# Julia 常见问题及最佳实践
# 概述
Julia 是一种为科学计算而生的、高性能的动态编译型语言,其独特的语言机制(如多重分派、类型系统等),为开发者提供了强大的灵活性,但也带来了特定的设计与实践挑战。本文主要介绍 Julia 语言工程应用中一些常见使用问题及对应的最佳实践。
在阅览本文之前,您需要掌握 Julia 的一些入门知识。如果您是首次接触 Julia,可以先学习 Julia 语言概览 或 Julia 中文文档。
# 变量作用域问题
Julia 变量作用域划分为全局作用域和局部作用域,具体如下:
- 全局作用域:每个模块会引进一个新全局作用域,与其他所有模块的全局作用域分开;
- 局部作用域:大多数代码块都引入了新的局部作用域。
- 硬作用域:当
x = <value>出现在某局部作用域,如果 x 还不是局部变量,则会在赋值作用域中创建一个名为 x 的新局部变量; - 软作用域:当
x = <value>出现在某局部作用域,如果 x 还不是局部变量,行为取决于全局变量 x 是否被定义:- 如果全局变量 x 是未定义,此次赋值会在该作用域创建一个名为 x 的新局部变量;
- 如果全局变量 x 是已定义,此次赋值会被认为是有歧义的: 在非交互的上下文(如脚本)中,会打印歧义警告,同时创建一个新局部变量; 在交互的上下文(如 REPL)中,会向全局变量 x 赋值。
- 硬作用域:当
| 结构 | 作用域类型 | 允许使用在 |
|---|---|---|
| module, baremodule | 全局 | 全局 |
| struct | 局部(硬) | 全局 |
| for, while, try | 局部(软) | global, local |
| macro | 局部(硬) | 全局 |
| 函数、do 语句块、let 语句块、数组推导、生成器 | 局部(硬) | global, local |
关于变量作用域的详细帮助,请参考 Syslab 帮助文档的变量作用域章节。
易出错的代码示例:
s = 0
for i = 1:10
s = s + i # 报错:出现歧义,s 未定义
end
println(s)
上述代码,在 Julia REPL 中直接运行,可以得到正确结果。但是,如果将该代码保存为脚本去运行,将出现报错:
┌ Warning: Assignment to `s` in soft scope is ambiguous because a global variable by the same name exists: `s` will be treated as a new local. Disambiguate by using `local s` to suppress this warning or `global s` to assign to the existing global variable.
└ @ f:\Syslab\MwSyslab\04 详细设计\预研\预研-工程化问题(长期)\Julia语言机制问题类最佳实践\Unnamed.jl:3
ERROR: UndefVarError: `s` not defined
Stacktrace:
[1] top-level scope
@ f:\Syslab\MwSyslab\04 详细设计\预研\预研-工程化问题(长期)\Julia语言机制问题类最佳实践\Unnamed.jl:3
我们可以将上述代码修正如下,这样就消除歧义。
s = 0
for i = 1:10
global s # 声明全局变量
s = s + i # ok
end
println(s) # 输出55
但是,如果 for 循环在函数作用域内,则可以访问外部局部变量。
function myfunc()
s = 0
for i = 1:10
s = s + i # ok:赋值现有局部变量
end
println(s)
end
myfunc() # 输出55
此外,在 for 循环中修改数组分量,则也是允许的。
ss = [0]
for i = 1:10
ss[1] = ss[1] + i # ok:允许修改数组分量
end
println(ss[1]) # 输出55
# 函数返回多值
Julia 函数允许返回 1 个或多个结果值。当函数返回多个结果值时,将以元组形式返回。
易出错的代码示例:
function myfunc(x)
y1 = x
y2 = 2*x
y3 = 3*x
return y1,y2,y3
end
res = myfunc(1.0) # 本想得到第一个返回值,但是返回了全部值,即元组(1.0, 2.0, 3.0)
如果用户只想获取第一个返回值,则需要使用,来获取元组分量,如下所示:
res_1, = myfunc(1.0) # res_1 等于 1.0
res_1, res_2 = myfunc(1.0) # res_2 等于 2.0
res_1, res_2, res_3 = myfunc(1.0) # res_3 等于 3.0
res_1, res_23... = myfunc(1.0) # res_23 等于 (2.0, 3.0)
# 严格区分向量与行/列矩阵
在 Julia 语言中,严格区分 向量(n 个元素集合)、行矩阵(1xn 矩阵)、列矩阵(nx1 矩阵),其声明如下所示:
vec_1 = Float64[1, 2, 3] # 向量
vec_2 = Float64[1; 2; 3] # 向量
mtx_row = Float64[1 2 3] # 1x3 行矩阵
mtx_col = Float64[1;2;3;;] # 3x1 列矩阵
mtx = [1 2 3; 4 5 6] # 2x3 矩阵
mtx_2 = [1,2,3; 4,5,6] # error:非法
向量与行、列矩阵之间不能自动转换,需要手工显式转换。
# 矩阵 转 向量
vec(mtx_row)
# 向量 转 行矩阵
reshape(vec_1, 1, 3)
# 向量 转 列矩阵
reshape(vec_1, 3, 1)
# 数组构造与数组拼接容易混淆
数组也可以直接用方括号来构造。语法[A, B, C, ...]创建一个一维数组,该一维数组的元素用逗号分隔。
[1, 2, 3] # 元素类型为 Int 的向量
[1:2, 4:5] # 这里有一个逗号,因此并不会发生矩阵的拼接
#=
2-element Vector{UnitRange{Int64}}:
1:2
4:5
=#
如果方括号里的参数不是由逗号分隔,而是由单个分号(;) 或者换行符分隔,那么每一个参数就不再解析为一个单独的数组元素,而是纵向拼接起来。
[1:2; 4:5] # 纵向拼接
#=
4-element Vector{Int64}:
1
2
4
5
=#
[1:2
4:5]
#=
4-element Vector{Int64}:
1
2
4
5
=#
类似的,如果这些参数是被制表符、空格符或者两个分号所分隔,那么它们的内容就横向拼接在一起。
[1:2 4:5 7:8] # 横向拼接
#=
2×3 Matrix{Int64}:
1 4 7
2 5 8
=#
[[1,2] [4,5] [7,8]]
#=
2×3 Matrix{Int64}:
1 4 7
2 5 8
=#
[1 2 3] # 数字可以被横向拼接
#=
1×3 Matrix{Int64}:
1 2 3
=#
[1;; 2;; 3;; 4]
#=
1×4 Matrix{Int64}:
1 2 3 4
=#
注意,数组拼接存在一定的时间开销,如下所示:
# 方式 1:数组拼接
function f1(n)
x = Int[]
for i in 1:n
x = [x; i] # 注意:不要使用逗号
end
return x
end
# 方式 2:原地修改数组
function f2(n)
x = Int[]
for i in 1:n
push!(x, i)
end
return x
end
# 方式 3:数组推导
f3(n) = [i for i in 1:n]
@time x1 = f1(10000) # 0.193791 seconds(性能最差)
@time x2 = f2(10000) # 0.000117 seconds(性能尚可)
@time x3 = f3(10000) # 0.000035 seconds(性能最好)
# 数组索引不支持浮点数
与 MATLAB 不同,索引 n 维数组A的一般语法是:X = A[I_1, I_2, ..., I_n],其中每个I_k可以是标量整数,整数数组或任何其他支持的索引类型。这包括Colon(:)选择整个维度中的所有索引,形式为a:c或a:b:c的范围来选择连续或跨步的子区间,以及布尔数组以选择索引为true的元素。
x = [1 2 3; 4 5 6]
x[1.0] # error:数组下标不允许浮点数
x[Int(1.0)] # ok
x[1] == x[begin] # 首个数组元素
x[6] == x[end] # 最后一个数组元素
x[1,2] # 2
x[1, :] # 第一行数据,即[1, 2, 3]
x[1:2, 2:3]
#=
2×2 Matrix{Int64}:
2 3
5 6
=#
# Int 与 Float64 类型转换
Julia 类型系统融合了动态语言的灵活性与静态语言的性能优势,它允许变量动态绑定类型,同时通过严格的类型检查和显式转换要求,避免隐式错误、提升代码质量,并为高性能优化提供基础。
Julia 类型转换的显式要求也带来一些不便,如整型与浮点型需要显式转换:
function f_int(x::Int)
return x
end
function f_float(x::Float64)
return x
end
f_int(1)
f_int(1.0) # error:无法自动转换
f_float(1) # error:无法自动转换
f_float(1.0)
当然,Julia 也提供了显式转换方法,如下所示:
# 浮点转整型
x = Int(1.0)
x2 = convert(Int, 1.0)
x3 = convert(Int, 1.5) # error
# 整型转浮点
y = Float64(1)
y2 = convert(Float64, 1)
此外,对于ones、round、zeros、floor、ceil等函数,支持通过传递类型参数来实现从浮点到整型的一次性转换完成。
round(2.6) # 3.0
round(Int, 2.6) # 3
floor(2.6) # 2.0
floor(Int, 2.6) # 2
ceil(2.6) # 3.0
ceil(Int, 2.6) # 3
ones(2,3) # 2×3 Matrix{Float64} 全1矩阵
ones(Int, 2, 3) # 2×3 Matrix{Int64} 全1矩阵
zeros(2,3) # 2×3 Matrix{Float64} 全0矩阵
zeros(Int, 2,3) # 2×3 Matrix{Int64} 全0矩阵
# 了解类型系统
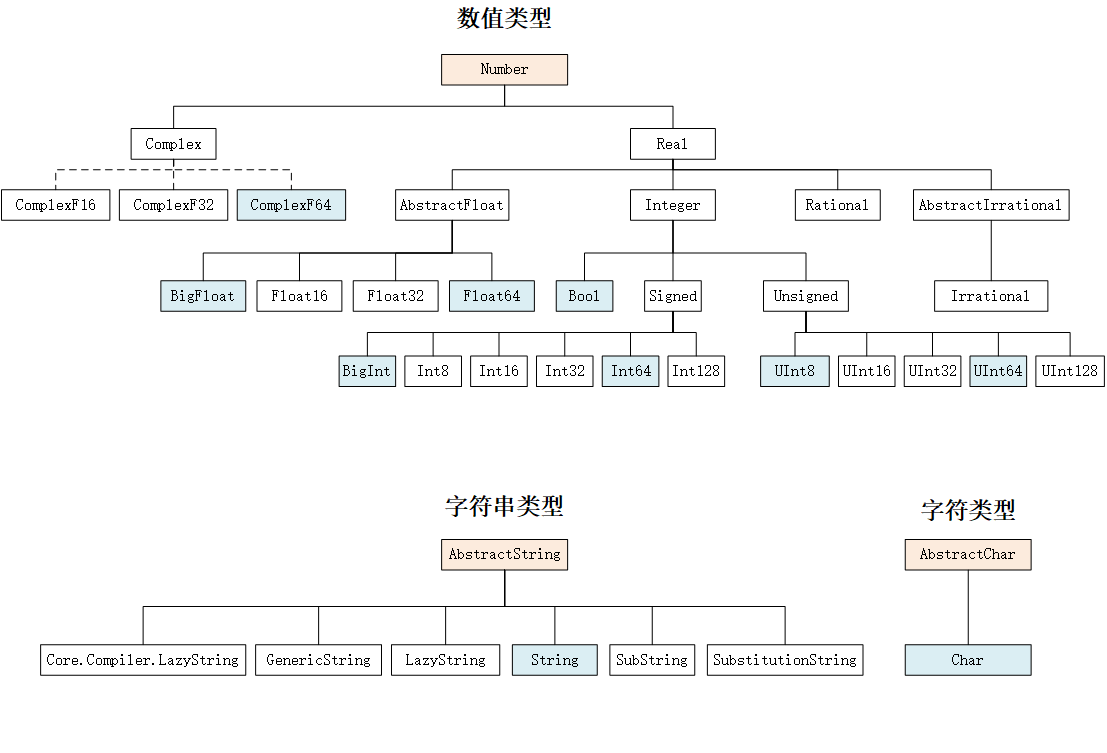
类型系统和多重派发是 Julia 语言最主要的特征,了解类型系统对掌握 Julia 语言很有帮助。对于初学者而言,至少需要掌握常用基础类型、数组类型、类型继承关系、类型判断、类型标注等基础知识。
常用的基础类型,包括数值类型、字符串类型、字符类型等,类系图如下所示:
- 对于 64 位系统,
Int是Int64的别名,但不存在Float类型; ComplexF16、ComplexF32、ComplexF64分别是Complex{Float16}、Complex{Float32}、Complex{Float64}的别名。
- 对于 64 位系统,
常用的数组类型,包括
Vector、Matrix、Array等,这些类型都是从AbstractArray派生的。Vector{T}其实是Array{T,1}的别名;Matrix{T}其实是Array{T,2}的别名。
通过
subtypes与supertype两个函数,可以查看一个类型的子类和父类。# 查看所有子类 subtypes(Signed) #= 6-element Vector{Any}: BigInt Int128 Int16 Int32 Int64 Int8 =# # 查看父类 supertype(Int) # Signed通过
isa、<:可以进行类型判断。isa(1, Int) # true 1 isa Number # true Float64 <: AbstractFloat # true Matrix{Float64} <: AbstractArray # true Matrix{Float64} <: AbstractArray{Float64} # true Matrix{Float64} <: AbstractArray{AbstractFloat} # 注意:返回 false对于结构体或函数,建议标注类型,这可以给编译器提供额外的类型信息,有助于提升程序性能。
# 结构体字段标注类型 struct PointF x::Float64 y::Float64 end # 函数参数标注类型 function myplus(x::Int, y::Int) x+y end # 函数返回值标注类型:返回值始终会被转换为Float64 function mysinc(x)::Float64 if x == 0 return 1 end return sin(pi*x)/(pi*x) end
关于类型系统的更多介绍,请参见 Syslab 帮助文档的类型系统相关章节。
# round 函数舍入问题
在实际工程中,经常有人会问,为什么 Julia 的 round 函数计算结果与 MATLAB 不一致?
例如:
# 默认情况下,两者存在差异
round(0.5) # Julia 返回 0.0,Matlab 返回 1
round(1.5) # Julia 返回 2.0,Matlab 返回 2
对于上述示例,Julia 和 MATLAB 计算结果都是正确的,不一致的根因是它们默认采用的圆整算法不一致。
Julia 中,round(X)按照默认的四舍五入模式将X舍入为整数值,并返回与 X 相同类型的值。默认情况下这将四舍五入到最近的整数,如果出现平局(with ties,即小数值为 0.5),则会被舍入为最近的偶数整数。
MATLAB 中,round(X)将X的每个元素四舍五入为最近的整数。在对等情况下,即有元素的小数部分恰为0.5时,round函数会偏离零四舍五入到具有更大幅值的整数。
尽量 Julia 和 Matlab 的默认行为不同,但是都有方法来控制四舍五入算法,如下:
- 对于 Julia,存在以下参数控制:
- RoundNearest (default)
- RoundNearestTiesAway:rounded away from zero in Julia(与 MATLAB 缺省参数等价)
- RoundNearestTiesUp
- RoundToZero
- RoundFromZero (BigFloat only)
- RoundUp
- RoundDown
- 对于 Matlab,存在
TieBreaker关键字参数控制(Matlab R2022a 引入):- fromzero (default)
- tozero
- even
- odd
- plusinf
- minusinf
在 Julia 中:
# 默认情况下,两者存在差异
round(0.5) # Julia 返回 0.0,Matlab 返回 1
round(1.5) # Julia 返回 2.0,Matlab 返回 2
# 与 Matlab 等价的 round 用法
round(0.5, RoundNearestTiesAway) # 1.0
round(1.5, RoundNearestTiesAway) # 2.0
round(Int, 0.5, RoundNearestTiesAway) # 1
round(Int, 1.5, RoundNearestTiesAway) # 2
# 赋值与拷贝
科学计算语言,有的语言采用按值传递(Call by value),有的语言采用按共享调用(Call by sharing)。例如,MATLAB 采用按值传递(Call by value),这样做可以防止数组在被调函数中被意外地篡改,但这也会导致不必要的数组拷贝。目前,大多数现代语言都采用按共享调用(Call by sharing),包括 Java、Python、Ruby 等,Julia 也是如此。
Julia 的赋值操作实质上是变量绑定,即将一个变量存储的其变量值对象的地址赋给一个变量,如下图所示:
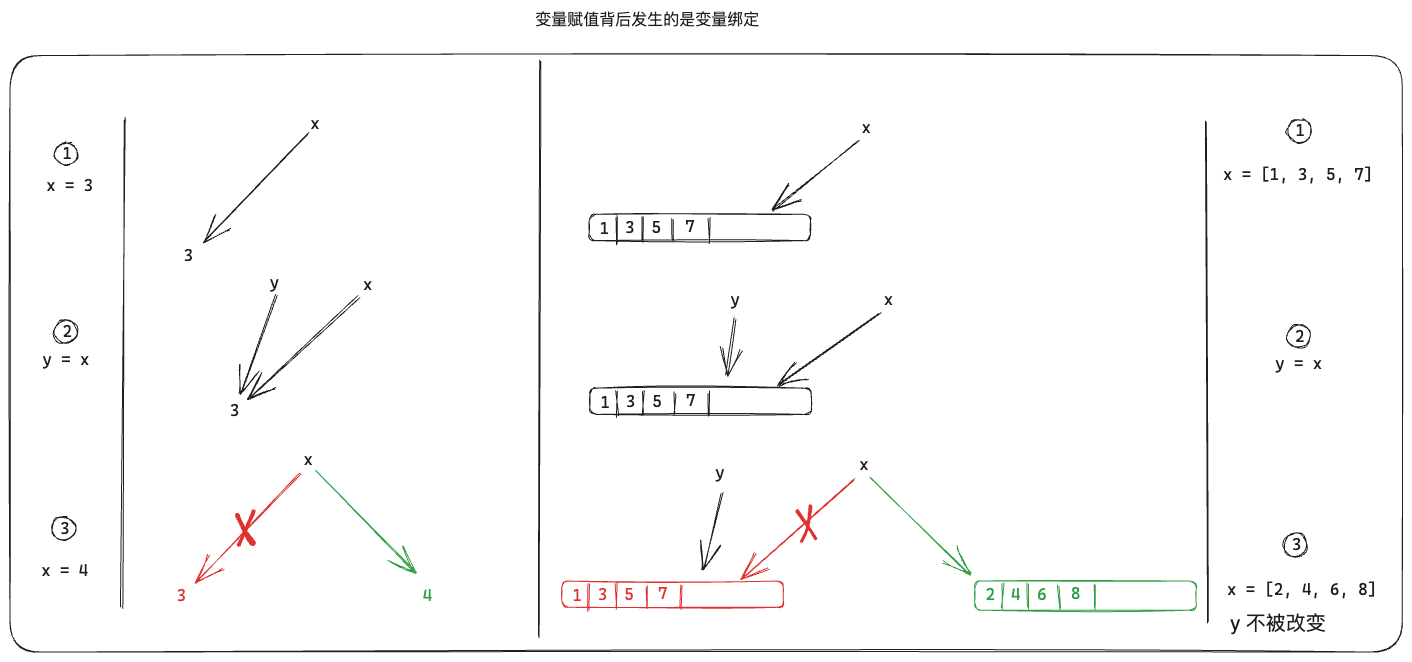
对于一些基础类型,包括Number、Tuple、String等,由于其对象的值不可更改(如字符串),所以在赋值与传参时,表现上与按值传递没有区别,感觉像拷贝。
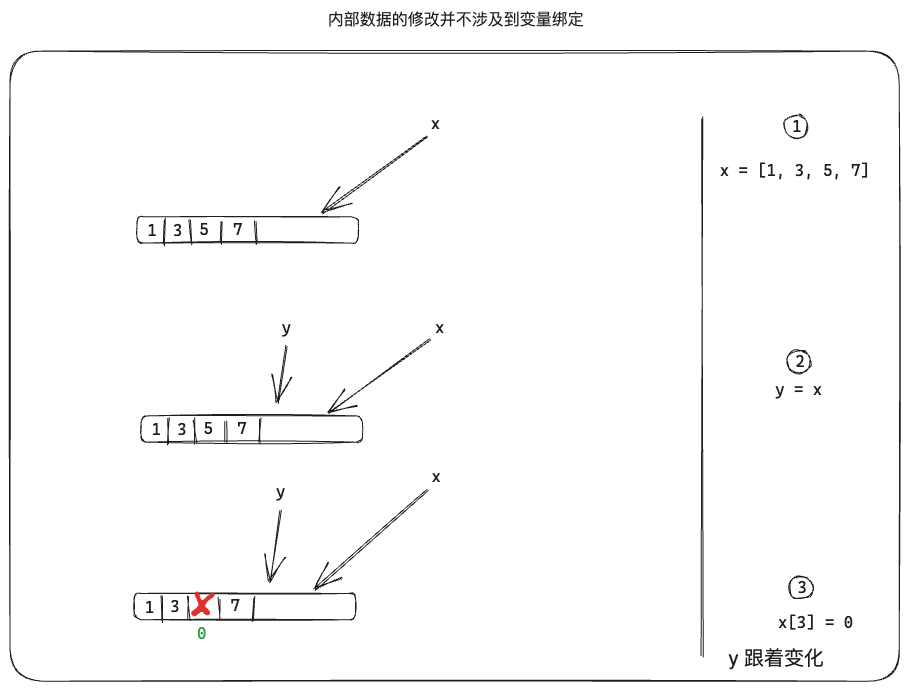
对于一些可变复合类型(使用ismutable判断),包括数组、字典、可变结构体等,若内部数据被修改了,所有共享该对象的变量都会跟着变化,如下图所示。
为了方便大家使用,我们对 Julia 数组操作的一些典型使用场景,进行了梳理归纳,具体如下:
| 典型场景 | 说明 | 举例 |
|---|---|---|
| 数组赋值 | 共享底层数据 | a = [1,2,3]b = aa[1] = 10b # 输出:[10, 2, 3] |
| 数组切片 | 拷贝 | a = [1 2 3;4 5 6]b = a[1,:]a[1] = 10b # 输出:[1, 2, 3] |
| 数组视图 @view | 共享底层数据 | a = [1 2 3;4 5 6]b = @view a[1,:]a[1] = 10b # 输出:[10, 2, 3] |
| reshape | 共享底层数据 | a = [1,2,3,4]b = reshape(a, 2, 2)a[1] = 10b # 输出:[10 3; 2 4] |
| collect | 拷贝 | a = [1,2,3,4]b = collect(a)a[1] = 10b # 输出:[1, 2, 3, 4] |
| vec | 共享底层数据 | a = [1 2; 3 4]b = vec(a)a[1] = 10b # 输出:[10, 3, 2, 4] |
| 共轭转置:', adjoint | 共享底层数据 | a = [3+2im 9+2im; 0 0]b = a'a[1] = 10b # 输出:[10+0im 0; 9-2im 0] |
| 转置:transpose | 共享底层数据 | a = [3+2im 9+2im; 0 0]b = transpose(a)a[1] = 10b # 输出:[10+0im 0; 9+2im 0] |
| 实数共轭:conj | 共享底层数据 | a=[1 2 ;3 4]b=conj(a)a[1] = 10b # 输出:[10 2; 3 4] |
| 复数共轭:conj | 拷贝 | a = [3+2im 9+2im; 0 0]b = conj(a)a[1] = 10b # 输出:[3-2im 9-2im; 0 0] |
| copy | (浅)拷贝 | a = [1, [2, 3]]b = copy(a)b[1] = 100 # 修改顶层元素(不会影响a)b[2][1] = 200 # 修改内部元素(会影响a)println(a) # 输出:[1, [200, 3]]println(b) # 输出:[100, [200, 3]] |
| deepcopy | (深)拷贝 | a = [1, [2, 3]]b = deepcopy(a)b[1] = 100 # 修改顶层元素(不会影响a)b[2][1] = 200 # 修改内部元素(不会影响a)println(a) # 输出:[1, [2, 3]]println(b) # 输出:[100, [200, 3]] |
# 字符串索引及常用操作
在 Julia 中,字符串是不可变类型,但是可以通过其它方式实现类似可变字符串效果。本节主要介绍字符串遍历、拼接、插值、格式化、解析与转换等一些常用基础知识。关于字符串的更多操作,请参见 Syslab 帮助文档的 Julia 语言概览中的字符与字符串章节。
字符串遍历:在 Julia 中遍历字符串时,由于字符串可能包含多字节字符(如 UTF-8 编码),索引操作需要特别注意。
str = "Hello, 世界!" for i in 1:length(str) println(str[i]) # error:无效索引 end for i in eachindex(str) println("索引 $i: 字符 $(str[i])") # ok end字符串拼接:在 Julia 中,有多种方法实现字符串拼接。
# 方法1(性能最好) str = "value: " * string(pi/2) # "value: 1.5707963267948966" # 方法2 str = "value: $(pi/2)" # 方法3 str = join(["value:", pi/2], " ") # 方法4 str = string("value: ", pi/2)字符串格式化
可以使用
Printf.@sprintf对字符串进行格式化,其函数声明如下:@sprintf("%Fmt", args...)其中,
%Fmt类似 C 语言 printf (opens new window) 的 format 格式,完整格式是**%[flags][width][.precision][length]specifier**。using Printf str = (@sprintf "%s is %.2f" "value" 34.567) # "value is 34.57" str = (@sprintf "%s is %6.2f" "value" 34.567) # "value is 34.57" str = (@sprintf "value is %.2e" 1.23456) # "value is 1.23e+00" str = (@sprintf "value is %.2f" 1.23456) # "value is 1.23" str = (@sprintf "value is %#x" 100) # "value is 0x64"字符串与数值类型的转换
通过
string函数,可以将任意类型转为字符串。string(1.23) # "1.23" string(255, base=16) # "ff" string("a", 1, true) # "a1true"通过
parse函数,可以将字符串转为数值类型。parse(Int, "0b1000") # 8 parse(Int, "0o10") # 8 parse(Int, "0xff") # 255 parse(Int, "ff", base=16) # 255 parse(Float64, "1.2e-3") # 0.0012 parse(Complex{Float64}, "3.2 + 4.5im") # 3.2 + 4.5im字符串路径
对于 Windows 和 Linux 来说,路径分隔符分别为 '\' 和 '/'。从跨平台兼容角度,可以使用
joinpath或Base.Filesystem.path_separator来实现跨平台处理。# 方法1: myfile = joinpath(@__DIR__, "myfile.txt") # 方法2: myfile = string(@__DIR__) * Base.Filesystem.path_separator * "myfile.txt"
# 避免全局变量
全局变量的值和类型随时都会发生变化, 这使编译器难以优化使用全局变量的代码。
# 采用全局变量
global g_x = 1000
function f_global()
s = 0.0
for i in 1:g_x
s += i
end
return s
end
变量应该是局部的,或者尽可能作为参数传递给函数。
# 采用参数传递
function f_local(x::Int)
s = 0.0
for i in 1:x
s += i
end
return s
end
如果确实需要使用全局变量,可以将其改为常量+引用。这样既保持常量特性,又允许修改其值,如DEFAULT_X[] = 3。
# 采用全局常量
const DEFAULT_X = Ref(1000)
function f_const()
s = 0.0
for i in 1:DEFAULT_X[] # []表示解引用
s += i
end
return s
end
三者性能对比如下,全局变量性能最差。
using BenchmarkTools
@btime f_global() # 46.200 μs(性能最差)
@btime f_local(1000) # 823.944 ns
@btime f_const() # 829.487 ns
# 融合向量化操作
Julia 有特殊的点语法,它可以将任何标量函数转换为「向量化」函数调用,将任何运算符转换为「向量化」运算符,其具有的特殊性质是嵌套「点调用」是融合的:它们在语法层级被组合为单个循环,无需分配临时数组。如果你使用.=和类似的赋值运算符,则结果也可以 in-place 存储在预分配的数组。
在线性代数的上下文中,这意味着即使诸如vector + vector和vector * scalar之类的运算,使用vector .+ vector和vector .* scalar来替代也可能是有利的,因为生成的循环可与周围的计算融合。
例如,考虑两个函数:
f(x) = 3x.^2 + 4x + 7x.^3;
fdot(x) = @. 3x^2 + 4x + 7x^3; # equivalent to 3 .* x.^2 .+ 4 .* x .+ 7 .* x.^3
f和fdot都做相同的计算。但是,fdot(在@.宏的帮助下定义)在作用于数组时明显更快:
x = rand(10^6);
@time y1 = f(x); # 0.010712 seconds(慢)
@time y2 = fdot(x); # 0.001999 seconds(快)
@time y3 = f.(x); # 0.001757 seconds(快)
y1 == y2 == y3 # true
# 类型稳定
Julia 代码编译期间只能够获得类型信息,而无法获得值信息。
类型稳定的理解:
- 理解 1:函数的返回值类型在不同情况下是不变的
- 理解 2:函数的返回值(及中间结果)类型可以通过函数输入的类型来唯一推断
类型稳定的检测:
- 使用 @code_warntype 来验证类型不稳定行为
类型不稳定会导致:
- Julia 编译器难以做充足的编译优化
- 额外的运行时类型检查和开销
- 类型不稳定往往影响的是函数调用者的性能
例如,对浮点型矩阵A求和,以下代码的返回值类型有多种情况,属于类型不稳定。
# 类型不稳定
function mysum(A)
rst = 0 # 当 A 为空时,返回整型;当 A 不为空时,返回浮点型
@simd for i in eachindex(A)
rst += A[i]
end
return rst
end
通过以下修改,可以使其变成类型稳定:
# 类型稳定
function mysum_stable(A)
rst = zero(eltype(A)) # 构造与 A 元素类型相同的 0
@simd for i in eachindex(A)
rst += A[i]
end
return rst
end
两者性能对比:
using BenchmarkTools
A = rand(1024,1024)
@btime mysum($A) # 876.700 μs(慢)
@btime mysum_stable($A) # 135.300 μs(快)
关于类型稳定的更多细节,请参见 Syslab 帮助文档的 Julia 高性能编程中的类型稳定章节。
# 多线程使用问题
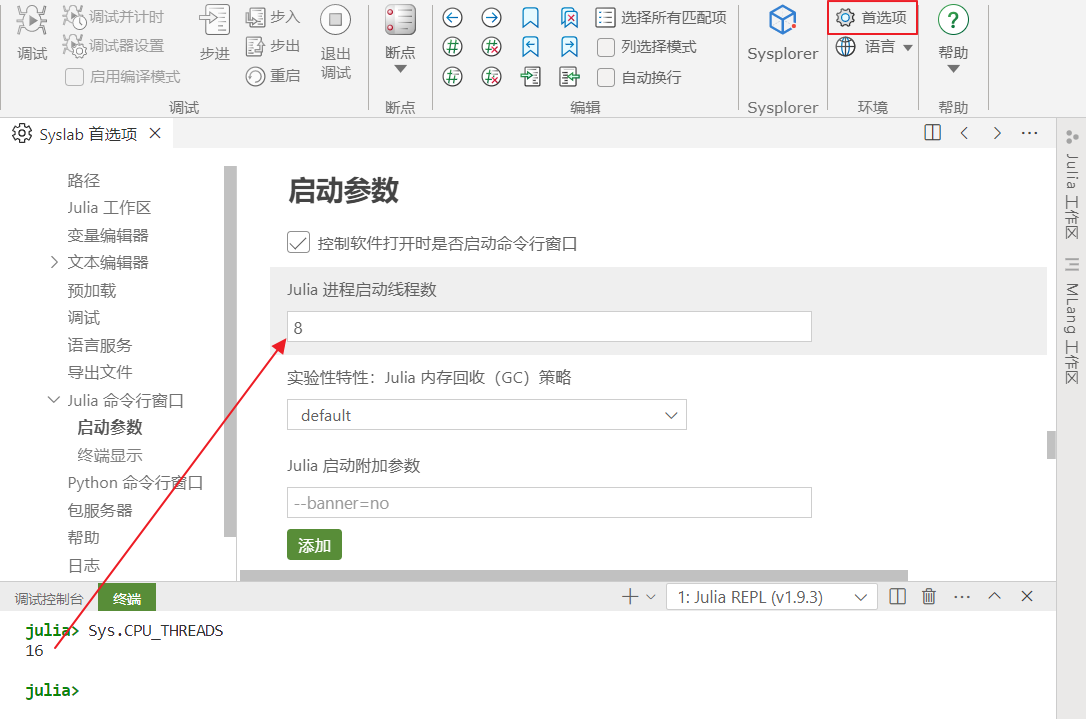
Julia 提供了丰富的并行计算能力,包括异步计算、多线程计算、多进程计算、GPU 及异构计算。其中,多线程计算使用较为普遍。在使用多线程加速前,设置 Julia 启动线程数,一般推荐设置为计算机线程数的一半。
首先,打开 Syslab,在 Julia 命令行窗口中输入Sys.CPU_THREADS可以查看计算机线程数;其次,打开首选项页面,设置 Julia 启动线程数,一般设置为计算机线程数的一半,设置完成后需要重启命令行窗口生效。
通过在 for 循环添加Threads.@threads即可将其变成多线程执行代码。
注意:使用多线程并行加速,要求每个线程的迭代操作相互独立,避免数据竞争。
using TyPlot
using TyImageProcessing
# 加载图像
img = imread("corn.tif");
h, w = size(img)
# 预分配内存
gray_img = Matrix{Float64}(undef, h, w)
# 使用多线程
Threads.@threads for i in 1:h
for j in 1:w
# 获取原图像素
pixel = img[i, j, :] ./ 255
# 计算灰度值(每个线程操作不同位置,无竞争)
gray_img[i, j] = 0.299 * pixel[1] + 0.587 * pixel[2] + 0.114 * pixel[3]
end
end
# 显示原图与灰度图
subplot(1, 2, 1)
imshow("corn.tif")
subplot(1, 2, 2)
imshow(gray_img)
关于 Julia 并行计算能力,详细请参见 Syslab 帮助文档的并行计算工具箱。
# 函数重名问题
考虑两个或更多包导出相同名称的情况,如:
module ModeA
export myadd
function myadd(a, b)
return a + b
end
end
module ModeB
export myadd
function myadd(a::AbstractString, b::AbstractString)
return a * b
end
end
using .ModeA
using .ModeB
x = myadd(3, 4) # error:myadd 未定义
运行报错:
WARNING: both ModeB and ModeA export "myadd"; uses of it in module Main must be qualified
ERROR: UndefVarError: `myadd` not defined
Stacktrace:
[1] top-level scope
@ f:\Syslab\MwSyslab\04 详细设计\预研\预研-工程化问题(长期)\Julia语言机制问题类最佳实践\函数重名问题.jl:18
有两种解决方法:
方法 1:使用限定名称,如下所示:
x = ModeA.myadd(3, 4) # 返回7 y = ModeB.myadd("3", "4") # 返回"34"方法 2:如果不想修改调用点,可以使用导入指定模块的指定函数,如下所示:
using .ModeA using .ModeB using .ModeA: myadd # 导入特定函数 x = myadd(3, 4) # 返回7(此时调用的是 ModeA.myadd)
# 结构体如何重定义
在 Julia 中,结构体(struct)是常量,而常量不可修改,导致结构体无法重定义,否则报错。例如:
struct MyPoint
x::Float64
y::Float64
end
运行后,如果想将其修改为三维点,增加一个字段z,则会报错:
struct MyPoint
x::Float64
y::Float64
z::Float64
end
此时会报错:
ERROR: invalid redefinition of constant MyPoint
为了使得修改生效,不得不重启 Julia 命令行窗口,非常不方便。
为了解决这个问题,在结构体定义修改期间,可以使用结构体+变量的组合方式,来避免反复重启 Julia 命令行窗口。
# 结构体使用临时名称
mutable struct MyPoint2
x::Float64
y::Float64
end
# 定义一个变量(采用结构体真实名称)
MyPoint = MyPoint2
isconst(Main, :MyPoint) # false,变量
isconst(Main, :MyPoint2) # true,常量
pt = MyPoint(3,4)
假设此时需要将二维点修改为三维点,可以这么做(此时无需重启 Julia 命令行窗口):
# 修改结构体临时名称
mutable struct MyPoint3
x::Float64
y::Float64
z::Float64
end
# 变量指向修改后的结构体
MyPoint = MyPoint3
pt = MyPoint(3,4,5)
如此,待结构体定义完全定型后,可以注释掉中间变量,恢复结构体真实名称。
# 需要重启 REPL
# 恢复结构体真实名称
mutable struct MyPoint
x::Float64
y::Float64
z::Float64
end
# MyPoint = MyPoint3
pt = MyPoint(3,4,5)
# 结构体初始化
Julia 结构体可以通过new来进行默认初始化,但是不直观。
mutable struct PointF
x::Float64
y::Float64
PointF() = new(0, 0) # 无参构造函数
end
pt = PointF()
可以通过Base.@kwdef来构造参数化结构体,如下所示:
@kwdef mutable struct PointF
x::Float64 = 0
y::Float64 = 0
end
pt = PointF() # 输出 PointF(0.0, 0.0)
pt2 = PointF(3,4) # 输出 PointF(3.0, 4.0)
pt3 = PointF(y=1) # 输出 PointF(0.0, 1.0)
# 读取 jld2 文件兼容旧版本结构体
在 Julia 中,会出现将结构体保存为 jld2 文件,但在后续开发中,结构体的成员发生了改变,会导致读取 jld2 文件后,读取的结构体无法匹配最新的结构体。
例如,定义一个 v1 版本的 Person 结构体,并创建实例 person1 将其保存至 person1.jld2 文件中。
# v1 版本 Person
@kwdef struct Person
name::String = ""
age::Int = 0
email::String = ""
end
person1 = Person(name="张三", age=24, email="zhangsan@email.com");
using TyBase
save("person1.jld2"; person1);
此时,重启 Julia 命令行窗口,定义一个 v2 版本的 Person 结构体,然后读取上述的 person1.jld2 文件。
# @kwdef 宏用于给结构体构造创建默认值
@kwdef struct Health
height::Float64 = 0.0
weight::Float64 = 0.0
end
# v2 版本 Person
@kwdef struct Person
name::String = ""
age::String = "0"
health::Health = Health()
end
using TyBase
load("person1.jld2");
show(person1) # Reconstruct@Person(Any["张三", 24, "zhangsan@email.com"]);
可以看到由于两个版本的 Person 结构体发生了改变,所以读取 jld2 文件后,创建了一个默认类型的结构体。
下述代码提供一个转换函数,将读取出的默认类型的结构体转换为 v2 版本的 Person 结构体。
"""
将 jld2 文件中导入的默认结构体转换为指定类型的结构体,要求指定类型的结构体有默认构造函数
convert_to_target_type(target_type, source_struct)
输入:
target_type:需要转换的结构体类型
source_struct: 结构体实例
"""
function convert_to_target_type(target_type, source_struct)
target_fields = fieldnames(target_type)
args = Dict{Symbol,Any}()
for field in target_fields
if field in propertynames(source_struct)
value = getproperty(source_struct, field)
try
convert(fieldtype(target_type, field), value)
args[field] = value
catch err
@warn "字段 $field 类型不匹配"
end
end
end
target = target_type(; args...)
return target
end
v2_person1 = convert_to_target_type(Person, person1)
show(v2_person1) # Person("张三", "0", Health(0.0, 0.0))
对于变量名和类型匹配的成员 name 属性,成功进行了转换,对于修改了类型的 age 属性和新增的 Health 属性,使用了默认值,对于删除的 email 属性,进行了忽略。成功将 jld2 文件中读取的默认结构体转换成 v2 版本的 Person 类型的结构体。
# 以 ! 结尾的函数
在 Julia 中,以!结尾的函数名是一种约定俗成的命名规范,用于表示该函数会直接修改其输入参数(即“就地修改”)。这种命名习惯有助于代码的可读性和安全性,让用户能够快速区分哪些函数会改变原始数据。
例如:
# 不修改原数组的函数
original = [3, 1, 2]
sorted = sort(original) # 返回新的排序数组
println(sorted) # 输出 [1, 2, 3]
println(original) # 输出 [3, 1, 2]
# 修改原数组的函数
sort!(original) # 直接排序原数组
println(original) # 输出 [1, 2, 3]
自定义!函数。例如:
# 不修改原数组的函数
function double(x::Vector)
return 2 .* x # 返回新数组
end
# 修改原数组的函数
function double!(x::Vector)
x .*= 2 # 直接修改原数组
return x # 通常返回修改后的原数组
end
a = [1, 2, 3]
b = double(a)
println(a) # 输出 [1, 2, 3]
println(b) # 输出 [2, 4, 6]
double!(a)
println(a) # 输出 [2, 4, 6](原数组被修改)
# 模拟 MATLAB 结构体
一般情况下,推荐使用 Julia 原生数据类型,可以获取更好编译器优化和性能。但是,在某些场景下,用户想拥有一个类似 MATLAB 效果的结构体,具备通过使用圆点表示法动态添加字段等功能,可以参考以下实现。
# 模拟 MATLAB 结构体
struct mstruct
_data::Dict{Symbol,Any}
mstruct() = new(Dict{Symbol,Any}())
function mstruct(; kwargs...)
data = Dict{Symbol,Any}()
for (k, v) in kwargs
data[k] = v
end
new(data)
end
end
function Base.getproperty(obj::mstruct, name::Symbol)
data = getfield(obj, :_data)
return data[name]
end
function Base.setproperty!(obj::mstruct, name::Symbol, value)
data = getfield(obj, :_data)
data[name] = value
end
function Base.show(io::IO, obj::mstruct)
data = getfield(obj, :_data)
println(io, "mstruct with fields: ")
ks = collect(keys(data))
sort!(ks)
for k in ks
v = data[k]
print(io, " ", k , ": ")
if v isa AbstractArray
println(io, "[size: ", size(v), ", type: ", typeof(v), "]")
else
println(io, v)
end
end
end
Base.propertynames(obj::mstruct) = keys(getfield(obj, :_data))
function Base.delete!(obj::mstruct, field::Symbol)
data = getfield(obj, :_data)
delete!(data, field)
return obj
end
我们不妨测试一下:
using TyPlot
# 动态添加字段
data = mstruct()
data.x = LinRange(0, 2 * pi, 100);
data.y = sin.(data.x);
data.z = Float64[]
data.title = "y = sin(x)"
# 动态删除字段
delete!(data, :z)
# 画图
plot(data.x, data.y)
title(data.title)
# 打印
println(data)
运行后,成功绘制正弦图,并输出结构体内容,如下所示:
mstruct with fields:
title: y = sin(x)
x: [size: (100,), type: LinRange{Float64, Int64}]
y: [size: (100,), type: Vector{Float64}]
# 谨慎使用手动 GC
在 Julia 中,GC.gc()是触发垃圾回收(Garbage Collection, GC)的核心函数。合理使用它可以优化内存管理,但不当使用可能导致性能下降。一般情况下,用户无需手工调用GC.gc()来释放内存。
如果确实需要手工释放内存,可以在释放大对象后手动触发,如下所示:
# 创建大数组
data = rand(10^9) # 8GB
# 处理数据...
result = sum(data)
# 释放引用并触发 GC
data = nothing
GC.gc()
相反,过度调用GC.gc()会显著降低性能:
# 严重影响性能
for i in 1:1000
println("第 $i 次执行...")
# ...
GC.gc() # 不要这样做!
end