,用以规范发布基础线性代数操作的数值库(如矢量或矩阵乘法)。该程序集最初发布于 1979 年,并用于创建更大的数值程序包(如 LAPACK)。在高性能计算领域,BLAS 被广泛使用。例如,LINPACK 的运算成绩则很大程度上取决于 BLAS 中子程序 DGEMM 的表现。
为提高性能,各软硬件厂商则针对其产品对 BLAS 接口实现进行高度优化。目前已有相关 BLAS 库实现如下:
- Netlib BLAS:官方参考实现,程序语言为 Fortran 77;
- ACML(AMD Core Math Library):厂商 AMD 的 BLAS 实现;
- ATLAS:BSD 许可证开源的 BLAS 实现;
- CUDA SDK:NVIDIA CUDA SDK 包含了 BLAS 功能,通过 C 编程实现在 GeForce 8 系列或更新一代显卡上运行;
- GotoBLAS:德克萨斯高级计算中心后藤和茂开发的 BSD 许可证开源的 BLAS 实现,但已停止了活跃开发,后继者为 OpenBLAS;
- OpenBLAS:继任 GotoBLAS 的开源 BLAS 的实现,主要由中国科学院软件研究所并行软件与计算科学实验室进行开发;
- ESSL:IBM 的科学工程数值库 ESSL,支持 AIX 和 Linux 系统下的 PowerPC 架构;
- Intel MKL:Intel 核心数学库,支持 Pentium,Intel Core与 ItaniumCPU 系列。实现平台包括 Linux,Windows 及 OS X;
- GSL:GNU 科学数值库(GNU Scientific Library)包含了 GNU 下的多平台 C 语言实现;
- RenderScript IntrinsicBLAS:基于 Renderscript 的 Android 移动终端高性能 BLAS 实现。
此处主要以 OpenBLAS 库为案例进行替换。
接下来以 OpenBLAS 开源库作为示例展示如何切换 BLAS/LAPACK。
# 替换案例一:OpenBLAS@0.3.21
该案例展示在 Windows 操作系统上,编译 OpenBLAS 库并在 Syslab 中切换底层算法,由于 OpenBLAS 默认将 BLAS/LAPACK 打包,所以该案例同样适用于 LAPACK 替换。
为了编译 OpenBLAS 开源库并获取所需的动态库,需先进行环境搭建。
# 下载并安装 MSYS
Minimal GNU(POSIX)system on Windows,是 MinGW 提供的一个小型的 GNU 环境,包括基本的 bash,make 等等。与 Cygwin 大致相当。简单说 MSYS 就相当于一个在 Windows 下运行的 linux bash shell 环境,支持绝大部分 linux 常用命令。而 MSYS2 是一个独立项目,它重写了 MSYS, MSYS2 安装更简单,使用更方便,还提供 pacman 工具进行软件包的安装管理(就像 ubuntu 的 apt-get,centos 的 yum)。
选择
mys2-x86_64-latest.exe进行安装。安装完成后,点击如下图标进行后续操作:
# MinGW gcc 编译器
输入命令安装 gcc 编译器:
pacman -S mingw-w64-x86_64-gcc //64位
pacman -S mingw-w64-i686-gcc // 32位
# 安装 fortran 编译器
安装后,才可编译 LAPACK。
安装命令如下:
pacman -S mingw-w64-x86_64-gcc-fortran
# 安装 perl
安装命令如下:
pacman -S --noconfirm perl
# 安装 MSYS2 的 make
安装命令如下:
pacman -S make
# 下载 OpenBLAS 源码
由于 Syslab 使用的 Julia 默认使用 64 位整数字长,所以要求 BLAS 库进行编译成 64 位整数字长,即 ILP64。这里选用最新发布的 OpenBLAS 作为替换目标。
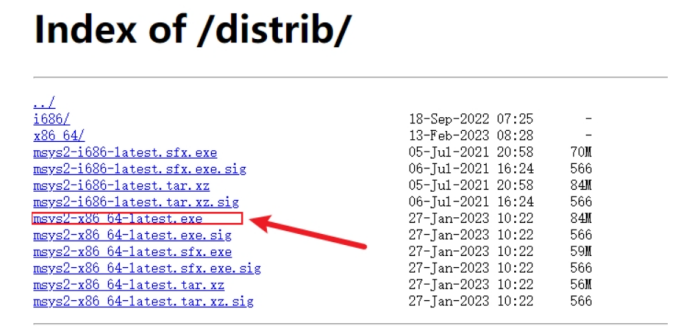
详情请见:https://github.com/xianyi/OpenBLAS/releases/tag/v0.3.21 (opens new window)
源码下载地址:https://github.com/xianyi/OpenBLAS/releases/download/v0.3.21/OpenBLAS-0.3.21.zip (opens new window)
下载并解压后如下所示:
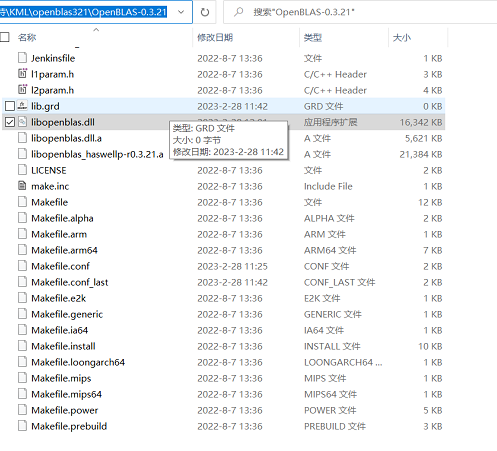
# 切换 BLAS/LAPACK
替换算法库
打开 Syslab 后在 REPL 中利用BLAS.lbt_forward函数对目标动态链接库进行替换,输入如下代码进行替换,其中verbose = true表示打印替换信息,clear = true表示清除其他 BLAS/LAPACK 库。
newblaspath = "path_to_newblasdll"
BLAS.lbt_forward(newblaspath,clear = true,verbose = true)
#=
Generating forwards to D:/KML/openblas321/OpenBLAS-0.3.21/libopenblas.dll
-> Autodetected symbol suffix ""
-> Autodetected interface ILP64 (64-bit)
-> Autodetected gfortran calling convention
Processed 4945 symbols; forwarded 4860 symbols with 64-bit interface and mangling to a suffix of ""
4860
=#
查看当前算法库
打开 Syslab 后在 REPL 中输入如下代码查看当前作用的底层算法库:
using TyMath
BLAS.get_config()
#=
julia> BLAS.get_config()
LinearAlgebra.BLAS.LBTConfig
Libraries:
└ [ILP64] libopenblas64_.dll
=#
# 替换案例二:BLIS
该案例讲解 BLIS 库在 Linux 系统上编译并替换过程。
# 编译 BLIS
具体编译流程的详情请见:https://github.com/flame/blis#how-to-download-blis (opens new window)
提示
要想获取满足 ILP64 规范的 BLIS 库请使用-b 64选项设置。
# 替换 BLIS 库
通过上述步骤编译成功后,在 lib 文件夹能找到动态链接库libblis.so,获取其绝对路径libblispath。
替换算法库
打开 Syslab 后在 REPL 中利用BLAS.lbt_forward函数对目标动态链接库进行替换,输入如下代码进行替换,其中verbose = true表示打印替换信息,clear = true表示清除其他 BLAS/LAPACK 库。
newblaspath = "path_to_newblasdll"
BLAS.lbt_forward(newblaspath,clear = true,verbose = true)
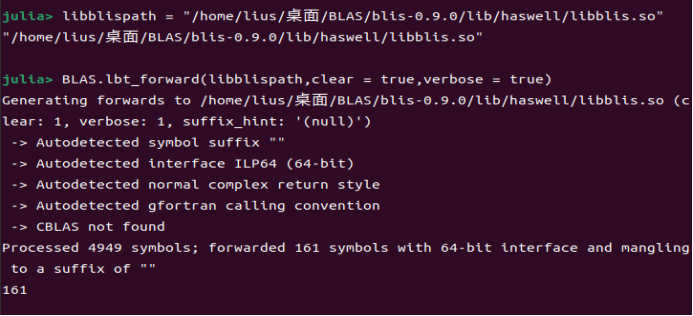
查看当前算法库
打开 Syslab 后在 REPL 中输入如下代码查看当前作用的底层算法库:
BLAS.get_config()

# KMLBLAS 测试报告
接下来将以 KML 中 BLAS 算法库作为目标,测试其功能和性能。
# 测试环境
| 处理器 |
|
| 内存 | 126 G |
| 操作系统 | 麒麟 V10 |
# 测试
# 测试方法
- 有序列表利用 Julia 提供
ccall函数对 KMLBLAS 提供动态链接库内函数进行直接调用并测试性能; - 利用
BLAS.lbt_forward函数进行底层替换,通过外部mul!、*、norm等函数接口进行测试验证。
# 测试对象与标准选取
KML 中提供 LP64(32位)BLAS 库,不支持直接传入 Float64 数进行计算和,经过调研和测试发现在选用测试方法一时,创建数据类型为 Float32 的向量或矩阵进行计算,在选用测试方法二时,可以创建数据类型为 UInt32 的向量或矩阵进行计算,故测试对象选取为:
- 数据类型为 Float32 的向量或矩阵,且使用 s 前缀标记为单精度浮点数进行计算,如:sgemm_、ssymm_ 等;
- 数据类型为 UInt32 的向量或矩阵。
利用 BenchmarkTools 库提供的 @btime 宏对测试用例进行性能测试并对比结果。
# 函数列表
针对 KML 提供的动态链接库,对其中部分函数进行测试,测试列表如下表所示。
| 编号 | 函数名称 | 功能定义 |
|---|---|---|
| 1 | GEMM | 通用矩阵乘法(General Matrix Multiply) |
| 2 | SYMM | 对称矩阵乘法(SYMMetric Matrix Multiply) |
| 3 | SYR2K | 对称矩阵乘法的双重乘积(SYmmetric Rank-2K update) |
| 4 | TRMM | 三角矩阵与一般矩阵的乘法(Triangular Matrix Matrix Multiply) |
| 5 | TRSM | 三角矩阵与多个右侧向量或矩阵的线性方程组(TRiangular Solve with Multiple right-hand sides) |
| 6 | ROTG | 计算 Givens 旋转矩阵(ROTate Givens) |
| 7 | ROTMG | 特定的 Givens 变换(ROTate Matrix Givens) |
| 8 | ROT | 计算多维反离散余弦变换阵列 A 的(DCT)(Double ROTate) |
| 9 | ROTM | 执行数组 A 类型的多维实数输入/实数输出(r2r)变换(Double ROTate Matrix) |
| 10 | SCAL | 将一个向量的每个元素乘以一个标量值 |
| 11 | AXPY | 将一个向量乘以一个标量并加到另一个向量上(Alpha X Plus Y) |
| 12 | DOT | 向量内积函数(Dot Product) |
| 13 | NRM2 | 计算向量二范数(Norm 2) |
| 14 | ASUM | 向量的绝对值之和函数(计算向量的 L1 范数(曼哈顿范数))(Absolute Sum) |
| 15 | IDAMAX | 向量最大值索引(Index of Absolute Maximum) |
| 16 | GEMV | 矩阵向量乘法(Generalized Matrix-Vector) |
| 17 | GBMV | 带状矩阵和向量之间的乘法(Generalized Banded Matrix-Vector) |
| 18 | SYMV | 对称矩阵向量乘法(Symmetric Matrix-Vector) |
| 19 | SBMV | 对称带状矩阵向量乘法(Scaled Band Matrix-Vector) |
| 20 | SPMV | 稀疏矩阵向量乘法(Sparse Matrix-Vector) |
| 21 | TRMV | 上/下三角矩阵向量乘法(Triangular Matrix-Vector) |
| 22 | TRSV | 上/下三角矩阵求解函数,用于解三角线性方程组(Triangular Solve Vector) |
| 23 | GER | 计算两个向量的外积或外积更新(Generalized Rank-1 Update) |
| 24 | SYR | 对称矩阵外积更新(Symmetric Rank-1) |
| 25 | SYR2K | 对称矩阵的秩 -2K 更新(Symmetric Rank-2K) |
| 编号 | 函数名称 | 功能定义 |
|---|---|---|
| 1 | * | 矩阵乘法(Matrix Multiplication) |
| 2 | * | 向量乘法(Vector Multiplication) |
| 3 | norm | 范数(Norm) |
| 4 | \ | 矩阵左除(Matrix Left Division) |
| 5 | symm | 对称矩阵和一般矩阵的乘法运算(Symmetric Matrix Multiplication) |
| 6 | symm | 对称矩阵和一般矩阵的乘法运算(Symmetric Matrix Multiplication) |
| 7 | SYR2K | 对称矩阵与一般矩阵的乘法和加法运算(Symmetric Rank-2K) |
| 8 | TRMM | 三角矩阵与一般矩阵的乘法(Triangular Matrix-Matrix Multiplication) |
| 9 | TRMM | 三角矩阵与一般矩阵的乘法(Triangular Matrix-Matrix Multiplication) |
| 10 | scal | 向量进行标量缩放(Scale) |
| 11 | Copy | 将一个向量的元素复制到另一个向量中(Copy) |
| 12 | AXPY | 向量乘以一个标量并与另一个向量相加(A times X plus Y) |
| 13 | DOT | 向量的点积运算(Dot product) |
| 14 | NRM2 | 向量的二范数计算(2-Norm) |
| 15 | ASUM | 向量的绝对值求和(Absolute Sum) |
| 16 | GEMV | 一般矩阵与向量的乘法(General Matrix-Vector Multiplication) |
| 17 | symv | 对称矩阵与向量的乘法(Symmetric Matrix-Vector Multiplication) |
| 18 | SPMV | 稀疏矩阵与向量的乘法(Sparse Matrix-Vector Multiplication) |
| 19 | TRMV | 三角矩阵与向量的乘法(Triangular Matrix-Vector multiplication) |
| 20 | TBMV | 带状三角矩阵与向量的乘法(Triangular Banded Matrix-Vector multiplication) |
| 21 | GER | 一般矩阵的秩 -1 更新(General Matrix Rank-1 Update) |
| 22 | SYR | 对称矩阵的秩 -1 更新(Symmetric Matrix Rank-1 Update) |
# 单元测试结果及对比
如上表所示,展示了 KML 与 OpenBLAS 在相同示例情况下的性能对比,其中红色标记字体表示性能占优的数据。
| 编号 | 函数 | 示例 | KML | OpenBLAS |
|---|---|---|---|---|
| 1 | GEMM | rng = MersenneTwister(1234) A = rand(rng,Float32,1000,1000) B = rand(rng,Float32,1000,1000) C = zeros(Float32,1000,1000) transA = 'N' transB = 'N' m = size(A, transA == 'N' ? 1 : 2) ka = size(A, transA == 'N' ? 2 : 1) kb = size(B, transB == 'N' ? 1 : 2) n = size(B, transB == 'N' ? 2 : 1) alpha = Float32(1.0) beta = Float32(0.0) @btime ccall((:sgemm_,pwd() * libblaspath),Cvoid,(Ref{UInt8}, Ref{UInt8}, Ref{BLAS.BlasInt}, Ref{BLAS.BlasInt}, Ref{BLAS.BlasInt}, Ref{Float32}, Ptr{Float32}, Ref{BLAS.BlasInt},Ptr{Float32}, Ref{BLAS.BlasInt}, Ref{Float32}, Ptr{Float32}, Ref{BLAS.BlasInt}, Clong, Clong),transA, transB,m,n,ka,alpha,A,max(1,stride(A,2)),B,max(1,stride(B,2)),beta,C,max(1,stride(C,2)),1,1); | 4.263 ms (37 allocations: 592 bytes) | 10.305 ms (37 allocations: 592 bytes) |
| 2 | SYMM | side = 'L' uplo = 'L' m, n = size(C) elty =Float32 alpha = Float32(1.0) beta = Float32(0.0) rng = MersenneTwister(1234) A = rand(rng,Float32,3,4) B = rand(rng,Float32,4,2) C = zeros(Float32,3,2) ccall((:ssymm_, libblaspath), Cvoid, (Ref{UInt8}, Ref{UInt8}, Ref{BLAS.BlasInt}, Ref{BLAS.BlasInt}, Ref{elty}, Ptr{elty}, Ref{BLAS.BlasInt}, Ptr{elty},Ref{BLAS.BlasInt}, Ref{elty}, Ptr{elty}, Ref{BLAS.BlasInt},Clong, Clong), side, uplo, m, n, Float32(alpha), A, max(1,stride(A,2)), B, max(1,stride(B,2)), Float32(beta), C, max(1,stride(C,2)), 1, 1) | 13.200 μs (23 allocations: 368 bytes) | 13.150 μs (23 allocations: 368 bytes) |
| 3 | SYR2K | side = 'L' uplo = 'N' m, n = size(C) elty = Float32 alpha = Float32(1.0) beta = Float32(0.0) rng = MersenneTwister(1234) A = rand(rng,Float32,3,4) B = rand(rng,Float32,4,2) C = zeros(Float32,3,2) ccall((:ssyr2k_, libblaspath), Cvoid, (Ref{UInt8}, Ref{UInt8}, Ref{BLAS.BlasInt}, Ref{BLAS.BlasInt},Ref{elty}, Ptr{elty}, Ref{BLAS.BlasInt}, Ptr{elty},Ref{BLAS.BlasInt}, Ref{elty}, Ptr{elty}, Ref{BLAS.BlasInt},Clong, Clong), side, uplo, m, n, Float32(alpha), A, max(1,stride(A,2)), B, max(1,stride(B,2)), Float32(beta), C, max(1,stride(C,2)), 1, 1) | / | 13.311 μs (23 allocations: 368 bytes) |
| 4 | TRMM | using LinearAlgebra using Random rng = MersenneTwister(1234) A = rand(rng,Float32,30,30) A = diag(A) B = rand(rng,Float32,30,30) C = zeros(Float32,3,2) side = 'L' uplo = 'U' m, n = size(C) elty = Float32 alpha = Float32(1.0) beta = Float32(0.0) ccall((:strmm_, libblaspath), Cvoid, (Ref{UInt8}, Ref{UInt8}, Ref{UInt8}, Ref{UInt8}, Ref{BLAS.BlasInt}, Ref{BLAS.BlasInt},Ref{elty}, Ptr{elty}, Ref{BLAS.BlasInt}, Ptr{elty},Ref{BLAS.BlasInt}, Clong, Clong,Clong, Clong), side, uplo,'C','N', m, n,Float32(alpha), A, max(1,stride(A,2)), B, max(1,stride(B,2)),1, 1, 1, 1) | 9.710 μs (17 allocations: 272 bytes | 10.041 μs (17 allocations: 272 bytes) |
| 5 | TRSM | using LinearAlgebra using Random rng = MersenneTwister(1234) A = rand(rng,Float32,30,30) A = diag(A) B = rand(rng,Float32,30,30) C = zeros(Float32,3,2) side = 'L' uplo = 'U' m, n = size(C) elty = Float32 alpha = Float32(1.0) beta = Float32(0.0) ccall((:strsm_, libblaspath), Cvoid,(Ref{UInt8}, Ref{UInt8}, Ref{UInt8}, Ref{UInt8}, Ref{BLAS.BlasInt}, Ref{BLAS.BlasInt},Ref{elty}, Ptr{elty}, Ref{BLAS.BlasInt}, Ptr{elty},Ref{BLAS.BlasInt}, Clong, Clong,Clong, Clong), side, uplo,'C','N', m, n, Float32(alpha), A, max(1,stride(A,2)), B, max(1,stride(B,2)),1, 1, 1, 1) | 10.100 μs (17 allocations: 272 bytes) | 10.181 μs (17 allocations: 272 bytes) |
| 6 | ROTG | using LinearAlgebra using Random rng = MersenneTwister(1234) A = rand(rng,Float32,300) B = rand(rng,Float32,300) c = rand(rng, Float32, 300) s = rand(rng, Float32, 300) elty = Float32 @btime ccall((:srotg_, libblaspath), Cvoid, (Ref{BLAS.BlasInt}, Ptr{elty}, Ref{BLAS.BlasInt}, Ptr{elty}, Ref{BLAS.BlasInt}, Ref{elty}, Ref{elty}),1, A, 1, B, 1, c, s) | 5.038 μs (6 allocations: 128 bytes) | 5.027 μs (6 allocations: 128 bytes) |
| 7 | ROTMG | using LinearAlgebra using Random rng = MersenneTwister(1234) A = rand(rng,Float32,300) B = rand(rng,Float32,300) c = rand(rng, Float32, 300) s = rand(rng, Float32, 300) elty = Float32 @btime ccall((:srotmg_, libblaspath), Cvoid, (Ref{BLAS.BlasInt}, Ptr{elty}, Ref{BLAS.BlasInt}, Ptr{elty}, Ref{BLAS.BlasInt}, Ref{elty}, Ref{elty}),1, A, 1, B, 1, c, s) | 5.012 μs (6 allocations: 128 bytes) | 5.038 μs (6 allocations: 128 bytes) |
| 8 | ROT | using LinearAlgebra using Random rng = MersenneTwister(1234) A = rand(rng,Float32,300) B = rand(rng,Float32,300) c = rand(rng, Float32, 300) s = rand(rng, Float32, 300) elty = Float32 ccall((:srot_, libblaspath), Cvoid, (Ref{BLAS.BlasInt}, Ptr{elty}, Ref{BLAS.BlasInt}, Ptr{elty}, Ref{BLAS.BlasInt}, Ref{elty}, Ref{elty}),1, A, 1, B, 1, c, s) | 5.075 μs (6 allocations: 128 bytes) | 5.058 μs (6 allocations: 128 bytes) |
| 9 | ROTM | using LinearAlgebra using Random rng = MersenneTwister(1234) A = rand(rng,Float32,300) B = rand(rng,Float32,300) c = rand(rng, Float32, 300) s = rand(rng, Float32, 300) elty = Float32 @btime ccall((:srotm_, libblaspath), Cvoid, (Ref{BLAS.BlasInt}, Ptr{elty}, Ref{BLAS.BlasInt}, Ptr{elty}, Ref{BLAS.BlasInt}, Ref{elty}, Ref{elty}),1, A, 1, B, 1, c, s) | 5.027 μs (6 allocations: 128 bytes) | 4.969 μs (6 allocations: 128 bytes) |
| 10 | SCAL | using LinearAlgebra using Random rng = MersenneTwister(1234) A = rand(rng,Float32,300) elty = Float32 @time ccall((:sscal_, libblaspath), Cvoid, (Ref{BLAS.BlasInt}, Ref{elty}, Ptr{elty}, Ref{BLAS.BlasInt}),length(A),Float32(5),A,stride(A,1)); | 0.000039 seconds (8 allocations: 128 bytes) | 0.000032 seconds (8 allocations: 128 bytes) |
| 11 | AXPY | using LinearAlgebra using Random rng = MersenneTwister(1234) A = rand(rng,Float32,300) B = rand(rng,Float32,300) elty = Float32 @btime ccall((:saxpy_, libblaspath), Cvoid, (Ref{BLAS.BlasInt}, Ref{elty}, Ptr{elty}, Ref{BLAS.BlasInt}, Ptr{elty}, Ref{BLAS.BlasInt}),length(A),Float32(0.5),A,stride(A,1),B,stride(B,1)); | 5.787 μs (11 allocations: 176 bytes) | 5.587 μs (11 allocations: 176 bytes) |
| 12 | DOT | using LinearAlgebra using Random rng = MersenneTwister(1234) A = rand(rng,Float32,300) B = rand(rng,Float32,300) elty = Float32 @time ccall((:saxpy_, libblaspath), Cvoid, (Ref{BLAS.BlasInt}, Ptr{elty}, Ref{BLAS.BlasInt}, Ptr{elty}, Ref{BLAS.BlasInt}),length(A),A,stride(A,1),B,stride(B,1)); | / | / |
| 13 | NRM2 | using LinearAlgebra using Random rng = MersenneTwister(1234) A = rand(rng,Float32,300) B = rand(rng,Float32,300) elty = Float32 @btime ccall((:snrm2_, libblaspath), elty, (Ref{BLAS.BlasInt}, Ptr{elty}, Ref{BLAS.BlasInt}),length(A),A,stride(A,1)); | 3.423 μs (5 allocations: 80 bytes) | 4.015 μs (5 allocations: 80 bytes) |
| 14 | ASUM | using LinearAlgebra using Random rng = MersenneTwister(1234) A = rand(rng,Float32,300) B = rand(rng,Float32,300) elty = Float32 @btime ccall((:sasum_, libblaspath), elty, (Ref{BLAS.BlasInt}, Ptr{elty}, Ref{BLAS.BlasInt}),length(A),A,stride(A,1)); | 2.859 μs (5 allocations: 80 bytes) | 2.836 μs (5 allocations: 80 bytes) |
| 15 | IDAMAX | using LinearAlgebra using Random rng = MersenneTwister(1234) A = rand(rng,Float32,300) B = rand(rng,Float32,300) elty = Float32 @btime ccall((:isamax_, libblaspath), elty, (Ref{BLAS.BlasInt}, Ptr{elty}, Ref{BLAS.BlasInt}),length(A),A,stride(A,1)); | 2.933 μs (5 allocations: 80 bytes) | 2.979 μs (5 allocations: 80 bytes) |
| 16 | GEMV | using LinearAlgebra using Random rng = MersenneTwister(1234) A = rand(rng,Float32,300,300) X = rand(rng,Float32,300) elty = Float32 alpha = true beta = false m = 300 n = 300 trans = 'N' Y = rand(rng,Float32,300)@btime ccall((:sgemv_, libblaspath), Cvoid,(Ref{UInt8}, Ref{BLAS.BlasInt}, Ref{BLAS.BlasInt}, Ref{elty},Ptr{elty}, Ref{BLAS.BlasInt}, Ptr{elty}, Ref{BLAS.BlasInt},Ref{elty}, Ptr{elty}, Ref{BLAS.BlasInt}, Clong), trans, size(A,1), size(A,2), alpha, A, max(1,stride(A,2)), X, stride(X,1), beta, Y, stride(Y,1), 1); | 29.921 μs (19 allocations: 304 bytes) | 29.400 μs (19 allocations: 304 bytes) |
| 17 | GBMV | using LinearAlgebra using Random rng = MersenneTwister(1234) A = rand(rng,Float32,300,300) X = rand(rng,Float32,300) elty = Float32 alpha = Float32(0) beta = Float32(0) m = 300 n = 300 trans = 'N' kl = 300 ku = 300 Y = rand(rng,Float32,300)@btime ccall((:sgbmv_, libblaspath),Cvoid,(Ref{UInt8}, Ref{BLAS.BlasInt}, Ref{BLAS.BlasInt}, Ref{BLAS.BlasInt}, Ref{BLAS.BlasInt}, Ref{elty},Ptr{elty}, Ref{BLAS.BlasInt}, Ptr{elty}, Ref{BLAS.BlasInt}, Ref{elty}, Ptr{elty}, Ref{BLAS.BlasInt}, Clong), trans, m,size(A,1),kl,ku, alpha,A, max(1,stride(A,2)), X, stride(X,1),beta, Y, stride(Y,1), 1); | / | / |
| 18 | SYMV | using LinearAlgebra using Random rng = MersenneTwister(1234) A = rand(rng,Float32,300,300) x = rand(rng,Float32,300) elty = Float32 alpha = Float32(1) beta = Float32(1) m = 300 n = 300 y = rand(rng,Float32,300) uplo = 'L' @btime ccall((:ssymv_, libblaspath),Cvoid,(Ref{UInt8}, Ref{BLAS.BlasInt}, Ref{elty}, Ptr{elty},Ref{BLAS.BlasInt}, Ptr{elty}, Ref{BLAS.BlasInt}, Ref{elty},Ptr{elty}, Ref{BLAS.BlasInt}, Clong), uplo, n, alpha, A, max(1,stride(A,2)), x, stride(x,1), beta, y, stride(y,1), 1); | 17.250 μs (19 allocations: 304 bytes) | 16.930 μs (19 allocations: 304 bytes) |
| 19 | SBMV | using LinearAlgebra using Random rng = MersenneTwister(1234) A = rand(rng,Float32,300,300) x = rand(rng,Float32,300) elty = Float32 alpha = Float32(0) beta = Float32(0) m = 300 n = 300 y = rand(rng,Float32,300) uplo = 'L' @btime ccall((:ssbmv_, libblaspath),Cvoid,(Ref{UInt8}, Ref{BLAS.BlasInt}, Ref{BLAS.BlasInt}, Ref{elty}, Ptr{elty},Ref{BLAS.BlasInt}, Ptr{elty}, Ref{BLAS.BlasInt}, Ref{elty},Ptr{elty}, Ref{BLAS.BlasInt}, Clong), uplo, n, 300,alpha, A, max(1,stride(A,2)), x, stride(x,1), beta, y, stride(y,1), 1); | / | / |
| 20 | SPMV | using LinearAlgebra using Random rng = MersenneTwister(1234) A = rand(rng,Float32,300,300) x = rand(rng,Float32,300) elty = Float32 alpha = Float32(0) beta = Float32(0) m = 300 n = 300 y = rand(rng,Float32,300) uplo = 'L' @btime ccall((:sspmv_, libblaspath),Cvoid,(Ref{UInt8}, Ref{BLAS.BlasInt}, Ref{elty}, Ptr{elty},Ptr{elty}, Ref{BLAS.BlasInt}, Ref{elty}, Ptr{elty}, Ref{BLAS.BlasInt}, Clong), uplo, n, alpha, A,x, max(1,stride(x,1)), beta, y, stride(y,1), 1); | 10.010 μs (17 allocations: 272 bytes) | 10.130 μs (17 allocations: 272 bytes) |
| 21 | TRMV | using LinearAlgebra using Random rng = MersenneTwister(1234) A = rand(rng,Float32,300,300) x = rand(rng,Float32,300) elty = Float32 alpha = Float32(0) beta = Float32(0) m = 300 n = 300 y = rand(rng,Float32,300) uplo = 'L' trans = 'N' diag = 'N' @btime ccall((:strmv_, libblaspath),Cvoid,(Ref{UInt8}, Ref{UInt8}, Ref{UInt8}, Ref{BLAS.BlasInt}, Ptr{elty},Ref{BLAS.BlasInt}, Ptr{elty}, Ref{BLAS.BlasInt}, Clong, Clong, Clong), uplo, trans, diag, n, A, max(1,stride(A,2)), x, max(1,stride(x, 1)), 1, 1, 1); | 21.520 μs (14 allocations: 224 bytes) | 12.360 μs (14 allocations: 224 bytes) |
| 22 | TRSV | using LinearAlgebra using Random rng = MersenneTwister(1234) A = rand(rng,Float32,300,300) x = rand(rng,Float32,300) elty = Float32 alpha = Float32(0) beta = Float32(0) m = 300 n = 300 y = rand(rng,Float32,300) uplo = 'L' trans = 'N' diag = 'N' @btime ccall((:strsv_, libblaspath),Cvoid,(Ref{UInt8}, Ref{UInt8}, Ref{UInt8}, Ref{BLAS.BlasInt}, Ptr{elty},Ref{BLAS.BlasInt}, Ptr{elty}, Ref{BLAS.BlasInt}, Clong, Clong, Clong), uplo, trans, diag, n, A, max(1,stride(A,2)), x, max(1,stride(x, 1)), 1, 1, 1); | 21.091 μs (14 allocations: 224 bytes) | 21.140 μs (14 allocations: 224 bytes) |
| 23 | GER | using LinearAlgebra using Random rng = MersenneTwister(1234) A = rand(rng,Float32,300,300) x = rand(rng,Float32,300) elty = Float32 alpha = Float32(0) beta = Float32(0) m = 300 n = 300 y = rand(rng,Float32,300) uplo = 'L' trans = 'N' diag = 'N' @btime ccall((:sger_, libblaspath),Cvoid,( Ref{BLAS.BlasInt},Ref{BLAS.BlasInt}, Ref{elty},Ptr{elty}, Ref{BLAS.BlasInt}, Ptr{elty},Ref{BLAS.BlasInt}, Ptr{elty}, Ref{BLAS.BlasInt}), m,n,alpha,x,stride(x,1),y,stride(y,1),A,max(1,stride(A,2))); | 9.260 μs (16 allocations: 256 bytes) | 9.370 μs (16 allocations: 256 bytes) |
| 24 | SYR | using LinearAlgebra using Random rng = MersenneTwister(1234) A = rand(rng,Float32,300,300) x = rand(rng,Float32,300) elty = Float32 alpha = Float32(0) beta = Float32(0) m = 300 n = 300 y = rand(rng,Float32,300) uplo = 'L' trans = 'N' diag = 'N' @btime ccall((:ssyr_, libblaspath),Cvoid,(Ref{UInt8}, Ref{BLAS.BlasInt}, Ref{elty},Ptr{elty}, Ref{BLAS.BlasInt}, Ptr{elty},Ref{BLAS.BlasInt}), uplo,n,alpha,x,stride(x,1),A,max(1,stride(A,2))); | 7.555 μs (13 allocations: 208 bytes) | 7.675 μs (13 allocations: 208 bytes) |
| 25 | SYR2K | using LinearAlgebra using Random rng = MersenneTwister(1234) A = rand(rng,Float32,300,300) B = rand(rng,Float32,300,300) C = rand(rng,Float32,300,300) x = rand(rng,Float32,300) elty = Float32 alpha = Float32(0) beta = Float32(0) m = 300 n = 300 k = 300 y = rand(rng,Float32,300) uplo = 'L' trans = 'N' diag = 'N' @btime ccall((:ssyr2k_, libblaspath),Cvoid,(Ref{UInt8}, Ref{UInt8}, Ref{BLAS.BlasInt}, Ref{BLAS.BlasInt}, Ref{elty}, Ptr{elty}, Ref{BLAS.BlasInt}, Ptr{elty}, Ref{BLAS.BlasInt}, Ref{elty},Ptr{elty}, Ref{BLAS.BlasInt}, Clong, Clong), uplo, trans, n, k, alpha, A, max(1,stride(A,2)), B, max(1,stride(B,2)), beta, C, max(1,stride(C,2)), 1, 1); | 17.310 μs (23 allocations: 368 bytes) | 20.970 μs (23 allocations: 368 bytes) |
| 编号 | 函数 | 示例 | KML | OpenBLAS |
|---|---|---|---|---|
| 1 | * | using Random rng = MersenneTwister(1234) a = rand(rng,UInt32,10,10) b = rand(rng,UInt32,10,10) using BenchmarkTools @btime $a * $b | 1.617 μs (3 allocations: 21.11 KiB) | 2.410 μs (3 allocations: 21.11 KiB) |
| using Random rng = MersenneTwister(1234) a = rand(rng,UInt32,10) b = rand(rng,UInt32,1,10) using BenchmarkTools @btime $a * $b | 1.074 μs (5 allocations: 21.20 KiB) | 1.070 μs (5 allocations: 21.20 KiB) | ||
| 2 | norm | using Random rng = MersenneTwister(1234) a = rand(rng,UInt32,10,10) @btime norm($a); | 557.425 ns (0 allocations: 0 bytes) | 558.769 ns (0 allocations: 0 bytes) |
| 3 | \ | using Random rng = MersenneTwister(1234) a = rand(rng,UInt32,10,10) b = rand(rng,UInt32,10,10) using BenchmarkTools @btime $a \ $b | 报错 | 4.037 μs (3 allocations: 1.89 KiB) |
| 4 | symm | using Random rng = MersenneTwister(1234) a = rand(rng,UInt32,10,10) b = rand(rng,UInt32,10,10) a = Symmetric(a) c = similar(b); using BenchmarkTools @btime mul!(c,a,b); | 1.597 μs (2 allocations: 20.62 KiB) | 1.773 μs (2 allocations: 20.62 KiB) |
| using Random rng = MersenneTwister(1234) a = rand(rng,UInt32,10,10) b = rand(rng,UInt32,10,10) a = Symmetric(a) using BenchmarkTools @btime $a * $b | 1.686 μs (3 allocations: 21.11 KiB) | 2.746 μs (3 allocations: 21.11 KiB) | ||
| 5 | SYR2K | using Random rng = MersenneTwister(1234) a = rand(rng,UInt32,10,10) b = rand(rng,UInt32,10,10) a = Symmetric(a) using BenchmarkTools @btime $a * $b + 0.5 * b; | 2.382 μs (5 allocations: 22.86 KiB) | 3.470 μs (5 allocations: 22.86 KiB) |
| 6 | TRMM | using Random rng = MersenneTwister(1234) a = rand(rng,UInt32,10,10) b = rand(rng,UInt32,10,10) a = Tridiagonal(a) c = similar(b) using BenchmarkTools @btime mul!(c,a,b); | 213.687 ns (0 allocations: 0 bytes) | 212.432 ns (0 allocations: 0 bytes) |
| using Random rng = MersenneTwister(1234) a = rand(rng,UInt32,10,10) b = rand(rng,UInt32,10,10) a = Tridiagonal(a) using BenchmarkTools @btime $a * $b; | 245.132 ns (1 allocation: 496 bytes) | 238.468 ns (1 allocation: 496 bytes) | ||
| 7 | scal | using Random rng = MersenneTwister(1234) a = rand(rng,UInt32,10) b = rand(rng,UInt32,10) using BenchmarkTools @btime b[1] .* a; | 930.000 ns (4 allocations: 176 bytes) | 841.452 ns (4 allocations: 176 bytes) |
| 8 | Copy | using Random rng = MersenneTwister(1234) a = rand(rng,UInt32,10) using BenchmarkTools @btime copy(a); | 51.582 ns (1 allocation: 96 bytes) | 51.672 ns (1 allocation: 96 bytes) |
| 9 | AXPY | using Random rng = MersenneTwister(1234) a = rand(rng,UInt32,10) b = rand(rng,UInt32,10) c = UInt32(3) using BenchmarkTools @btime c .* b + a; | 997.000 ns (4 allocations: 256 bytes) | 925.344 ns (4 allocations: 256 bytes) |
| 10 | DOT | using Random rng = MersenneTwister(1234) a = rand(rng,UInt32,1000) b = rand(rng,UInt32,1000) c = UInt32(3) using BenchmarkTools @btime dot(a,b); | 367.633 ns (1 allocation: 16 bytes) | 367.826 ns (1 allocation: 16 bytes) |
| 11 | NRM2 | using Random rng = MersenneTwister(1234) a = rand(rng,UInt32,1000) b = rand(rng,UInt32,1000) c = UInt32(3) using BenchmarkTools @btime norm(a,2); | 3.781 μs (1 allocation: 16 bytes) | 3.779 μs (1 allocation: 16 bytes) |
| 12 | ASUM | using Random rng = MersenneTwister(1234) a = rand(rng,UInt32,1000) b = rand(rng,UInt32,1000) c = UInt32(3) using BenchmarkTools @btime norm(a,1); | 669.120 ns (1 allocation: 16 bytes) | 706.436 ns (1 allocation: 16 bytes) |
| 13 | GEMV | using Random rng = MersenneTwister(1234) a = rand(rng,UInt32,1000,1000) b = rand(rng,UInt32,1000) c = similar(b) using BenchmarkTools @btime mul!(c,a,b); | 358.623 μs (0 allocations: 0 bytes) | 366.753 μs (0 allocations: 0 bytes) |
| 14 | symv | using Random rng = MersenneTwister(1234) a = rand(rng,UInt32,1000,1000) b = rand(rng,UInt32,1000) a = Symmetric(a) c = similar(b) using BenchmarkTools @btime mul!(c,a,b); | 3.549 ms (0 allocations: 0 bytes) | 3.542 ms (0 allocations: 0 bytes) |
| 15 | SPMV | using Random using SparseArraysrng = MersenneTwister(1234) a = sprand(rng,UInt32,1000,1000,0.05) b = rand(rng,UInt32,1000) a = Symmetric(a) c = similar(b) using BenchmarkTools @btime mul!(c,a,b); | 85.221 μs (0 allocations: 0 bytes) | 84.901 μs (0 allocations: 0 bytes) |
| 16 | TRMV | using Random rng = MersenneTwister(1234) a = rand(rng,UInt32,1000,1000) b = rand(rng,UInt32,1000) a = Tridiagonal(a) c = similar(b) using BenchmarkTools @btime mul!(c,a,b); | 1.686 μs (0 allocations: 0 bytes) | 1.684 μs (0 allocations: 0 bytes) |
| 17 | TBMV | using Random rng = MersenneTwister(1234) a = rand(rng,UInt32,1000,1000) b = rand(rng,UInt32,1000) a = LowerTriangular(a) c = similar(b) using BenchmarkTools @btime mul!(c,a,b); | 768.207 μs (0 allocations: 0 bytes) | 804.047 μs (0 allocations: 0 bytes) |
| 18 | GER | using Random rng = MersenneTwister(1234) a = rand(rng,UInt32,1000,1000) b = rand(rng,UInt32,1000) c = rand(rng,UInt32,1000) alpha = 1.5 using BenchmarkTools @btime BLAS.ger!(alpha,b,c,a); | 无 32 位接口 | 无 32 位接口 |
| 19 | SYR | using Random rng = MersenneTwister(1234) a = rand(rng,UInt32,1000,1000) b = rand(rng,UInt32,1000) c = rand(rng,UInt32,1000) alpha = 1.5 a = UpperTriangular(a) using BenchmarkTools @btime BLAS.syr!(a,alpha,b); | / | / |
# 测试结论
截止 2023/05/22,通过对单元函数测试,以动态链接库中函数和 BLAS 功能Julia函数作为目标,对 KMLBLAS 和 OpenBLAS 在鲲鹏提供 Kunpeng-920 芯片、麒麟 V10 操作系统下进行性能测试,现具体分析如下:
直接调用动态链接库中函数测试总数 25 个,除去无法对比或调用出错后 21 个,其中 KML 性能占优 4 个、性能持平 16 个、OpenBLAS 性能占优 1 个。
直接调用动态链接库中函数测试总数 19 个,除去无法对比或调用出错后 16 个,其中 KML 性能占优 5 个、性能持平 12 个、OpenBLAS 性能占有 2 个。
# 切换 FFTW 库
章节以 KMLFFT 为例,讲述如何切换 FFTW 库。其主要方法为通过构建依赖 KML 的函数库,实现 KMLFFT 的调用和切换。
# 构建依赖 KML
基于已有FFTW.jl库进行修改构建出依赖 KML 的函数库。
# 符号与变量名修改
KML 中libkfft.so导出 C 接口名称前缀统一为:fft,与 FFTW 中前缀fftw存在差异,故将库中fftw_一键替换为fft_,fftwf_替换为fftf_,注意区分大小写。
# 函数注释与修改
- KML 中未提供
fft_set_timelimit、fftf_set_timelimit函数,故注释unsafe_set_timelimit函数实现与调用,可将unsafe_set_timelimit一键替换为# unsafe_set_timelimit; - 注释
fft_init_threads()调用; - 将文件中“mkl”替换为“kml”,区分大小写;
- KML 中提供版本接口函数为
KFFTGetVersion,将const version替换为# const version,(:KFFTGetVersion替换为# (:KFFTGetVersion; version >= v"3.3.4" &&更改为#= version >= v"3.3.4" && =#;fft.jl文件中 212 ~ 217 行注释;fft.jl文件中 643 行fftw和fftwf分别修改为fft和fftf。
# 路径修改
- 将
libfft3、libfft3f修改为libkfft.so的路径,类型为字符串(String); MKL_jll.librt_path替换为libkfft.so路径。
# 函数库使用
# 安装函数库
使用Pkg.dev函数或 Pkg 模式下使用 dev 功能进行函数库安装。
# 底层切换
利用FFTW.set_provider!(“kml”)方法将依赖切换至 KML。
# 重新启动
重新启动 Julia 以实现底层调用,利用FFTW.get_provider!()函数查看底层依赖。

# KMLFFT 测试报告
基于上述替换方法,切换 KMLFFT 底层算法依赖,并对其性能进行测试。
# 测试环境
| 处理器 |
|
| 内存 | 126 G |
| 操作系统 | 麒麟 V10 |
# 函数列表
测试目标函数选取原则: Syslab 基础数学库中提供如下表所示函数接口且在科学计算和工程应用中下表函数均为高频函数,故以如下函数接口作为目标测试函数。
| 编号 | 函数名称 | 功能定义 |
|---|---|---|
| 1 | fft | 快速傅里叶变换 |
| 2 | fftshift | 将零频分量移到频谱中心 |
| 3 | ifft | 快速傅里叶逆变换 |
| 4 | ifftshift | 逆零频平移 |
| 5 | bfft | 类似 sifft,计算非归一化逆(向后)变换 |
| 6 | rfft | 实数组 A 的多维 FFT |
| 7 | dct | 执行多维 II 型离散余弦变换(DCT)数组 A,使用 DCT 的酉归一化。 |
| 8 | idct | 计算多维反离散余弦变换阵列 A 的(DCT) |
| 9 | r2r | 执行数组 A 类型的多维实数输入/实数输出(r2r)变换 |
# 测试
在 FFT 功能中,plan 对性能的加速是很明显的,由于该测试目的为给出 KMLFFT 功能的性能测试,故所有测试均源自默认 plan,以展示在直接使用默认条件下的性能差异对比。
每个函数选取一维(1000)、二维(1000 × 1000)、三维(1000 × 1000 × 100)数据进行性能测试。
- 单元测试结果及对比:
如下表所示,展示了 KML 与 FFTW 在相同示例情况下的性能对比,其中红色标记字体表示性能占有的数据。
| 编号 | 函数 | 示例 | FFTW | KML |
|---|---|---|---|---|
| 1 | fft | rng = MersenneTwister(1234) a = rand(rng,1000) @btime fft(a); | 36.910 μs | 50.831 μs |
| rng = MersenneTwister(1234) a = rand(rng,1000,1000) @btime fft(a); | 48.897 ms | 28.608 ms | ||
| using Random rng = MersenneTwister(1234) a = rand(rng,1000,1000,100) @btime fft(a); | 7.527 s (8 allocations: 2.98 GiB) | 7.081 s (31 allocations: 2.98 GiB) | ||
| 2 | fftshift | rng = MersenneTwister(1234) a = rand(rng,1000) @btime fftshift(a); | 875.135 ns | 1.012 μs |
| rng = MersenneTwister(1234) a = rand(rng,1000,1000) @btime fftshift(a); | 1.251 ms | 1.293 ms | ||
| using Random rng = MersenneTwister(1234) a = rand(rng,1000,1000,100) @btime fftshift(a); | 178.239 ms (10 allocations: 762.94 MiB) | 177.492 ms (10 allocations: 762.94 MiB) | ||
| 3 | ifft | rng = MersenneTwister(1234) a = rand(rng,1000) @btime ifft(a); | 38.300 μs | 52.070 μs |
| rng = MersenneTwister(1234) a = rand(rng,1000,1000) @btime ifft(a); | 50.584 ms | 29.896 ms | ||
| using Random rng = MersenneTwister(1234) a = rand(rng,1000,1000,100) @btime ifft(a); | 8.344 s (8 allocations: 2.98 GiB) | 7.025 s (31 allocations: 2.98 GiB) | ||
| 4 | ifftshift | rng = MersenneTwister(1234) a = rand(rng,1000) @btime ifftshift(a); | 839.118 ns | 864.561 ns |
| rng = MersenneTwister(1234) a = rand(rng,1000,1000) @btime ifftshift(a); | 1.291 ms | 1.270 ms | ||
| using Random rng = MersenneTwister(1234) a = rand(rng,1000,1000,100) @btime ifftshift(a); | 193.375 ms (10 allocations: 762.94 MiB) | 177.540 ms (10 allocations: 762.94 MiB) | ||
| 5 | bfft | rng = MersenneTwister(1234) a = rand(rng,1000) @btime bfft(a); | 36.970 μs | 50.900 μs |
| rng = MersenneTwister(1234) a = rand(rng,1000,1000) @btime bfft(a); | 51.413 ms | 27.957 ms | ||
| using Random rng = MersenneTwister(1234) a = rand(rng,1000,1000,100) @btime bfft(a); | 7.894 s (8 allocations: 2.98 GiB) | 6.850 s (31 allocations: 2.98 GiB) | ||
| 6 | rfft | rng = MersenneTwister(1234) a = rand(rng,1000) @btime rfft(a); | 42.200 μs | 35.390 μs |
| rng = MersenneTwister(1234) a = rand(rng,1000,1000) @btime rfft(a); | 22.255 ms | 13.988 ms | ||
| using Random rng = MersenneTwister(1234) a = rand(rng,1000,1000,100) @btime rfft(a); | 1.915 s (8 allocations: 764.47 MiB) | 3.144 s (31 allocations: 764.47 MiB) | ||
| 7 | dct | rng = MersenneTwister(1234) a = rand(rng,1000) @btime dct(a,1); | 69.091 μs | 83.020 μs |
| rng = MersenneTwister(1234) a = rand(rng,1000,1000) @btime dct(a,1); | 12.439 ms | 8.705 ms | ||
| using Random rng = MersenneTwister(1234) a = rand(rng,1000,1000,100) @btime dct(a,1); | 951.359 ms (20 allocations: 764.47 MiB) | 1.171 s (40 allocations: 764.47 MiB) | ||
| 8 | idct | rng = MersenneTwister(1234) a = rand(rng,1000) @btime idct(a,1); | 70.100 μs | 82.501 μs |
| rng = MersenneTwister(1234) a = rand(rng,1000,1000) @btime idct(a,1); | 11.933 ms | 9.052 ms | ||
| using Random rng = MersenneTwister(1234) a = rand(rng,1000,1000,100) @btime idct(a,1); | 1.061 s (22 allocations: 1.49 GiB) | 1.323 s (42 allocations: 1.49 GiB) | ||
| 9 | r2r | rng = MersenneTwister(1234) a = rand(rng,1000) @btime FFTW.r2r(a,1); | 58.881 μs | 39.800 μs |
| rng = MersenneTwister(1234) a = rand(rng,1000,1000) @btime FFTW.r2r(a,1); | 24.106 ms | 13.930 ms | ||
| using Random rng = MersenneTwister(1234) a = rand(rng,1000,1000,100) @btime FFTW.r2r(a,1); | 6.031 s (6 allocations: 762.94 MiB) | 3.856 s (26 allocations: 762.94 MiB) |
- 综合示例结果对比:
示例一
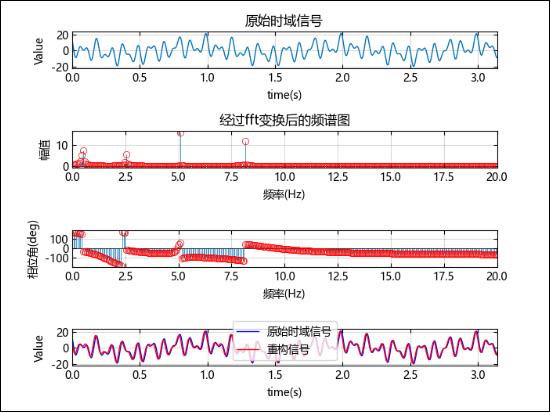
选取利用傅里叶变换将原始时域信号转换为频谱信号并重构过程作为示例一,对整个过程进行对比测试。
示例代码:
fun(x) = 5 * cos(1.9 * pi * x + pi / 4) + 3 * cos(4.97 * 2 * pi * x + pi / 6) + 8 * cos(10 * 2 * pi * x + pi / 3) + 6 * cos(15.99 * 2 * pi * x + pi / 3)
t_O = 0:1/1000:8 # 采样步长1/1000,采样时间为8s
y_O = fun.(t_O)
N_O = length(t_O) # 原始采样点数
# 数据采样处理
Fs = 256 # 信号采样频率,根据采样定理,信号采样频率应大于信号频率的2倍以上
t = LinRange(0, 5pi, Int(floor(Fs * 5pi))) # 采样点区间
N = length(t) - 1 # 采样点数
df = Fs / N #*频率分辨率
# FFT变换
f = Fs / N * (0:N-1)
YFFT = fft(y_O)
mag = abs.(YFFT) # 获取原始模值
phase = angle.(YFFT) * 180 / pi #*相位角
# 获取原始信号幅值
magy = mag / N
magy = magy[1:Int(N / 2 + 1)]
magy[2:end-1] = magy[2:end-1] * 2
subplot(4, 1, 1)
plot(t_O, y_O)
grid("on")
xlim([0, pi])
xlabel("time(s)")
ylabel("Value")
title("原始时域信号")
subplot(4, 1, 2)
stem(f[1:Int(N / 2)], magy[1:Int(N / 2)], "r", markeredgecolor="r")
xlabel("频率(Hz)")
ylabel("幅值")
title("经过fft变换后的频谱图")
grid("on")
xlim([0, 20])
subplot(4, 1, 3)
stem(f[1:Int(N / 2)], phase[1:Int(N / 2)], "r", markeredgecolor="r")
grid("on")
xlim([0, 20])
xlabel("频率(Hz)")
ylabel("相位角(deg)")
# 重构信号
fo1(t) = 4.96cos(6.03t + 0.56)
fo2(t) = 2.98cos(31.21t + 0.80)
fo3(t) = 7.83cos(62.82t + 1.42)
fo4(t) = 5.47cos(100.41t + 1.78)
yfft = fo1.(t_O) + fo2.(t_O) + fo3.(t_O) + fo4.(t_O)
# 绘制重构信号与原始信号对比图
subplot(4, 1, 4)
plot(t_O, y_O, "b")
hold("on")
plot(t_O, yfft, "r")
grid("on")
xlim([0, pi])
xlabel("time(s)")
ylabel("Value")
legend(["原始时域信号", "重构信号"])
hold("off")
tightlayout()
运行后图像:
排除绘图功能后代码:
fun(x) = 5 * cos(1.9 * pi * x + pi / 4) + 3 * cos(4.97 * 2 * pi * x + pi / 6) + 8 * cos(10 * 2 * pi * x + pi / 3) + 6 * cos(15.99 * 2 * pi * x + pi / 3)
t_O = 0:1/1000:8 # 采样步长1/1000,采样时间为8s
y_O = fun.(t_O)
N_O = length(t_O) # 原始采样点数
# 数据采样处理
Fs = 256 # 信号采样频率,根据采样定理,信号采样频率应大于信号频率的2倍以上
t = LinRange(0, 5pi, Int(floor(Fs * 5pi))) # 采样点区间
N = length(t) - 1 # 采样点数
df = Fs / N #*频率分辨率
# FFT变换
f = Fs / N * (0:N-1)
YFFT = fft(y_O)
mag = abs.(YFFT) # 获取原始模值
phase = angle.(YFFT) * 180 / pi #*相位角
# 获取原始信号幅值
magy = mag / N
magy = magy[1:Int(N / 2 + 1)]
magy[2:end-1] = magy[2:end-1] * 2
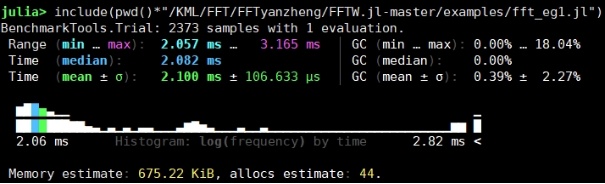
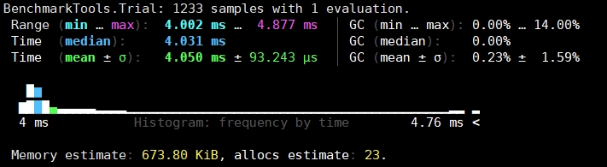
利用include加载文件、@benchmark宏对整体进行性能测试:
FFTW:
KML:
示例二
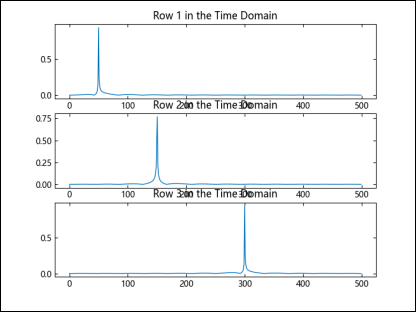
选取帮助文档中余弦波示例,比较时域和频域中的余弦波。
示例代码:
Fs = 1000
T = 1 / Fs
L = 1000
t = (0:L-1) * T
x1 = cos.(2 * pi * 50 * t)
x2 = cos.(2 * pi * 150 * t)
x3 = cos.(2 * pi * 300 * t)
X = hcat(x1, x2, x3)
for i = 1:3
ax = subplot(3, 1, i)
plot(ax, t[1:100], X[1:100, i])
title("Row $i in the Time Domain")
end
n = 2^nextpow2(L)
dim = 1
X = vcat(X, zeros(n - L, 3))
Y = fft(X, dim)
P2 = abs.(Y / L)
P1 = P2[1:Int(n / 2)+1, :]
P1[2:end-1, :] = 2 * P1[2:end-1, :]
for i = 1:3
ax = subplot(3, 1, i)
plot(ax, 0:(Fs/n):(Fs/2-Fs/n), P1[1:Int(n / 2), i])
title("Row $i in the Time Domain")
end
根据上述代码得到结果图像为:
排除绘图功能后代码:
function nextpow2(x)
if x == 0
return 0
end
n, f = nextpow2_alg(abs(x))
if f == 0.5
n -= 1
end
return n
end
function nextpow2_alg(x)
z = log2(x)
e = floor(Int, z) + 1
f = x / exp2(e)
return e, f
end
@benchmark begin
Fs = 1000
T = 1 / Fs
L = 1000
t = (0:L-1) * T
x1 = cos.(2 * pi * 50 * t)
x2 = cos.(2 * pi * 150 * t)
x3 = cos.(2 * pi * 300 * t)
X = hcat(x1, x2, x3)
n = 2^nextpow2(L)
dim = 1
X = vcat(X, zeros(n - L, 3))
Y = fft(X, dim)
P2 = abs.(Y / L)
P1 = P2[1:Int(n / 2)+1, :]
P1[2:end-1, :] = 2 * P1[2:end-1, :]
end
FFTW:
KML:
示例三
选取总数据量为一千万的向量、矩阵、三维数组分别测试在执行 fft(快速傅里叶变换)、傅里叶逆变换(ifft)后的精度和性能。
精度测试:
| 类型 | 示例 | KML | FFTW |
|---|---|---|---|
| 向量 | using Testrng = MersenneTwister(1234)a = rand(rng,100000000);@test isapprox(a,ifft(fft(a)),atol = 1e-8) | 通过 | 通过 |
| 矩阵 | using Testrng = MersenneTwister(1234)a = rand(rng,10000,10000);@test isapprox(a,ifft(fft(a)),atol = 1e-8) | 通过 | 通过 |
| 三维数组 | using Testrng = MersenneTwister(1234)a = rand(rng,10000,100,100);@test isapprox(a,ifft(fft(a)),atol = 1e-8) | 通过 | 通过 |
性能测试:
| 类型 | 示例 | KML | FFTW |
|---|---|---|---|
| 向量 | using Testrng = MersenneTwister(1234)a = rand(rng,100000000);@btime ifft(fft(a)); | 17.251 s (14 allocations: 4.47 GiB) | 16.171 s (56 allocations: 4.47 GiB) |
| 矩阵 | using Testrng = MersenneTwister(1234)a = rand(rng,10000,10000);@btime ifft(fft(a)); | 7.564 s (14 allocations: 4.47 GiB) | 15.733 s (58 allocations: 4.47 GiB) |
| 三维数组 | using Testrng = MersenneTwister(1234)a = rand(rng,10000,100,100);@btime ifft(fft(a)); | 12.792 s (14 allocations: 4.47 GiB) | 10.783 s (60 allocations: 4.47 GiB) |
示例四
傅里叶变换在工业应用中有一个常见场景:频谱分析。
频谱分析是通过对信号进行傅里叶变换,将信号从时域转换到频域,以获取信号中各个频率分量的信息。在工业领域中,频谱分析被广泛应用于以下方面:
- 故障诊断和预测:频谱分析可用于监测和分析机械系统、电气设备或其他工业设备的振动或声音信号。通过对信号进行频谱分析,可以检测到异常的频率分量,识别设备故障,并预测设备的寿命;
- 声学分析:频谱分析可用于处理声音信号,如音频处理、噪音分析和语音识别。通过分析声音信号的频谱特征,可以实现音频增强、噪音消除、声纹识别等应用;
- 通信系统:频谱分析在无线通信系统中起着重要作用。通过分析信号的频谱特征,可以确定信道的带宽、检测信号干扰、优化信号调制和解调方法等,以提高通信系统的性能和可靠性;
- 信号处理和滤波:频谱分析可用于信号处理和滤波应用。通过了解信号的频谱特征,可以设计滤波器来滤除不需要的频率分量,提取感兴趣的频率分量,实现信号的降噪、压缩、调制等处理操作。
示例三通过傅里叶变换获取信号的频谱信息,并对频谱进行分析。在这个示例中,我们首先定义了三个函数:generate_signal用于生成模拟信号,perform_fft用于对信号进行傅里叶变换,analyze_spectrum用于对频谱进行分析。我们生成了一个包含多个频率分量的模拟信号,并对信号进行傅里叶变换和频谱分析。最后,我们打印出信号的频率分析结果。
实际代码:
# 生成模拟信号
function generate_signal(t, freqs, amplitudes)
signal = zeros(length(t))
for i in 1:length(freqs)
signal += amplitudes[i] * sin.(2π * freqs[i] * t)
end
return signal
end
# 对信号进行傅里叶变换
function perform_fft(signal)
return fft(signal)
end
# 频谱分析
function analyze_spectrum(freqs, spectrum)
max_freq_index = argmax(abs.(spectrum[1:end ÷ 2])) # 只分析正频率部分
max_freq = freqs[max_freq_index]
return max_freq
end
# 工业应用实例
function industrial_application()
# 模拟信号参数
fs = 100000 # 采样频率
duration = 1000.0 # 信号时长
t = 0:1/fs:duration # 时间序列
# 信号频率和幅度
freqs = [50, 120, 250] # 信号频率
amplitudes = [1.0, 0.8, 0.5] # 信号幅度
# 生成模拟信号
signal = generate_signal(t, freqs, amplitudes)
# 傅里叶变换
spectrum = perform_fft(signal)
# 频谱分析
max_freq = analyze_spectrum(fftshift(fftfreq(length(signal), 1/fs)), spectrum)
println("工业应用实例:")
println("信号频率分量:", freqs)
println("信号频率分析结果:")
println("最大频率:", max_freq)
end
# 运行工业应用实例
industrial_application()
对industrial_application函数进行性能对比测试:
| KML | FFTW |
|---|---|
| 71.144 s (99 allocations: 11.55 GiB) | 72.269 s (121 allocations: 11.55 GiB) |
# 测试结论
截止 2023/05/30,通过对单元函数和综合示例测试,主要进行了傅里叶变换主要接库函数和利用fft函数撰写的两个综合示例在鲲鹏提供 Kunpeng-920 芯片、麒麟 V10 操作系统下进行性能测试,汇总统计如下:
- 性能测试目标函数 9 个;
- 单元测试用例 27 个,性能占优 9 个,基本持平 4 个,性能略差 14 个;
- 综合案例 4 类,测试用例 6 个,性能占优 1 个,基本持平 3 个,性能略差 2 个。
具体分析如下:
- 向量情况下,变换类函数如:
fft、ifft、bfft、dct,FFTW性能略高于KML; - 矩阵情况下,变换类函数如:
fft、ifft、bfft、dct,KML性能略高于FFTW; - 三维数组情况下,变换类函数如:
fft、ifft、bfft,r2r,KML性能略高于FFTW; - 实数变换
KML性能略高于FFTW,如:rfft、r2r; - 移位函数
FFTW性能略高于KML,如:fftshift、ifftshift。